MongoDB es una base de datos NoSQL que admite una amplia variedad de orígenes de conjuntos de datos de entrada. Es capaz de almacenar datos en documentos similares a JSON flexibles, lo que significa que los campos o metadatos pueden variar de un documento a otro y la estructura de datos puede cambiar con el tiempo. El modelo de documento facilita el trabajo con los datos al asignarlos a los objetos en el código de la aplicación. MongoDB también se conoce como una base de datos distribuida en su núcleo, por lo que la alta disponibilidad, la escalabilidad horizontal y la distribución geográfica están integradas y son fáciles de usar. Viene con la capacidad de modificar sin problemas los parámetros para el entrenamiento del modelo. Los científicos de datos pueden fusionar fácilmente la estructuración de datos con esta generación de modelos.
¿Qué es el aprendizaje automático?
El aprendizaje automático es la ciencia que hace que las computadoras aprendan y actúen como lo hacen los humanos y mejoren su aprendizaje con el tiempo de manera autónoma. El proceso de aprendizaje comienza con observaciones o datos, como ejemplos, experiencia directa o instrucción, para buscar patrones en los datos y tomar mejores decisiones en el futuro con base en los ejemplos que brindamos. El objetivo principal es permitir que las computadoras aprendan automáticamente sin intervención o asistencia humana y ajusten las acciones en consecuencia.
Un rico modelo de consulta y programación
MongoDB ofrece controladores nativos y conectores certificados para desarrolladores y científicos de datos que crean modelos de aprendizaje automático con datos de MongoDB. PyMongo es una gran biblioteca para incrustar la sintaxis de MongoDB en el código de Python. Podemos importar todas las funciones y métodos de MongoDB para usarlos en nuestro código de aprendizaje automático. Es una gran técnica para obtener funcionalidad multilingüe en un solo código. La ventaja adicional es que puede usar las características esenciales de esos lenguajes de programación para crear una aplicación eficiente.
El lenguaje de consulta MongoDB con índices secundarios enriquecidos permite a los desarrolladores crear aplicaciones que pueden consultar y analizar los datos en múltiples dimensiones. Se puede acceder a los datos mediante claves individuales, rangos, búsqueda de texto, gráficos y consultas geoespaciales a través de agregaciones complejas y trabajos de MapReduce, que devuelven respuestas en milisegundos.
Para paralelizar el procesamiento de datos en un clúster de base de datos distribuida, MongoDB proporciona la canalización de agregación y MapReduce. La canalización de agregación de MongoDB se modela según el concepto de canalizaciones de procesamiento de datos. Los documentos ingresan a una canalización de varias etapas que transforma los documentos en un resultado agregado mediante operaciones nativas ejecutadas dentro de MongoDB. Las etapas de canalización más básicas proporcionan filtros que funcionan como consultas y transformaciones de documentos que modifican la forma del documento de salida. Otras operaciones de canalización proporcionan herramientas para agrupar y clasificar documentos por campos específicos, así como herramientas para agregar el contenido de matrices, incluidas matrices de documentos. Además, las etapas pipseline pueden usar operadores para tareas como calcular el promedio o las desviaciones estándar en colecciones de documentos y manipular cadenas. MongoDB también proporciona operaciones MapReduce nativas dentro de la base de datos, utilizando funciones de JavaScript personalizadas para realizar el mapa y reducir las etapas.
Además de su marco de consulta nativo, MongoDB también ofrece un conector de alto rendimiento para Apache Spark. El conector expone todas las bibliotecas de Spark, incluidas Python, R, Scala y Java. Los datos de MongoDB se materializan como marcos de datos y conjuntos de datos para el análisis con aprendizaje automático, gráficos, transmisión y API de SQL.
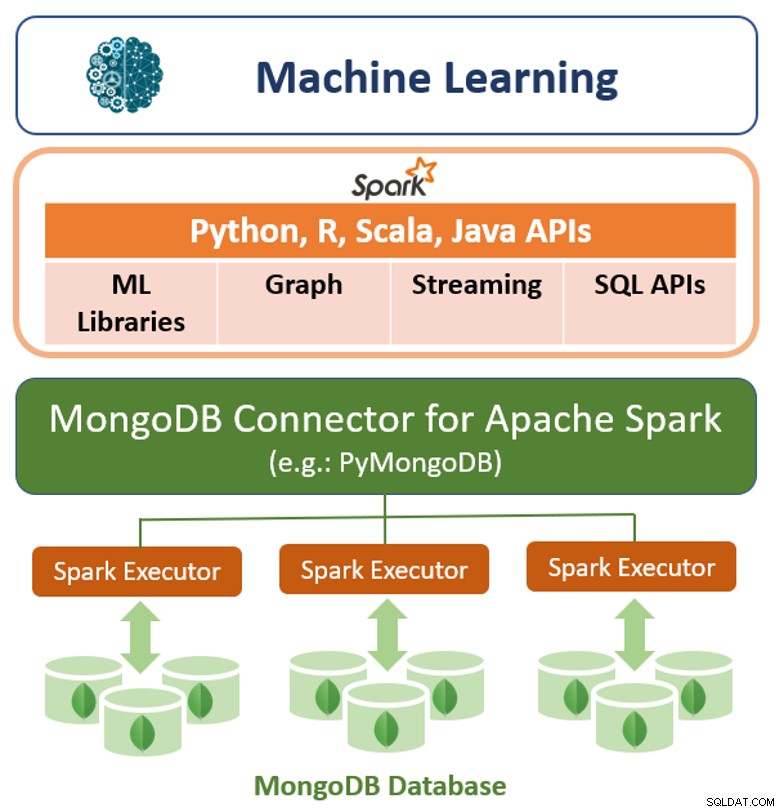
MongoDB Connector para Apache Spark puede aprovechar la canalización de agregación de MongoDB y la secundaria índices para extraer, filtrar y procesar solo el rango de datos que necesita, por ejemplo, analizar todos los clientes ubicados en una geografía específica. Esto es muy diferente de los almacenes de datos NoSQL simples que no admiten índices secundarios ni agregaciones en la base de datos. En estos casos, Spark necesitaría extraer todos los datos en función de una clave principal simple, incluso si solo se requiere un subconjunto de esos datos para el proceso de Spark. Esto significa más gastos generales de procesamiento, más hardware y más tiempo para obtener información para los científicos e ingenieros de datos. Para maximizar el rendimiento en grandes conjuntos de datos distribuidos, MongoDB Connector para Apache Spark puede ubicar conjuntos de datos distribuidos resistentes (RDD) junto con el nodo MongoDB de origen, lo que minimiza el movimiento de datos en el clúster y reduce la latencia.
Rendimiento, escalabilidad y redundancia
El tiempo de capacitación del modelo se puede reducir construyendo la plataforma de aprendizaje automático sobre una capa de base de datos escalable y de alto rendimiento. MongoDB ofrece una serie de innovaciones para maximizar el rendimiento y minimizar la latencia de las cargas de trabajo de aprendizaje automático:
- WiredTiger es conocido como el motor de almacenamiento predeterminado para MongoDB, desarrollado por los arquitectos de Berkeley DB, el software de administración de datos integrado más implementado en el mundo. WiredTiger escala en arquitecturas modernas de múltiples núcleos. Utilizando una variedad de técnicas de programación, como indicadores de riesgo, algoritmos sin bloqueo, bloqueo rápido y paso de mensajes, WiredTiger maximiza el trabajo computacional por núcleo de CPU y ciclo de reloj. Para minimizar la sobrecarga y la E/S en el disco, WiredTiger utiliza formatos de archivo compactos y compresión de almacenamiento.
- Para las aplicaciones de aprendizaje automático más sensibles a la latencia, MongoDB se puede configurar con el motor de almacenamiento en memoria. Basado en WiredTiger, este motor de almacenamiento brinda a los usuarios los beneficios de la computación en memoria, sin sacrificar la rica flexibilidad de consultas, el análisis en tiempo real y la capacidad escalable que ofrecen las bases de datos convencionales basadas en disco.
- Para paralelizar el entrenamiento del modelo y escalar los conjuntos de datos de entrada más allá de un solo nodo, MongoDB utiliza una técnica llamada fragmentación, que distribuye el procesamiento y los datos entre grupos de hardware básico. La fragmentación de MongoDB es totalmente elástica y reequilibra automáticamente los datos en todo el clúster a medida que crece el conjunto de datos de entrada o se agregan y eliminan nodos.
- Dentro de un clúster de MongoDB, los datos de cada fragmento se distribuyen automáticamente a múltiples réplicas alojadas en nodos separados. Los conjuntos de réplicas de MongoDB proporcionan redundancia para recuperar datos de entrenamiento en caso de falla, lo que reduce la sobrecarga de los puntos de control.
Coherencia ajustable de MongoDB
MongoDB es muy coherente de forma predeterminada, lo que permite que las aplicaciones de aprendizaje automático lean inmediatamente lo que se ha escrito en la base de datos, evitando así la complejidad del desarrollador impuesta por los sistemas finalmente coherentes. La consistencia sólida proporcionará los resultados más precisos para los algoritmos de aprendizaje automático; sin embargo, en algunos escenarios es aceptable intercambiar la consistencia frente a objetivos de rendimiento específicos mediante la distribución de consultas en un grupo de miembros del conjunto de réplicas secundarias de MongoDB.
Modelo de datos flexible en MongoDB
El modelo de datos de documentos de MongoDB facilita a los desarrolladores y científicos de datos almacenar y agregar datos de cualquier forma de estructura dentro de la base de datos, sin renunciar a reglas de validación sofisticadas para controlar la calidad de los datos. El esquema se puede modificar de forma dinámica sin que la aplicación o la base de datos dejen de funcionar como resultado de las costosas modificaciones o rediseños del esquema en los que incurren los sistemas de bases de datos relacionales.
Guardar modelos en una base de datos y cargarlos, usando python, también es un método fácil y muy requerido. Elegir MongoDB también es una ventaja, ya que es una base de datos de documentos de código abierto y también una base de datos NoSQL líder. MongoDB también sirve como conector para el marco distribuido de Apache Spark.
Naturaleza dinámica de MongoDB
La naturaleza dinámica de MongoDB permite su uso en tareas de manipulación de bases de datos en el desarrollo de aplicaciones de aprendizaje automático. Es una manera muy eficiente y fácil de llevar a cabo un análisis de conjuntos de datos y bases de datos. El resultado del análisis se puede utilizar para entrenar modelos de aprendizaje automático. Se ha recomendado que los analistas de datos y los programadores de Machine Learning dominen MongoDB y lo apliquen en muchas aplicaciones diferentes. El marco de agregación de MongoDB se utiliza para el flujo de trabajo de ciencia de datos para realizar análisis de datos para numerosas aplicaciones.
Conclusión
MongoDB ofrece varias capacidades diferentes, como:modelo de datos flexible, programación enriquecida, modelo de datos, modelo de consulta y su consistencia ajustable que hace que el entrenamiento y el uso de algoritmos de aprendizaje automático sean mucho más fáciles que con las bases de datos relacionales tradicionales. Ejecutar MongoDB como la base de datos backend permitirá almacenar y enriquecer los datos de aprendizaje automático, lo que permite la persistencia y una mayor eficiencia.



