¿SQL DISTINCT es bueno (o malo) cuando necesita eliminar duplicados en los resultados?
Algunos dicen que es bueno y agregan DISTINCT cuando aparecen duplicados. Algunos dicen que es malo y sugieren usar GROUP BY sin una función agregada. Otros dicen que DISTINCT y GROUP BY son lo mismo cuando necesitas eliminar duplicados.
Esta publicación profundizará en los detalles para obtener las respuestas correctas. Entonces, eventualmente, utilizará la mejor palabra clave según la necesidad. Comencemos.
Un breve recordatorio sobre los conceptos básicos de la instrucción SQL SELECT DISTINCT
Antes de profundizar más, recordemos qué es la instrucción SQL SELECT DISTINCT. Una tabla de base de datos puede incluir valores duplicados por muchas razones, pero es posible que deseemos obtener solo los valores únicos. En este caso, SELECT DISTINCT es útil. Esta cláusula DISTINCT hace que la declaración SELECT solo obtenga registros únicos.
La sintaxis de la declaración es simple:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Aquí, la condición WHERE es opcional.
La declaración se aplica tanto a una sola columna como a varias columnas. La sintaxis de esta instrucción aplicada a varias columnas es la siguiente:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Tenga en cuenta que el escenario de consultar varias columnas sugerirá el uso de la combinación de valores en todas las columnas definidas por la declaración para determinar la unicidad.
Y ahora, exploremos el uso práctico y las trampas de aplicar la instrucción SELECT DISTINCT.
Cómo funciona SQL DISTINCT para eliminar duplicados
Obtener respuestas no es tan difícil de encontrar. SQL Server nos proporcionó planes de ejecución para ver cómo se procesará una consulta para darnos los resultados necesarios.
La siguiente sección se centra en el plan de ejecución cuando se usa DISTINCT. Tienes que pulsar Ctrl-M en SQL Server Management Studio antes de ejecutar las consultas a continuación. O haga clic en Incluir plan de ejecución real de la barra de herramientas.
Consultar Planes en SQL DISTINCT
Comencemos comparando 2 consultas. La primera no usará DISTINCT y la segunda consulta sí.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Aquí está el plan de ejecución:
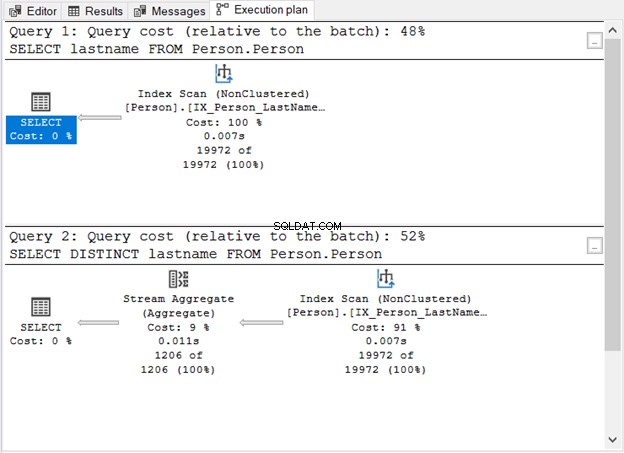
¿Qué nos mostró la Figura 1?
- Sin la palabra clave DISTINCT, la consulta es simple.
- Aparece un paso adicional después de agregar DISTINCT.
- El costo de consulta de usar DISTINCT es más alto que sin él.
- Ambos tienen operadores Index Scan. Esto es comprensible porque no hay una cláusula WHERE específica en nuestras consultas.
- El paso adicional, el operador Stream Aggregate, se utiliza para eliminar los duplicados.
El número de lecturas lógicas es el mismo (107) si marca ESTADÍSTICAS IO. Sin embargo, el número de registros es muy diferente. La primera consulta devuelve 19.972 filas. Mientras tanto, la segunda consulta devuelve 1206 filas.
Por lo tanto, no puede agregar DISTINCT en cualquier momento que desee. Pero si necesita valores únicos, esta es una sobrecarga necesaria.
Hay operadores que se utilizan para generar valores únicos. Examinemos algunos de ellos.
AGREGADO DE FLUJO
Este es el operador que vio en la Figura 1. Acepta una sola entrada y genera un resultado agregado. En la Figura 1, la entrada proviene del operador Index Scan. Sin embargo, Stream Aggregate necesita una entrada ordenada.
Como puede ver en la Figura 1, utiliza el IX_Person_LastName_FirstName_MiddleName , un índice no único de nombres. Dado que el índice ya ordena los registros por nombre, Stream Aggregate acepta la entrada. Sin el índice, el optimizador de consultas puede optar por utilizar un operador Ordenar adicional en el plan. Y eso será más caro. O bien, puede usar un Hash Match.
COINCIDIR HASH (AGREGADO)
Otro operador utilizado por DISTINCT es Hash Match. Este operador se usa para uniones y agregaciones.
Cuando se usa DISTINCT, Hash Match agrega los resultados para producir valores únicos. Aquí hay un ejemplo.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
Y aquí está el plan de ejecución:
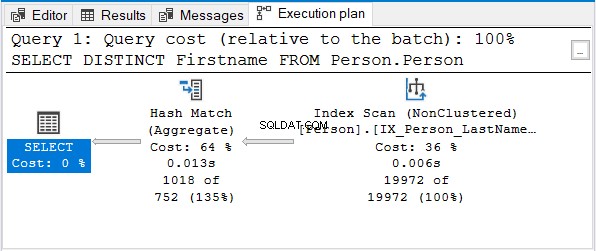
Pero, ¿por qué no Stream Aggregate?
Observe que se utiliza el mismo índice de nombres. Ese índice se ordena con Lastname primero. Entonces, un Nombre solo la consulta se desordenará.
Hash Match (agregado) es la siguiente opción lógica para eliminar los duplicados.
COINCIDENCIA HASH (FLUJO DISTINTO)
El Hash Match (Agregado) es un operador de bloqueo. Por lo tanto, no producirá la salida que ha procesado en todo el flujo de entrada. Si restringimos la cantidad de filas (como usar TOP con DISTINCT), producirá una salida única tan pronto como esas filas estén disponibles. De eso se trata Hash Match (Flow Distinct).
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
La consulta usa TOP 100 junto con DISTINCT. Aquí está el plan de ejecución:
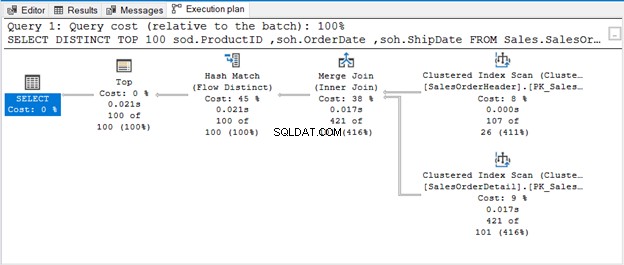
CUANDO NO HAY OPERADOR PARA ELIMINAR DUPLICADOS
Sí. Esto puede suceder. Considere el siguiente ejemplo.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Luego, verifique el plan de ejecución:
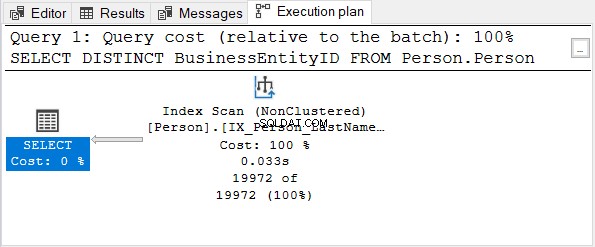
El ID de entidad comercial columna es la clave principal. Dado que esa columna ya es única, no sirve de nada aplicar DISTINCT. Intente eliminar DISTINCT de la instrucción SELECT:el plan de ejecución es el mismo que en la Figura 4.
Lo mismo ocurre cuando se usa DISTINCT en columnas con un índice único.
SQL DISTINCT funciona en TODAS las columnas de la lista SELECT
Hasta ahora, solo hemos usado 1 columna en nuestros ejemplos. Sin embargo, DISTINCT funciona en TODAS las columnas que especifique en la lista SELECCIONAR.
Aquí hay un ejemplo. Esta consulta se asegurará de que los valores de las 3 columnas sean únicos.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Observe las primeras filas del conjunto de resultados en la Figura 5.
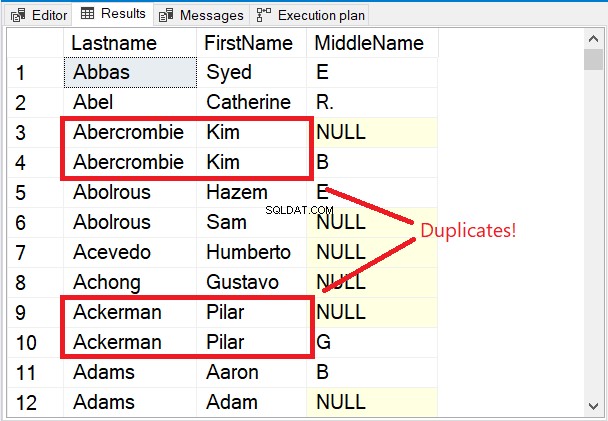
Las primeras filas son todas únicas. La palabra clave DISTINCT se aseguró de que el segundo nombre También se considera la columna. Observe los 2 nombres encuadrados en rojo. Teniendo en cuenta el Apellido y Nombre sólo los hará duplicados. Pero agregando Segundo nombre a la mezcla lo cambió todo.
¿Qué sucede si desea obtener nombres y apellidos únicos pero incluye el segundo nombre en el resultado?
Tienes 2 opciones:
- Agregue una cláusula WHERE para eliminar los segundos nombres NULL. Esto eliminará todos los nombres con un segundo nombre NULL.
- O agregue una cláusula GROUP BY en Lastname y Nombre columnas Luego, use la función agregada MIN en el Middlename columna. Esto obtendrá 1 segundo nombre con el mismo apellido y nombre.
SQL DISTINCT vs. GROUP BY
Cuando se usa GROUP BY sin una función agregada, actúa como DISTINCT. ¿Como sabemos? Una forma de averiguarlo es usar un ejemplo.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Ejecútelos y compruebe el plan de ejecución. ¿Es como la captura de pantalla de abajo?
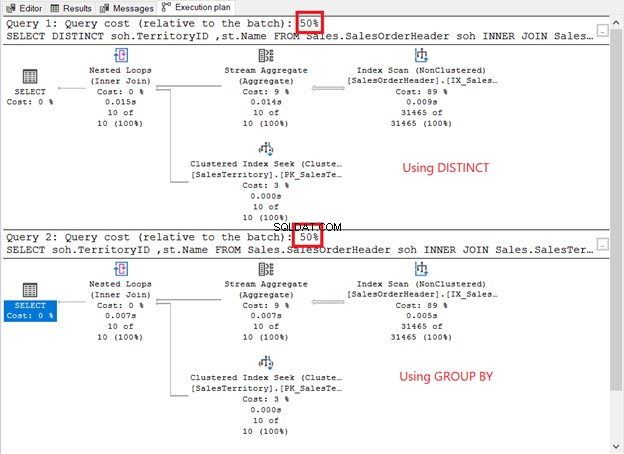
¿Cómo se comparan?
- Tienen los mismos operadores de plan y secuencia.
- El costo del operador de cada uno y los costos de consulta son los mismos.
Si marca el QueryPlanHash propiedades de los 2 operadores SELECT, son iguales. Por lo tanto, el optimizador de consultas utilizó el mismo proceso para devolver los mismos resultados.
Al final, no podemos decir que usar GROUP BY sea mejor que DISTINCT para devolver valores únicos. Puede probar esto usando los ejemplos anteriores para reemplazar DISTINCT con GROUP BY.
Ahora es una cuestión de preferencia cuál utilizará. Prefiero DISTINTO. Indica explícitamente la intención de la consulta:producir resultados únicos. Y para mí, GROUP BY es para agrupar resultados usando una función agregada. Esa intención también es clara y consistente con la palabra clave en sí. No sé si alguien más mantendrá mis consultas algún día. Entonces, el código debe ser claro.
Pero ese no es el final de la historia.
Cuando SQL DISTINCT no es lo mismo que GROUP BY
Solo expresé mi opinión, ¿y luego esto?
Es cierto. No serán los mismos todo el tiempo. Considere este ejemplo.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Aunque el conjunto de resultados no está ordenado, las filas son las mismas que en el ejemplo anterior. La única diferencia es el uso de una subconsulta:
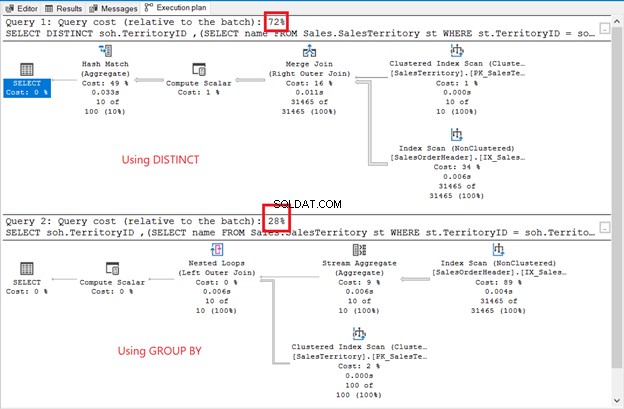
Las diferencias son obvias:operadores, costo de consulta, plan general. Esta vez, GROUP BY gana con solo un 28 % del costo de la consulta. Pero aquí está la cosa.
El objetivo es mostrarte que pueden ser diferentes. Eso es todo. Esto no es de ninguna manera una recomendación. El uso de una unión tiene un mejor plan de ejecución (consulte la Figura 6 nuevamente).
El resultado final
Esto es lo que hemos aprendido hasta ahora:
- DISTINCT agrega un operador de plan para eliminar duplicados.
- DISTINCT y GROUP BY sin una función agregada dan como resultado el mismo plan. En resumen, son los mismos la mayor parte del tiempo.
- A veces, DISTINCT y GROUP BY pueden tener diferentes planes cuando una subconsulta está involucrada en la lista SELECT.
Entonces, ¿SQL DISTINCT es bueno o malo para eliminar duplicados en los resultados?
Los resultados dicen que es bueno. No es mejor ni peor que GROUP BY porque los planes son los mismos. Pero es un buen hábito revisar el plan de ejecución. Piense en la optimización desde el principio. De esa manera, si encuentra diferencias entre DISTINCT y GROUP BY, las detectará.
Además, las herramientas modernas hacen que esta tarea sea mucho más sencilla. Por ejemplo, un producto popular dbForge SQL Complete de Devart tiene una característica específica que calcula valores en las funciones agregadas en el conjunto de resultados listos de la cuadrícula de resultados de SSMS. Los valores DISTINCT también están presentes allí.
¿Te gusta la publicación? Luego, corra la voz compartiéndolo en sus plataformas de redes sociales favoritas.
Artículos relacionados para obtener más información
- SQL GROUP BY:3 sencillos consejos para agrupar resultados como un profesional
- SQL INSERT INTO SELECT:5 formas fáciles de manejar duplicados
- ¿Qué son las funciones agregadas de SQL? (Consejos fáciles para novatos)
- Optimización de consultas SQL:5 datos básicos para impulsar las consultas