Spark comenzó su vida en 2009 como un proyecto dentro de AMPLab en la Universidad de California, Berkeley. Más concretamente, nació de la necesidad de probar el concepto de Mesos, que también se creó en el AMPLab. Spark se analizó por primera vez en el documento técnico de Mesos titulado Mesos:una plataforma para compartir recursos de grano fino en el centro de datos, escrito principalmente por Benjamin Hindman y Matei Zaharia.
Surgió como una solución rápida y conveniente para realizar análisis complejos de datos a gran escala. Spark evolucionó como un nuevo marco de procesamiento para big data que aborda muchas de las deficiencias del modelo MapReduce. Es compatible con el análisis de datos a gran escala, y los datos pueden provenir de diferentes fuentes, como tiempo real, procesamiento por lotes en varios formatos, como imágenes, textos, gráficos y muchos más. Además de su núcleo Apache Spark, también proporciona un conjunto útil de bibliotecas para el análisis de big data.
Descripción general de los componentes de Spark
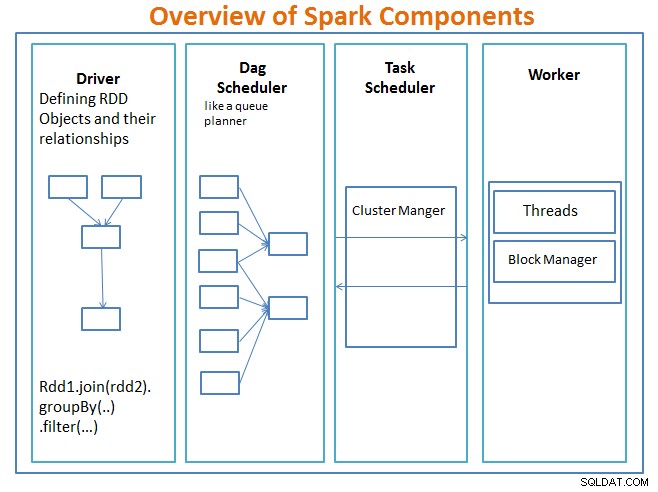
El conductor es el código que incluye la función principal y define los conjuntos de datos distribuidos resilientes (RDD) y sus transformaciones. Los RDD son las principales estructuras de datos que se utilizarán en nuestros programas Spark.
Las operaciones paralelas en los RDD se envían al programador DAG , que optimizará el código y llegará a un DAG eficiente que represente los pasos de procesamiento de datos en la aplicación.
El DAG resultante se envía al administrador de clúster y el administrador del clúster tiene información sobre los trabajadores, los subprocesos asignados y la ubicación de los bloques de datos y es responsable de asignar tareas de procesamiento específicas a los trabajadores. También maneja la parte posterior del caso en caso de falla del trabajador. El administrador del clúster puede ser YARN, Mesos, el administrador del clúster de Spark.
El trabajador recibe unidades de trabajo y datos para administrar y el trabajador ejecuta su tarea específica sin conocer todo el DAG y sus resultados se envían a las aplicaciones del controlador.
Spark, al igual que otras herramientas de big data, es potente, capaz y muy adecuado para hacer frente a una variedad de desafíos de datos. Spark, al igual que otras tecnologías de big data, no es necesariamente la mejor opción para todas las tareas de procesamiento de datos.
En la Parte 2, analizaremos los conceptos básicos de Spark como conjuntos de datos distribuidos resistentes, variables compartidas, SparkContext, transformaciones, acción y Ventajas de usar Spark junto con ejemplos y cuándo usar Spark.
Referencia:
Aprenda Spark en un día por Acodemy y Hadoop Applications Architectures.