Ya que estás usando spring. Puedes usar MultipartFile para obtener el archivo en su controlador y luego use Binary de org.bson para almacenar el archivo en MongoDB, si el tamaño de su imagen es <16 MB (si el tamaño de la imagen es> 16 MB, puede usar GridFs
).
Debe agregar solo una dependencia a su proyecto:spring-data-mongoDB
Tomemos un ejemplo de una colección de usuarios que se ve así:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Aquí puedes ver Binary image que representa su archivo de imagen.
Ahora cree un repositorio para esta colección de usuarios usando MongoRepository
public interface UserRepository extends MongoRepository<User, String>{
}
Cree un controlador para fines de demostración. Utilice el archivo @RequestParam MultipartFile file para obtener el archivo en su controlador, obtenga los bytes del archivo y configúrelo en el objeto de usuario user.setImage(new Binary(file.getBytes())); el ejemplo completo está abajo:
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Inicie el servidor y llegue al punto final como se muestra en la siguiente captura de pantalla del cartero
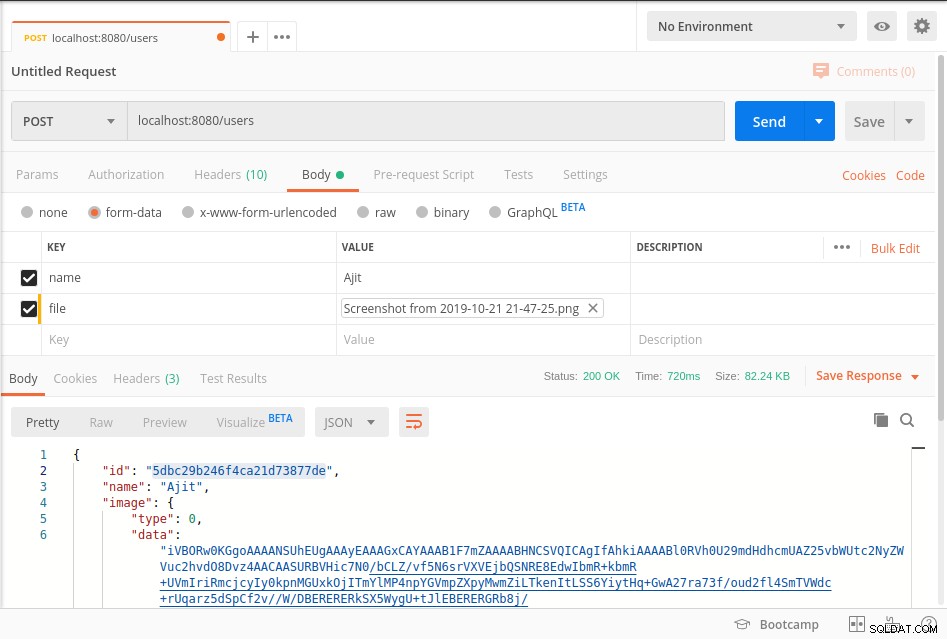
Sus datos se almacenan en mongoDb en BinData formato y para obtener los datos de la base de datos, consulte getImage método del código anterior.
EDITAR:
El autor de la pregunta está usando tess4j biblioteca para extraer texto de la imagen y doOCR es un método en esta biblioteca. He seguido estos pasos para extraer texto de la imagen en mi aplicación Spring Boot.
-
Instalar
tesseract-ocren su sistema:sudo apt-get install tesseract-ocr -
Descargar
eng.traineddatadatos de entrenamiento de https://github.com/tesseract-ocr/tessdata y muévalo a la carpeta raíz del proyecto. -
Agregue la siguiente dependencia a su proyecto:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Agregue el siguiente código al proyecto existente:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}



