El mejor escenario es que, en caso de falla de la base de datos, tenga un buen Plan de Recuperación de Desastres (DRP) y un entorno de alta disponibilidad con un proceso de conmutación por error automático, pero... ¿qué sucede si falla por alguna razón inesperada? ¿Qué sucede si necesita realizar una conmutación por error manual? En este blog, compartiremos algunas recomendaciones a seguir en caso de que necesite una conmutación por error de su base de datos.
Comprobaciones de verificación
Antes de realizar cualquier cambio, debe verificar algunas cosas básicas para evitar nuevos problemas después del proceso de conmutación por error.
Estado de replicación
Es posible que, en el momento de la falla, el nodo esclavo no esté actualizado debido a una falla en la red, una carga alta u otro problema, por lo que debe asegurarse de que su el esclavo tiene toda (o casi toda) la información. Si tiene más de un nodo esclavo, también debe verificar cuál es el nodo más avanzado y elegirlo para la conmutación por error.
por ejemplo:vamos a comprobar el estado de replicación en un servidor MariaDB.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)En el caso de PostgreSQL, es un poco diferente ya que necesita verificar el estado de los WAL y comparar los aplicados con los obtenidos.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Credenciales
Antes de ejecutar la conmutación por error, debe verificar si su aplicación/usuarios podrán acceder a su nuevo maestro con las credenciales actuales. Si no está replicando los usuarios de su base de datos, es posible que se hayan cambiado las credenciales, por lo que deberá actualizarlas en los nodos esclavos antes de cualquier cambio.
por ejemplo:puede consultar la tabla de usuarios en la base de datos mysql para comprobar las credenciales de usuario en un servidor MariaDB/MySQL:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)En el caso de PostgreSQL, puede usar el comando '\du' para conocer los roles, y también debe verificar el archivo de configuración pg_hba.conf para administrar el acceso de los usuarios (no las credenciales). Entonces:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}Y pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustAcceso a la red/cortafuegos
Las credenciales no son el único problema posible para acceder a su nuevo maestro. Si el nodo está en otro centro de datos, o si tiene un firewall local para filtrar el tráfico, debe verificar si tiene permiso para acceder o incluso si tiene la ruta de red para llegar al nuevo nodo maestro.
por ejemplo:iptables. Permitamos el tráfico de la red 167.124.57.0/24 y verifiquemos las reglas actuales después de agregarlo:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationpor ejemplo:rutas. Supongamos que su nuevo nodo maestro está en la red 10.0.0.0/24, su servidor de aplicaciones está en 192.168.100.0/24 y puede llegar a la red remota usando 192.168.100.100, entonces en su servidor de aplicaciones, agregue la ruta correspondiente:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Puntos de acción
Después de verificar todos los puntos mencionados, debería estar listo para realizar las acciones para la conmutación por error de su base de datos.
Nueva dirección IP
Como promoverá un nodo esclavo, la dirección IP maestra cambiará, por lo que deberá cambiarla en su aplicación o acceso de cliente.
Usar un Load Balancer es una excelente manera de evitar este problema/cambio. Después del proceso de conmutación por error, Load Balancer detectará que el maestro anterior está fuera de línea y (según la configuración) enviará el tráfico al nuevo para que lo escriba, por lo que no es necesario que cambie nada en su aplicación.
p. ej.:Veamos un ejemplo de configuración de HAProxy:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkEn este caso, si un nodo está inactivo, HAProxy no enviará tráfico allí y enviará el tráfico solo al nodo disponible.
Reconfigurar los nodos esclavos
Si tiene más de un nodo esclavo, luego de promocionar uno de ellos, debe reconfigurar el resto de los esclavos para conectarse al nuevo maestro. Esta podría ser una tarea que requiere mucho tiempo, según la cantidad de nodos.
Verificar y configurar las copias de seguridad
Después de tener todo en su lugar (nuevo maestro promovido, esclavos reconfigurados, aplicación escribiendo en el nuevo maestro), es importante tomar las medidas necesarias para evitar un nuevo problema, por lo que las copias de seguridad son imprescindibles en Este paso. Lo más probable es que tuviera una política de copias de seguridad ejecutándose antes del incidente (si no es así, debe tenerla segura), por lo que debe verificar si las copias de seguridad aún se están ejecutando o lo harán en la nueva topología. Es posible que tuviera las copias de seguridad ejecutándose en el antiguo maestro o utilizando el nodo esclavo que ahora es el maestro, por lo que debe verificarlo para asegurarse de que su política de copias de seguridad seguirá funcionando después de los cambios.
Supervisión de la base de datos
Cuando realiza un proceso de conmutación por error, la supervisión es imprescindible antes, durante y después del proceso. Con esto, puede prevenir un problema antes de que empeore, detectar un problema inesperado durante la conmutación por error o incluso saber si algo sale mal después. Por ejemplo, debe monitorear si su aplicación puede acceder a su nuevo maestro verificando la cantidad de conexiones activas.
Métricas clave para monitorear
Veamos algunas de las métricas más importantes a tener en cuenta:
- Retraso de replicación
- Estado de replicación
- Número de conexiones
- Errores/uso de la red
- Carga del servidor (CPU, Memoria, Disco)
- Base de datos y registros del sistema
Restaurar
Por supuesto, si algo salió mal, debe poder retroceder. Bloquear el tráfico al nodo anterior y mantenerlo lo más aislado posible podría ser una buena estrategia para esto, por lo que, en caso de que necesite revertir, tendrá el nodo anterior disponible. Si la reversión es después de algunos minutos, dependiendo del tráfico, probablemente necesitará insertar los datos de estos minutos en el maestro anterior, así que asegúrese de tener también su nodo maestro temporal disponible y aislado para tomar esta información y aplicarla nuevamente. .
Automatizar el proceso de conmutación por error con ClusterControl
Al ver todas estas tareas necesarias para realizar una conmutación por error, lo más probable es que desee automatizarla y evitar todo este trabajo manual. Para ello, puede aprovechar algunas de las funciones que ClusterControl puede ofrecerle para diferentes tecnologías de base de datos, como autorrecuperación, copias de seguridad, administración de usuarios, monitoreo, entre otras funciones, todo desde el mismo sistema.
Con ClusterControl puede verificar el estado de la replicación y su retraso, crear o modificar credenciales, conocer el estado de la red y del host, y aún más verificaciones.
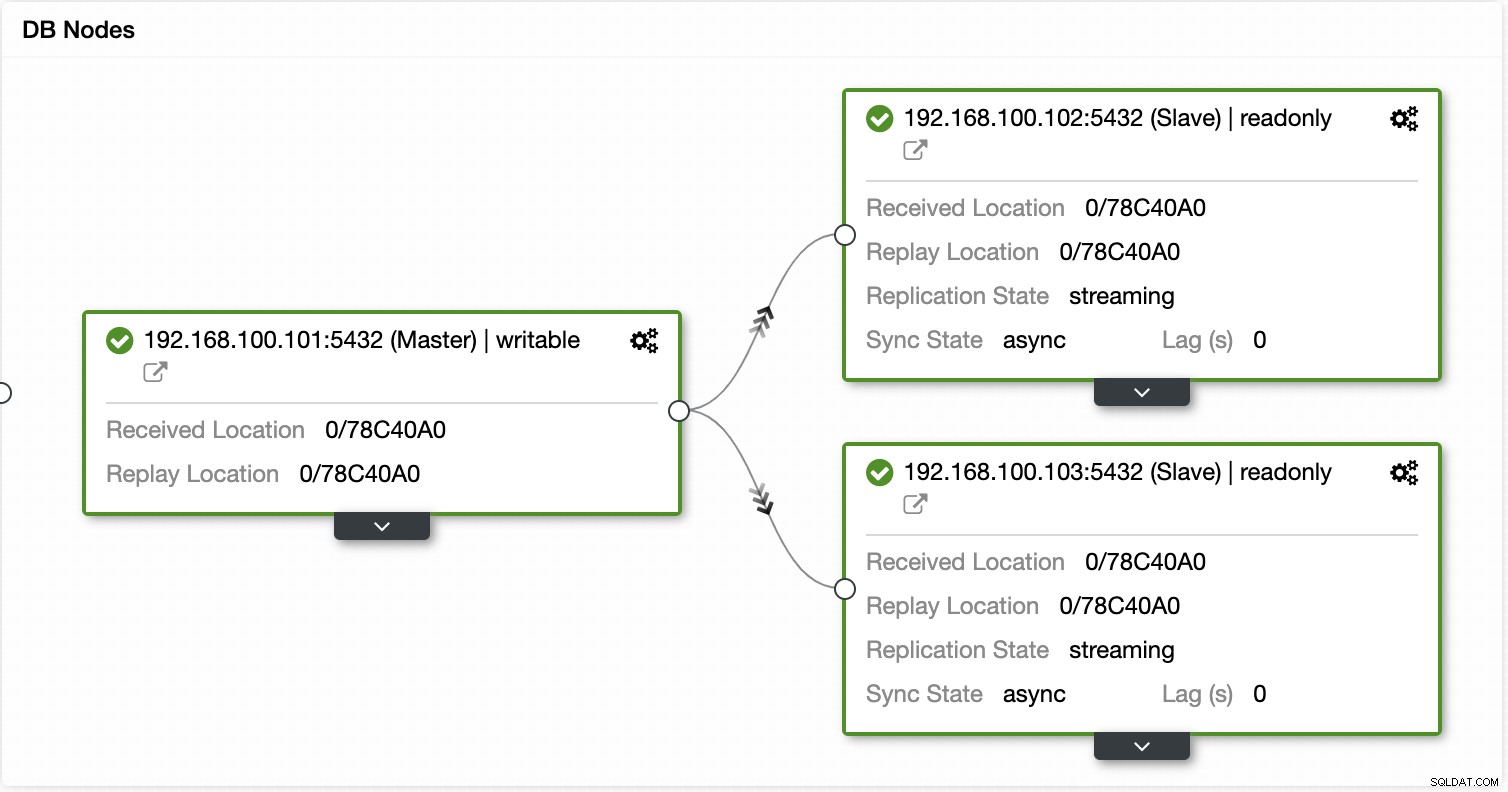
Usando ClusterControl también puede realizar diferentes acciones de clúster y nodo, como promover esclavo , reinicie la base de datos y el servidor, agregue o elimine nodos de la base de datos, agregue o elimine nodos del balanceador de carga, reconstruya un esclavo de replicación y más.
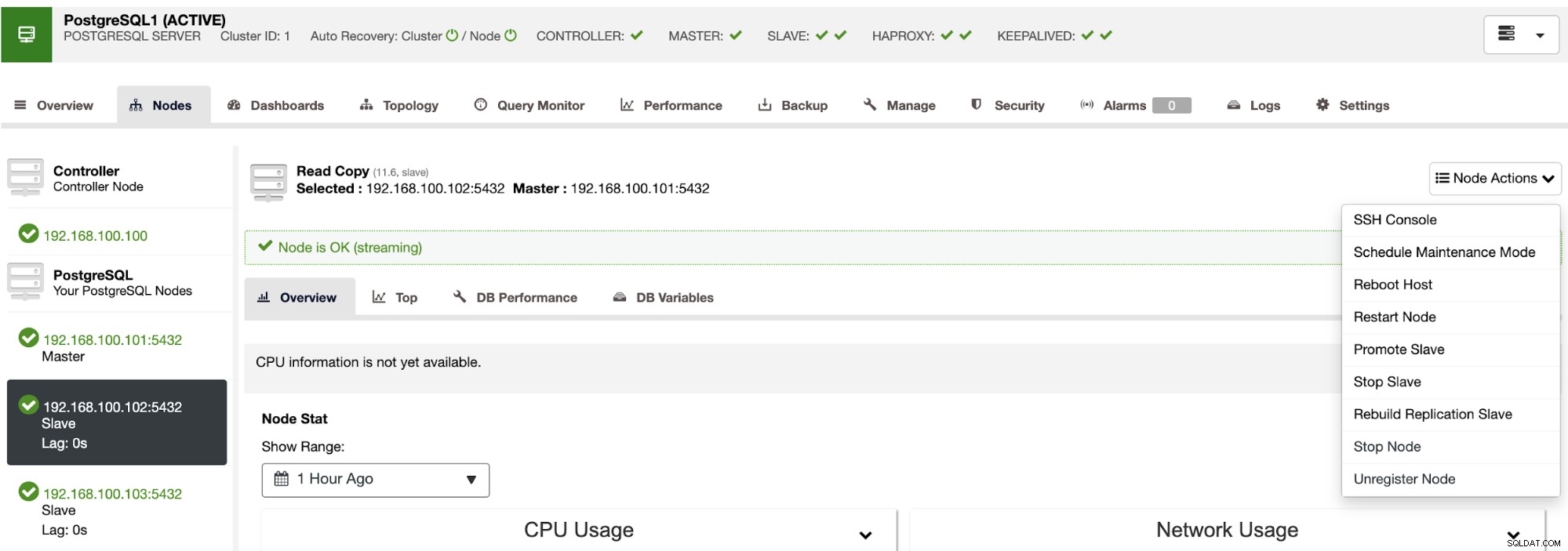
Con estas acciones, también puede revertir su conmutación por error si es necesario mediante la reconstrucción y promoción el maestro anterior.
ClusterControl cuenta con servicios de monitoreo y alertas que te ayudan a saber qué está pasando o incluso si algo pasó anteriormente.
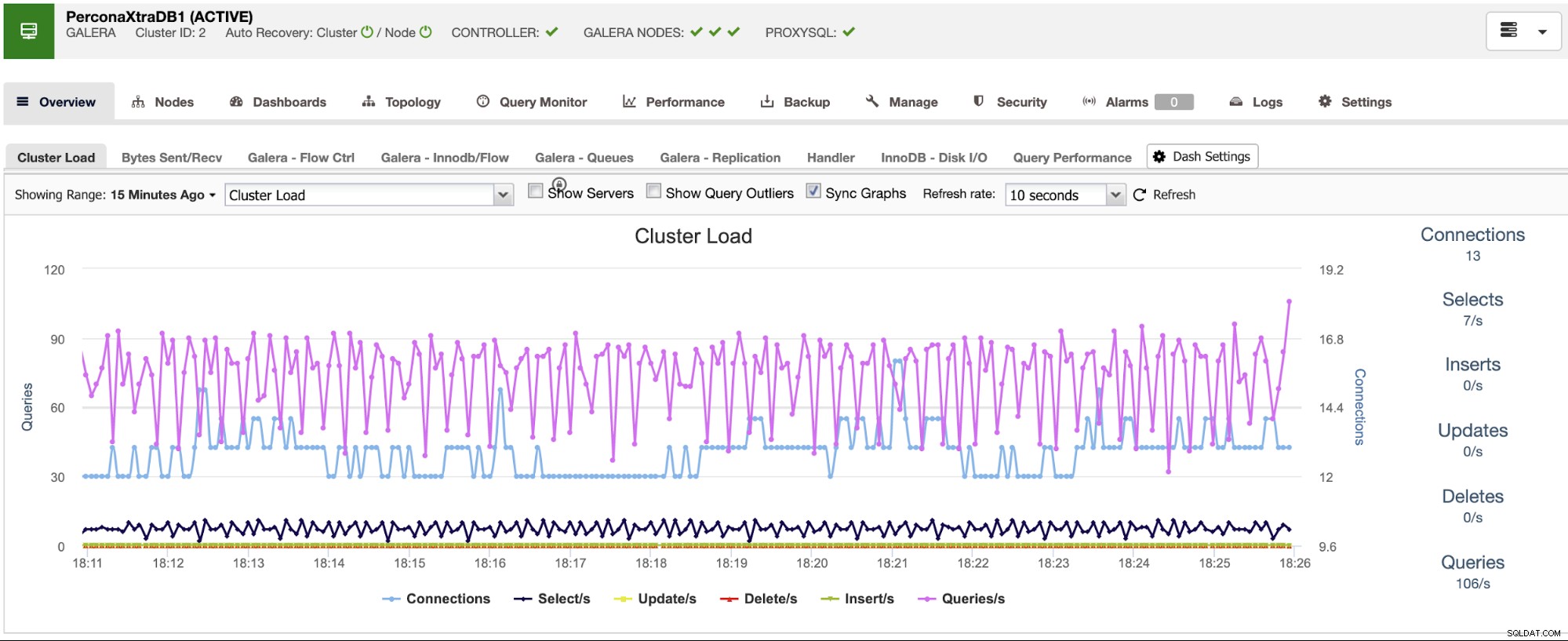
También puede usar la sección del tablero para tener una vista más fácil de usar sobre el estado de sus sistemas.
Conclusión
En caso de que falle la base de datos maestra, querrá tener toda la información disponible para tomar las medidas necesarias lo antes posible. Tener un buen DRP es la clave para mantener su sistema funcionando todo (o casi todo) el tiempo. Este DRP debe incluir un proceso de conmutación por error bien documentado para tener un RTO (objetivo de tiempo de recuperación) aceptable para la empresa.