Como DBA de SQL Server, hemos escuchado que las estructuras de índice pueden mejorar drásticamente el rendimiento de cualquier consulta (o conjunto de consultas). Aún así, hay ciertos detalles que muchos DBA pasan por alto, como los siguientes:
- Las estructuras de índice pueden fragmentarse, lo que podría provocar problemas de degradación del rendimiento.
- Una vez que se ha implementado una estructura de índice para una tabla de base de datos, SQL Server la actualiza cada vez que se realizan operaciones de escritura para esa tabla. Esto sucede si las columnas que se ajustan al índice se ven afectadas.
- Hay metadatos dentro de SQL Server que se pueden usar para saber cuándo se actualizaron las estadísticas de una estructura de índice en particular (si alguna vez se actualizó) por última vez. Las estadísticas insuficientes o desactualizadas pueden afectar el rendimiento de ciertas consultas.
- Hay metadatos dentro de SQL Server que se pueden usar para saber cuánto se ha consumido una estructura de índice por operaciones de lectura o cuánto se ha actualizado mediante operaciones de escritura por parte del mismo SQL Server. Esta información podría ser útil para saber si existen índices cuyo volumen de escritura supera ampliamente al de lectura. Potencialmente puede ser una estructura de índice que no es tan útil de mantener.*
*Es muy importante tener en cuenta que la vista del sistema que contiene estos metadatos en particular se borra cada vez que se reinicia la instancia de SQL Server, por lo que no será información desde su concepción.
Debido a la importancia de estos detalles, he creado un procedimiento almacenado para realizar un seguimiento de la información sobre las estructuras de índice en su entorno, para actuar de la manera más proactiva posible.
Consideraciones iniciales
- Asegúrese de que la cuenta que ejecuta este procedimiento almacenado tenga suficientes privilegios. Probablemente podría comenzar con los administradores de sistemas y luego ir lo más granular posible para asegurarse de que el usuario tenga el mínimo de privilegios necesarios para que el SP funcione correctamente.
- Los objetos de la base de datos (tabla de la base de datos y procedimiento almacenado) se crearán dentro de la base de datos seleccionada en el momento en que se ejecute el script, así que elija con cuidado.
- La secuencia de comandos está diseñada de manera que se puede ejecutar varias veces sin que se arroje un error. Para el procedimiento almacenado, utilicé la declaración CREATE OR ALTER PROCEDURE, disponible desde SQL Server 2016 SP1.
- No dude en cambiar el nombre de los objetos de base de datos creados si desea utilizar una convención de nomenclatura diferente.
- Cuando elige conservar los datos devueltos por el procedimiento almacenado, la tabla de destino se trunca primero para que solo se almacene el conjunto de resultados más reciente. Puede hacer los ajustes necesarios si desea que esto se comporte de manera diferente, por cualquier motivo (¿quizás para mantener información histórica?).
¿Cómo usar el procedimiento almacenado?
- Copie y pegue el código T-SQL (disponible en este artículo).
- El SP espera 2 parámetros:
- @persistData:'Y' si el DBA desea guardar la salida en una tabla de destino y 'N' si el DBA solo quiere ver la salida directamente.
- @db:'all' para obtener la información de todas las bases de datos (sistema y usuario), 'user' para apuntar a las bases de datos del usuario, 'system' para apuntar solo a las bases de datos del sistema (excluyendo tempdb) y, por último, el nombre real de una base de datos en particular.
Campos presentados y su significado
- Nombre de base de datos: el nombre de la base de datos donde reside el objeto de índice.
- nombre de esquema: el nombre del esquema donde reside el objeto de índice.
- nombre de la tabla: el nombre de la tabla donde reside el objeto de índice.
- nombre del índice: el nombre de la estructura del índice.
- tipo: el tipo de índice (por ejemplo, agrupado, no agrupado).
- tipo_unidad_de_asignación: especifica el tipo de datos a los que se refiere (por ejemplo, datos en fila, datos de lob).
- fragmentación: la cantidad de fragmentación (en %) que tiene actualmente la estructura del índice.
- páginas: el número de páginas de 8 KB que forman la estructura del índice.
- escribe: la cantidad de escrituras que ha experimentado la estructura del índice desde que se reinició por última vez la instancia de SQL Server.
- lee: el número de lecturas que ha experimentado la estructura del índice desde que se reinició por última vez la instancia de SQL Server.
- deshabilitado: 1 si la estructura del índice está deshabilitada actualmente o 0 si la estructura está habilitada.
- estadísticas_marca de tiempo: el valor de marca de tiempo de cuándo se actualizaron por última vez las estadísticas de la estructura de índice en particular (NULL si nunca).
- datos_coleccion_marca de tiempo: visible solo si se pasa "Y" al parámetro @persistData, y se usa para saber cuándo se ejecutó el SP y la información se guardó correctamente en la tabla DBA_Indexes.
Pruebas de ejecución
Demostraré algunas ejecuciones del procedimiento almacenado para que pueda tener una idea de qué esperar de él:
*Puede encontrar el código T-SQL completo del script al final de este artículo, así que asegúrese de ejecutarlo antes de continuar con la siguiente sección.
*El conjunto de resultados será demasiado amplio para caber bien en 1 captura de pantalla, por lo que compartiré todas las capturas de pantalla necesarias para presentar la información completa.
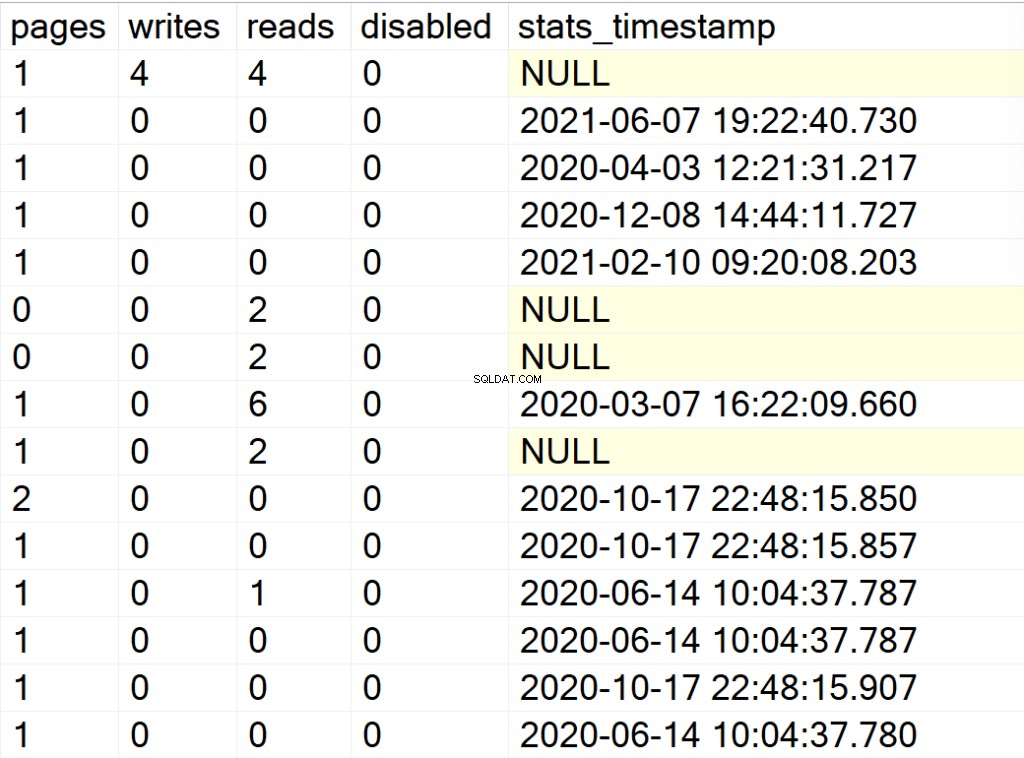
/* Mostrar toda la información de los índices para todas las bases de datos del sistema y de los usuarios */
EXEC GetIndexData @persistData = 'N',@db = 'all'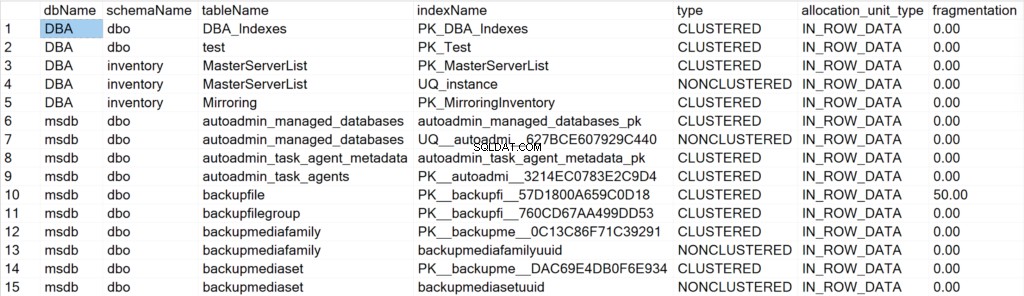
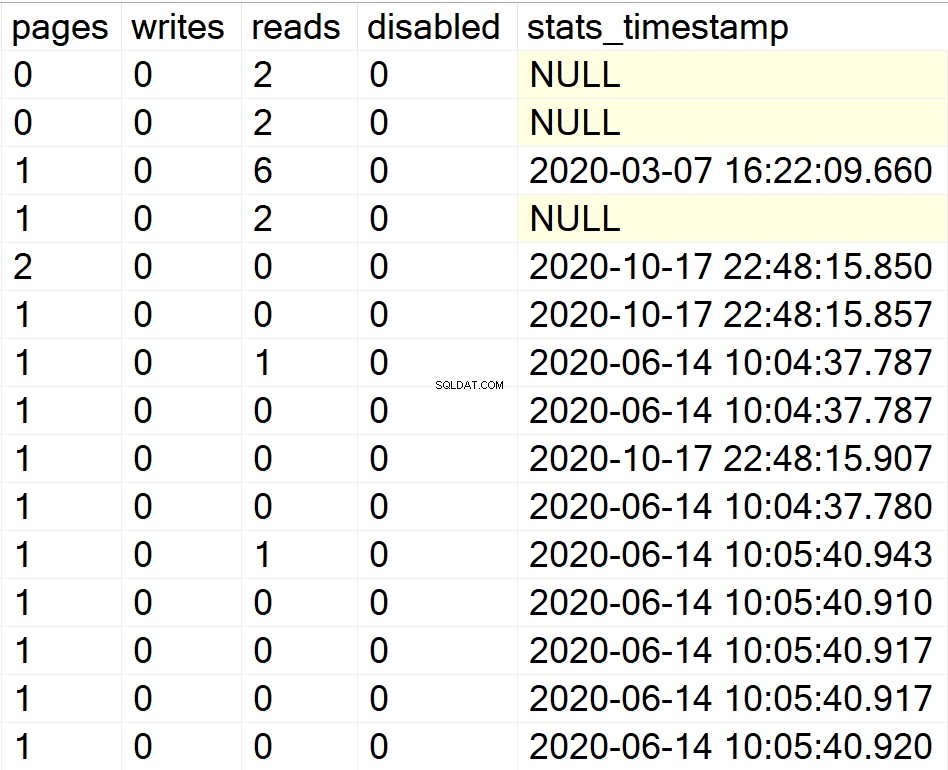
/* Mostrar toda la información de índices para todas las bases de datos del sistema */
EXEC GetIndexData @persistData = 'N',@db = 'system'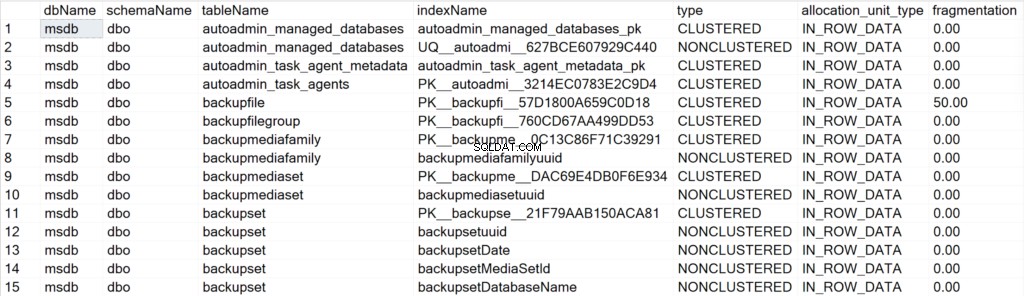
/* Mostrar toda la información de índices para todas las bases de datos de usuario */
EXEC GetIndexData @persistData = 'N',@db = 'user'
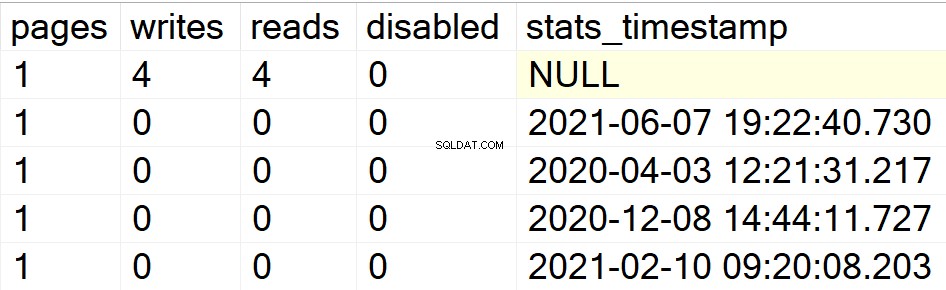
/* Mostrar toda la información de índices para bases de datos de usuarios específicos */
En mis ejemplos anteriores, solo la base de datos DBA aparecía como mi única base de datos de usuario con índices. Por lo tanto, permítanme crear una estructura de índice en otra base de datos que tengo en la misma instancia para que puedan ver si el SP hace lo suyo o no.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Todos los ejemplos mostrados hasta ahora demuestran el resultado que obtiene cuando no desea conservar los datos, para las diferentes combinaciones de opciones para el parámetro @db. La salida está vacía cuando especifica una opción que no es válida o la base de datos de destino no existe. Pero, ¿qué pasa cuando el DBA quiere conservar los datos en una tabla de base de datos? Vamos a averiguarlo.
*Voy a ejecutar el SP solo para un caso porque el resto de las opciones para el parámetro @db se han mostrado más arriba y el resultado es el mismo pero persiste en una tabla de base de datos.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
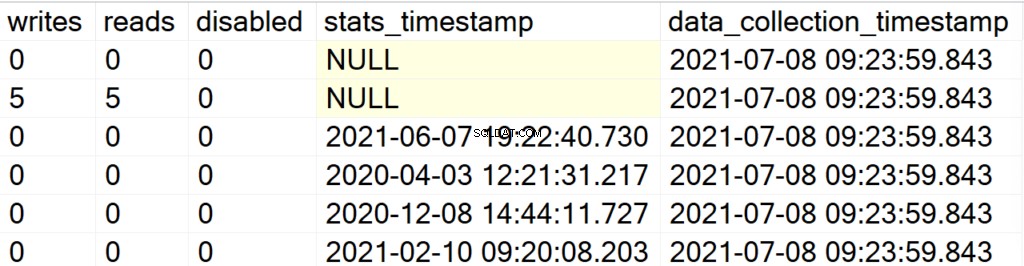
Ahora, después de ejecutar el Procedimiento almacenado, no obtendrá ningún resultado. Para consultar el conjunto de resultados, debe emitir una declaración SELECT en la tabla DBA_Indexes. La atracción principal aquí es que puede consultar el conjunto de resultados obtenidos, para el análisis posterior, y la adición del campo data_collection_timestamp que le permitirá saber qué tan recientes/antiguos son los datos que está viendo.
Consultas secundarias
Ahora, para brindar más valor al DBA, he preparado algunas consultas que pueden ayudarlo a obtener información útil de los datos persistentes en la tabla.
*Consulta para encontrar índices muy fragmentados en general.
*Elige el número de % que consideres adecuado.
*Las 1500 páginas se basan en un artículo que leí, basado en la recomendación de Microsoft.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*Consulta para encontrar índices deshabilitados dentro de tu entorno.
SELECT * FROM DBA_Indexes WHERE disabled = 1;*Consulta para encontrar índices (en su mayoría no agrupados) que las consultas no usan tanto, al menos no desde la última vez que se reinició la instancia de SQL Server.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*Consulta para encontrar estadísticas que nunca se han actualizado o que son antiguas.
*Usted determina lo que es antiguo dentro de su entorno, así que asegúrese de ajustar la cantidad de días en consecuencia.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Aquí está el código completo del procedimiento almacenado:
*Al principio de la secuencia de comandos, verá el valor predeterminado que asume el procedimiento almacenado si no se pasa ningún valor para cada parámetro.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOConclusión
- Puede implementar este SP en cada instancia de SQL Server bajo su soporte e implementar un mecanismo de alerta en toda su pila de instancias compatibles.
- Si implementa un trabajo de agente que consulta esta información con relativa frecuencia, puede mantenerse al tanto del juego para ocuparse de las estructuras de índice dentro de su(s) entorno(s) compatible(s).
- Asegúrese de probar este mecanismo correctamente en un entorno de espacio aislado y, cuando planee una implementación de producción, asegúrese de elegir períodos de baja actividad.
Los problemas de fragmentación de índices pueden ser complicados y estresantes. Para encontrarlos y corregirlos, puede usar diferentes herramientas, como dbForge Index Manager, que se puede descargar aquí.



