Introducción
A menudo se les dice a los desarrolladores que usen procedimientos almacenados para evitar las llamadas consultas ad hoc lo que puede resultar en una hinchazón innecesaria del caché del plan. Verá, cuando el código SQL recurrente se escribe de manera inconsistente o cuando hay un código que genera SQL dinámico sobre la marcha, SQL Server tiende a crear un plan de ejecución para cada ejecución individual. Esto puede disminuir el rendimiento general en:
Exigir una fase de compilación para cada ejecución de código.
Inflar la memoria caché del plan con demasiados identificadores de planes que no se pueden reutilizar.
Optimizar para cargas de trabajo ad hoc
Una forma en que este problema se manejó en el pasado fue optimizando la instancia para cargas de trabajo ad hoc. Hacer esto solo puede ser útil si la mayoría de las bases de datos o las bases de datos más importantes de la instancia ejecutan predominantemente Ad Hoc SQL.
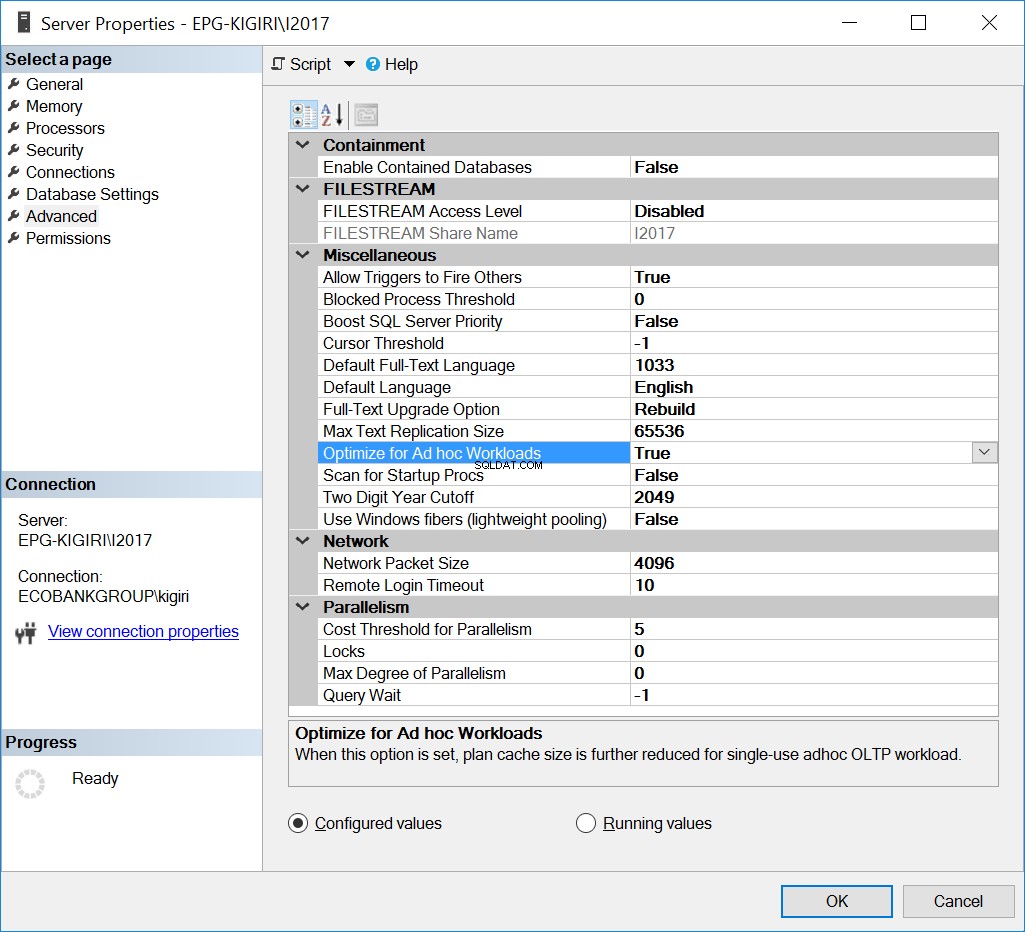
Fig. 1 Optimizar para cargas de trabajo ad hoc
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
Esencialmente, esta opción le dice a SQL Server que guarde una versión parcial del plan conocida como el resguardo del plan compilado. El talón ocupa mucho menos espacio que todo el plan.
Como alternativa a este método, algunas personas abordan el problema de manera bastante brutal y vacían el caché del plan de vez en cuando. O, de una manera más cuidadosa, vacíe los "planes de un solo uso" utilizando DBCC FREESYSTEMCACHE. Vaciar todo el caché del plan tiene sus desventajas, como ya sabrá.
Uso de parámetros y procedimientos almacenados
Usando procedimientos almacenados, uno puede eliminar virtualmente el problema causado por Ad Hoc SQL. Un procedimiento almacenado se compila solo una vez y el mismo plan se reutiliza para ejecuciones posteriores de consultas SQL iguales o similares. Cuando los procedimientos almacenados se utilizan para implementar la lógica de negocios, la diferencia clave en las consultas SQL que eventualmente ejecutará SQL Server radica en los parámetros que se pasan en el momento de la ejecución. Dado que el plan ya está implementado y listo para usar, SQL Server usará el mismo plan sin importar qué parámetro se pase.
Datos sesgados
En ciertos escenarios, los datos que manejamos no se distribuyen uniformemente. Podemos demostrar esto:primero, necesitaremos crear una tabla:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); Nuestra tabla contiene datos de miembros del club de diferentes países. Un gran número de miembros del club son de Ghana, mientras que otras dos naciones tienen diez y dos miembros respectivamente. Para mantenerme enfocado en la agenda y en aras de la simplicidad, solo usé tres países y el mismo nombre para los miembros que provienen del mismo país. Además, agregué un índice agrupado en la columna ID y un índice no agrupado en la columna CountryCode para demostrar el efecto de diferentes planes de ejecución para diferentes valores.
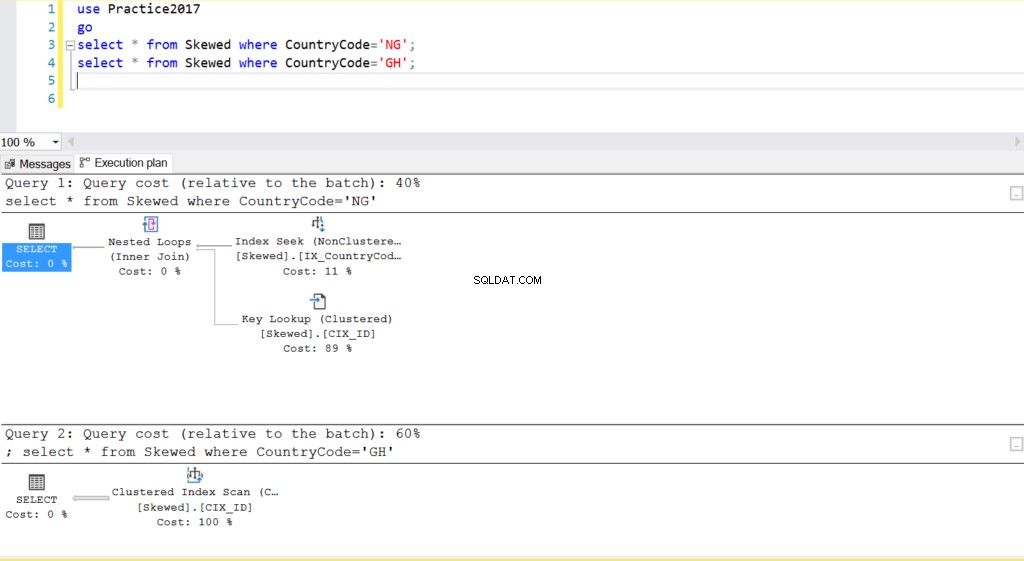
Fig. 2 Planes de ejecución para dos consultas
Cuando consultamos la tabla para registros donde CountryCode es NG y GH, encontramos que SQL Server usa dos planes de ejecución diferentes en estos casos. Esto sucede porque el número esperado de filas para CountryCode='NG' es 10, mientras que para CountryCode='GH' es 10000. SQL Server determina el plan de ejecución preferible en función de las estadísticas de la tabla. Si la cantidad esperada de filas es alta en comparación con la cantidad total de filas de la tabla, SQL Server decide que es mejor simplemente realizar una exploración completa de la tabla en lugar de hacer referencia a un índice. Con un número estimado de filas mucho menor, el índice se vuelve útil.
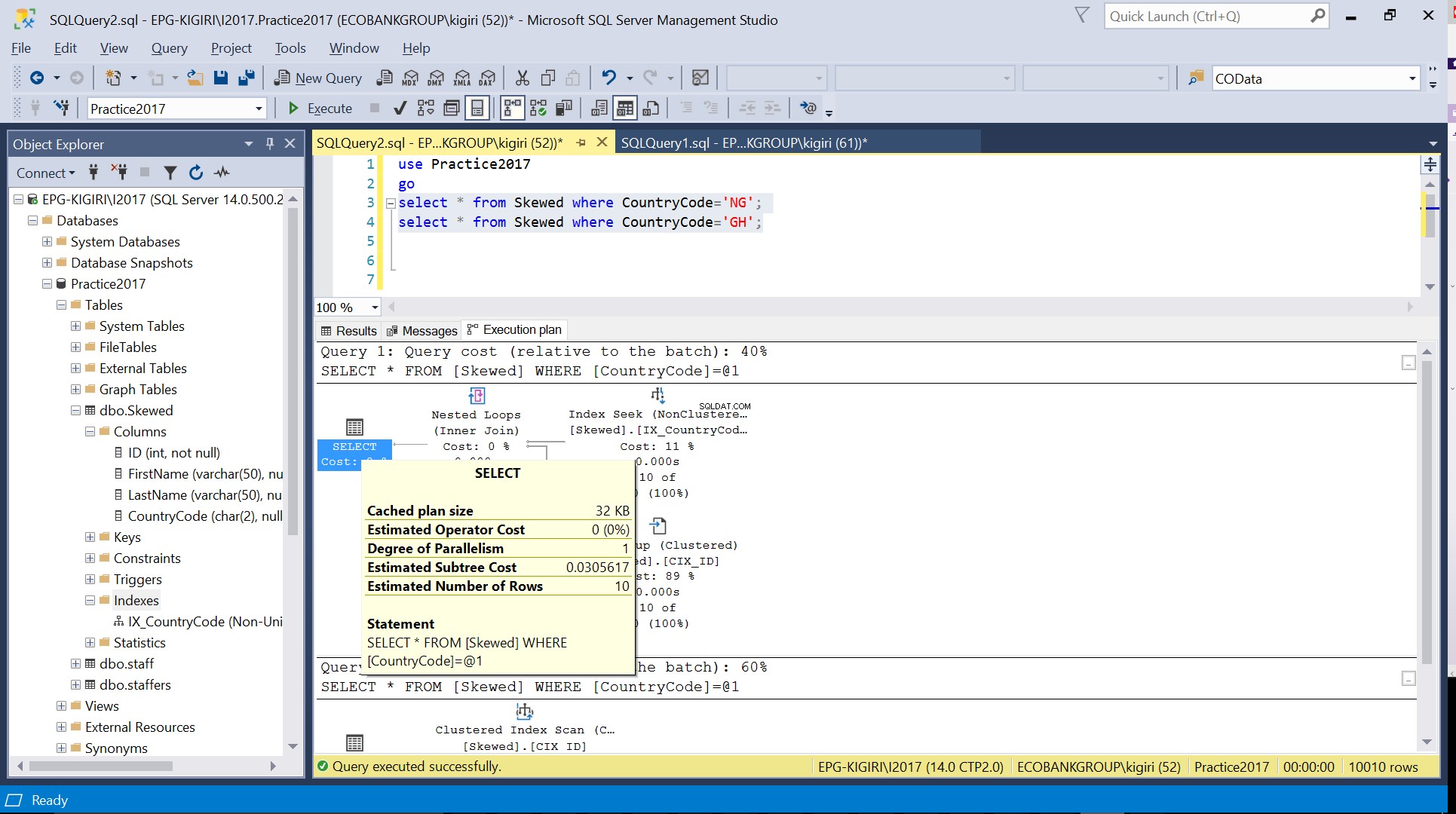
Fig. 3 Número estimado de filas para CountryCode=’NG’
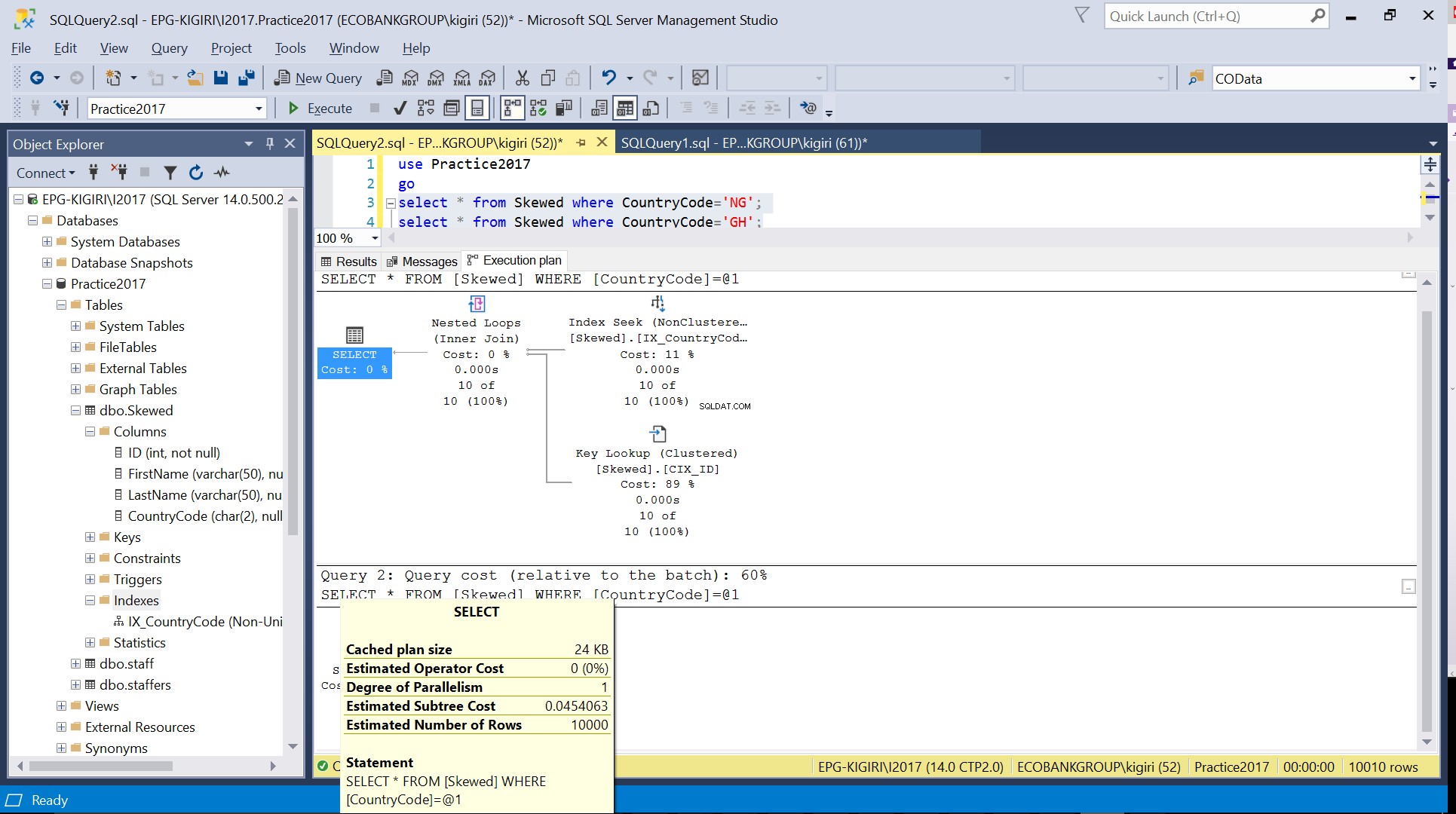
Fig. 4 Número estimado de filas para CountryCode='GH'
Ingresar procedimientos almacenados
Podemos crear un procedimiento almacenado para obtener los registros que queremos usando la misma consulta. La única diferencia esta vez es que pasamos CountryCode como parámetro (vea el Listado 3). Al hacer esto, descubrimos que el plan de ejecución es el mismo sin importar qué parámetro pasemos. El plan de ejecución que se utilizará está determinado por el plan de ejecución devuelto la primera vez que se invoca el procedimiento almacenado. Por ejemplo, si primero ejecutamos el procedimiento con CountryCode='GH', utilizará un escaneo completo de la tabla a partir de ese momento. Si luego borramos el caché del procedimiento y ejecutamos el procedimiento con CountryCode='NG' primero, utilizará escaneos basados en índices en el futuro.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
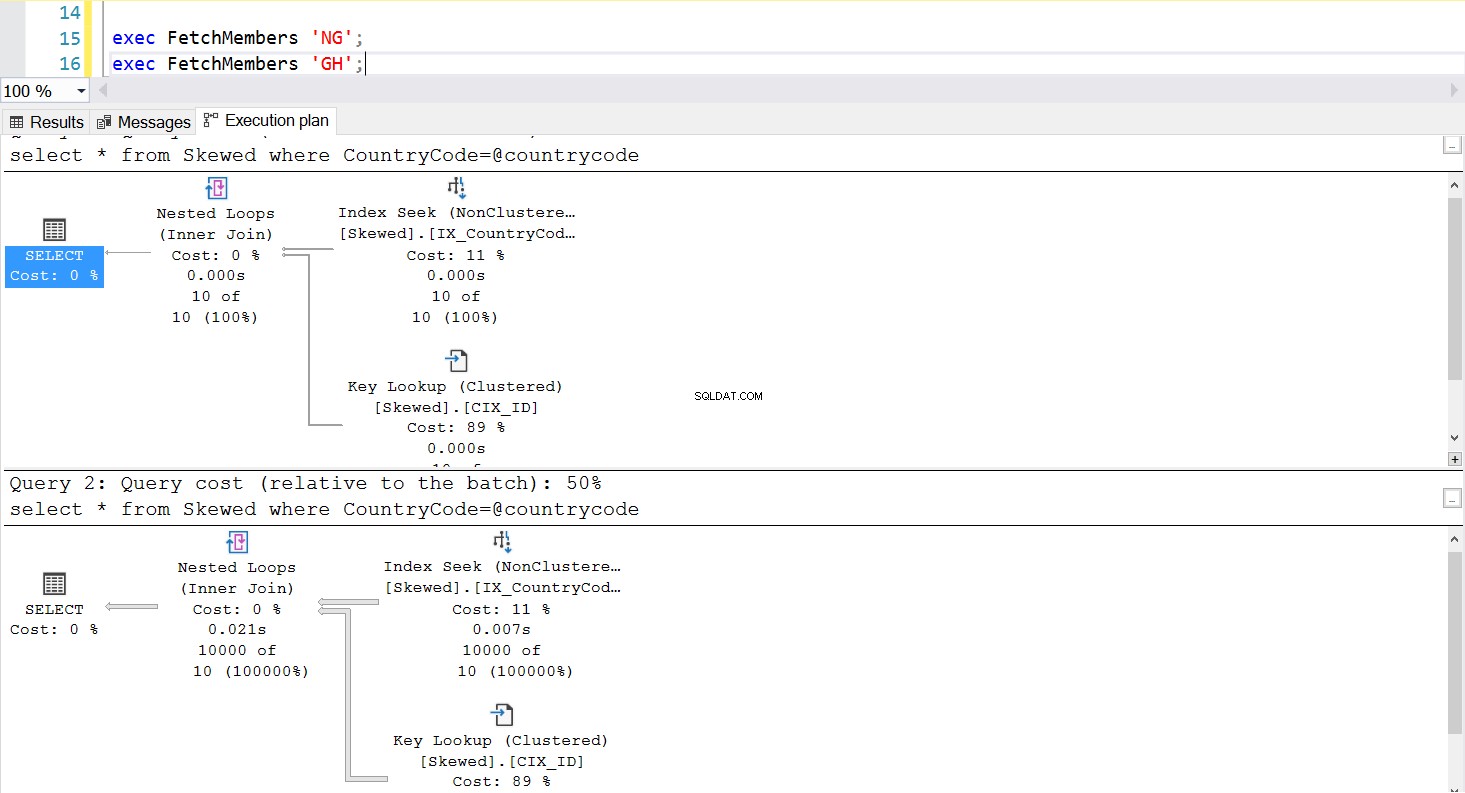
Fig. 5 Plan de ejecución de búsqueda de índice cuando se usa primero 'NG'
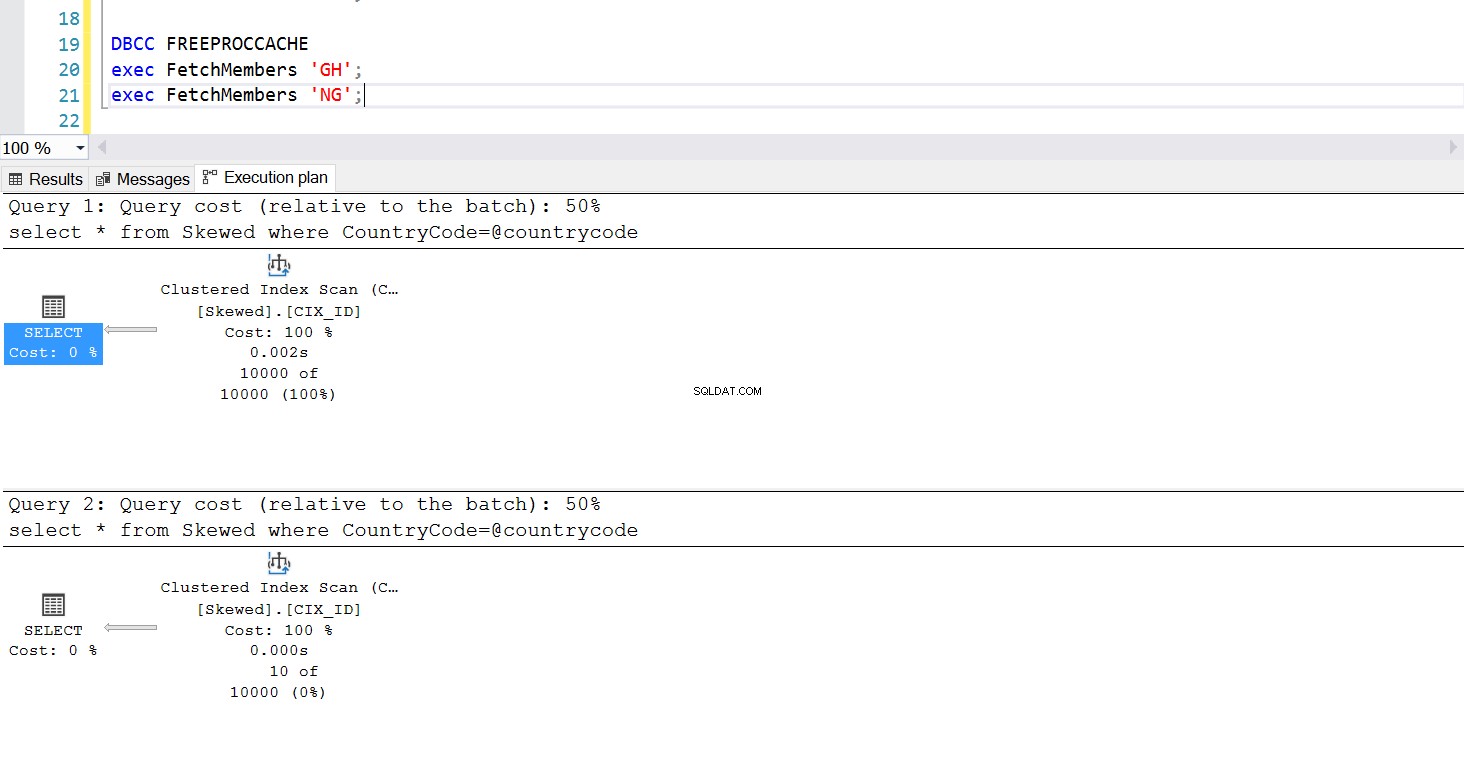
Fig. 6 Plan de ejecución de escaneo de índice agrupado cuando se usa primero 'GH'
La ejecución del procedimiento almacenado se está comportando según lo diseñado:el plan de ejecución requerido se usa de manera consistente. Sin embargo, esto puede ser un problema porque un plan de ejecución no es adecuado para todas las consultas si los datos están sesgados. Usar un índice para recuperar una colección de filas casi tan grande como la tabla completa no es eficiente; tampoco lo es usar un escaneo completo para recuperar solo una pequeña cantidad de filas. Este es el problema de rastreo de parámetros.
Posibles soluciones
Una forma común de manejar el problema de detección de parámetros es invocar deliberadamente la recompilación cada vez que se ejecuta el procedimiento almacenado. Esto es mucho mejor que vaciar la caché del plan, excepto si desea vaciar la caché de esta consulta SQL específica, lo cual es completamente posible. Eche un vistazo a una versión actualizada del procedimiento almacenado. Esta vez, usa OPCIÓN (RECOMPILAR) para manejar el problema. La figura 6 nos muestra que, cada vez que se ejecuta el nuevo procedimiento almacenado, utiliza un plan apropiado para el parámetro que estamos pasando.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
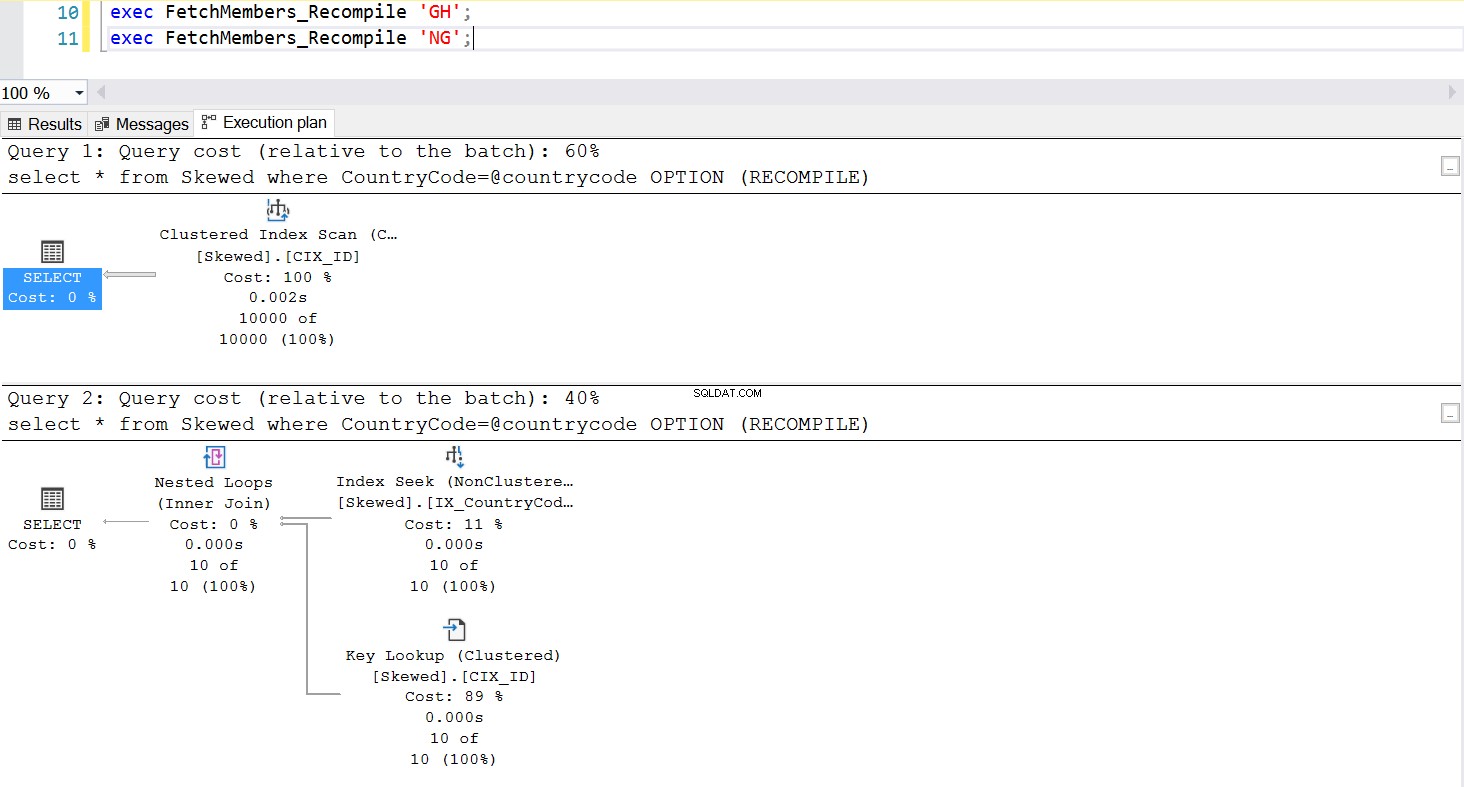
Fig. 7 Comportamiento del procedimiento almacenado con OPTION (RECOMPILE)
Conclusión
En este artículo, hemos analizado cómo los planes de ejecución consistentes para los procedimientos almacenados pueden convertirse en un problema cuando los datos con los que tratamos están sesgados. También hemos demostrado esto en la práctica y hemos aprendido acerca de una solución común al problema. Me atrevo a decir que este conocimiento es invaluable para los desarrolladores que usan SQL Server. Hay una serie de otras soluciones a este problema:Brent Ozar profundizó en el tema y destacó algunos detalles y soluciones más profundos en SQLDay Polonia 2017. He enumerado el enlace correspondiente en la sección de referencia.
Referencias
Planificación de caché y optimización para cargas de trabajo Adhoc
Identificación y solución de problemas de detección de parámetros