Supongamos que desea encontrar a todos los pacientes que nunca se han vacunado contra la gripe. O, en AdventureWorks2012 , una pregunta similar podría ser "muéstrame todos los clientes que nunca han realizado un pedido". Expresado usando NOT IN , un patrón que veo con demasiada frecuencia, que se vería así (estoy usando el encabezado ampliado y las tablas de detalles de este script de Jonathan Kehayias (@SQLPoolBoy)):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Cuando veo este patrón, me estremezco. Pero no por razones de rendimiento; después de todo, crea un plan bastante decente en este caso:
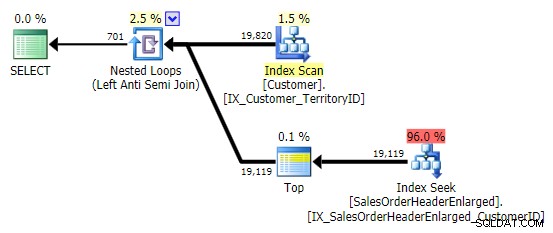
El principal problema es que los resultados pueden ser sorprendentes si la columna de destino admite valores NULL (SQL Server procesa esto como una combinación semi izquierda, pero no puede decirle de manera confiable si un valor NULL en el lado derecho es igual o no a – la referencia en el lado izquierdo). Además, la optimización puede comportarse de manera diferente si la columna admite NULL, incluso si en realidad no contiene ningún valor NULL (Gail Shaw habló de esto en 2010).
En este caso, la columna de destino no admite valores NULL, pero quería mencionar esos posibles problemas con NOT IN – Puedo investigar estos problemas más a fondo en una publicación futura.
Versión TL;DR
En lugar de NOT IN , use un NOT EXISTS correlacionado para este patrón de consulta. Siempre. Otros métodos pueden competir con él en términos de rendimiento, cuando todas las demás variables son iguales, pero todos los demás métodos presentan problemas de rendimiento u otros desafíos.
Alternativas
Entonces, ¿de qué otras maneras podemos escribir esta consulta?
APLICACIÓN EXTERIOR
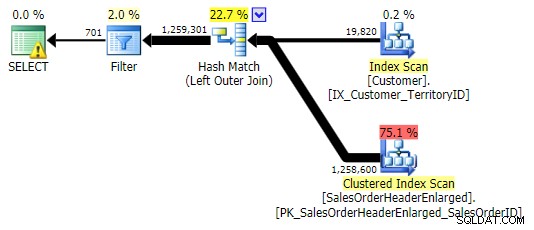
Una forma en que podemos expresar este resultado es usando un OUTER APPLY correlacionado .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Lógicamente, este también es un operador de antisemi-unión por la izquierda, pero al plan resultante le falta el operador de antisemi-unión por la izquierda, y parece ser un poco más caro que el NOT IN equivalente. Esto se debe a que ya no es una combinación semi izquierda; en realidad, se procesa de una manera diferente:una combinación externa trae todas las filas coincidentes y no coincidentes, y *luego* se aplica un filtro para eliminar las coincidencias:
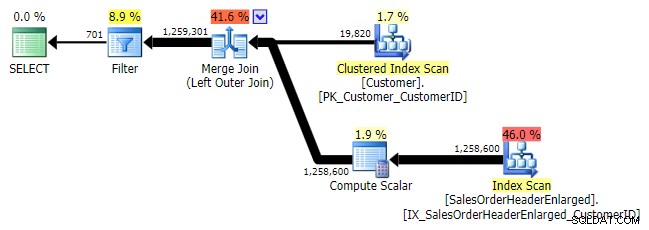
UNIÓN EXTERNA IZQUIERDA
Una alternativa más típica es LEFT OUTER JOIN donde el lado derecho es NULL . En este caso la consulta sería:
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
Esto devuelve los mismos resultados; sin embargo, al igual que OUTER APPLY, utiliza la misma técnica de unir todas las filas y solo luego eliminar las coincidencias:
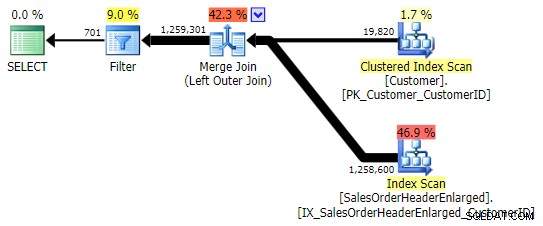
Sin embargo, debe tener cuidado con la columna que verifica para NULL . En este caso CustomerID es la opción lógica porque es la columna de unión; también pasa a estar indexado. Podría haber elegido SalesOrderID , que es la clave de agrupación, por lo que también está en el índice de CustomerID . Pero podría haber elegido otra columna que no esté (o que luego se elimine) del índice utilizado para la unión, lo que llevaría a un plan diferente. O incluso una columna anulable, lo que lleva a resultados incorrectos (o al menos inesperados), ya que no hay forma de diferenciar entre una fila que no existe y una fila que sí existe, pero donde esa columna es NULL . Y puede que no sea obvio para el lector/desarrollador/solucionador de problemas que este es el caso. Así que también probaré estos tres WHERE cláusulas:
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
La primera variación produce el mismo plan que el anterior. Los otros dos eligen una combinación hash en lugar de una combinación de combinación y un índice más estrecho en el Customer tabla, aunque la consulta finalmente termina leyendo exactamente el mismo número de páginas y la misma cantidad de datos. Sin embargo, mientras que h.SubTotal variación produce los resultados correctos:
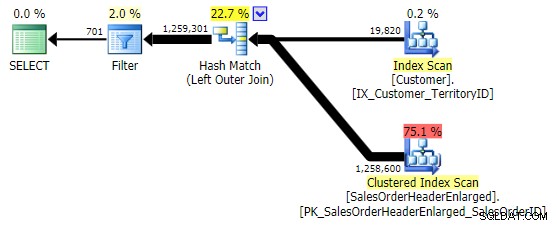
El h.Comment la variación no lo hace, ya que incluye todas las filas donde h.Comment IS NULL , así como todas las filas que no existían para ningún cliente. He resaltado la diferencia sutil en el número de filas en la salida después de aplicar el filtro:
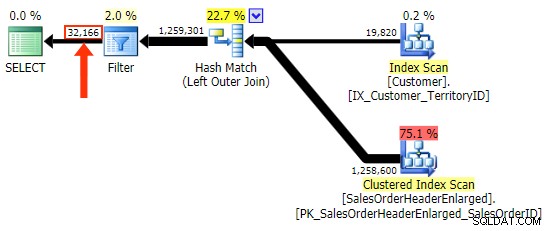
Además de tener cuidado con la selección de columnas en el filtro, el otro problema que tengo con LEFT OUTER JOIN forma es que no se documenta a sí misma, de la misma manera que una unión interna en la forma de "estilo antiguo" de FROM dbo.table_a, dbo.table_b WHERE ... no es autodocumentado. Con eso quiero decir que es fácil olvidar los criterios de unión cuando se empuja a WHERE cláusula, o para que se mezcle con otros criterios de filtro. Me doy cuenta de que esto es bastante subjetivo, pero ahí está.
EXCEPTO
Si todo lo que nos interesa es la columna de unión (que por definición está en ambas tablas), podemos usar EXCEPT – una alternativa que no parece surgir mucho en estas conversaciones (probablemente porque, por lo general, necesita ampliar la consulta para incluir columnas que no está comparando):
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
Esto presenta exactamente el mismo plan que el NOT IN variación anterior:
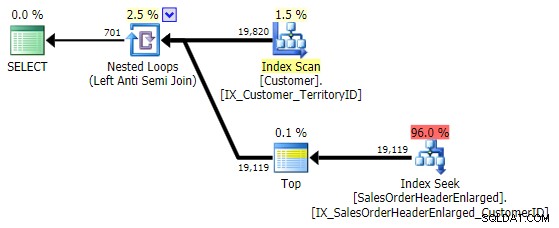
Una cosa a tener en cuenta es que EXCEPT incluye un DISTINCT implícito – Entonces, si tiene casos en los que desea que varias filas tengan el mismo valor en la tabla "izquierda", este formulario eliminará esos duplicados. No es un problema en este caso específico, solo algo a tener en cuenta, como UNION versus UNION ALL .
NO EXISTE
Mi preferencia por este patrón es definitivamente NOT EXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(Y sí, uso SELECT 1 en lugar de SELECT * … no por razones de rendimiento, ya que a SQL Server no le importa qué columna(s) use dentro de EXISTS y los optimiza, pero simplemente para aclarar la intención:esto me recuerda que esta "subconsulta" en realidad no devuelve ningún dato).
Su rendimiento es similar a NOT IN y EXCEPT , y produce un plan idéntico, pero no es propenso a los posibles problemas causados por NULL o duplicados:
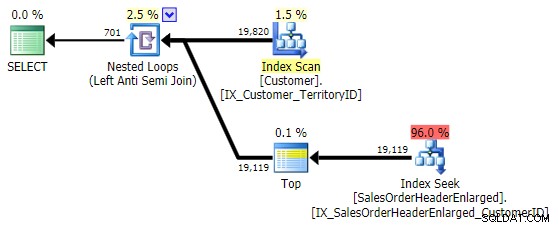
Pruebas de rendimiento
Realicé una multitud de pruebas, tanto con caché frío como caliente, para validar que mi percepción de larga data sobre NOT EXISTS siendo la elección correcta siguió siendo cierto. La salida típica se veía así:
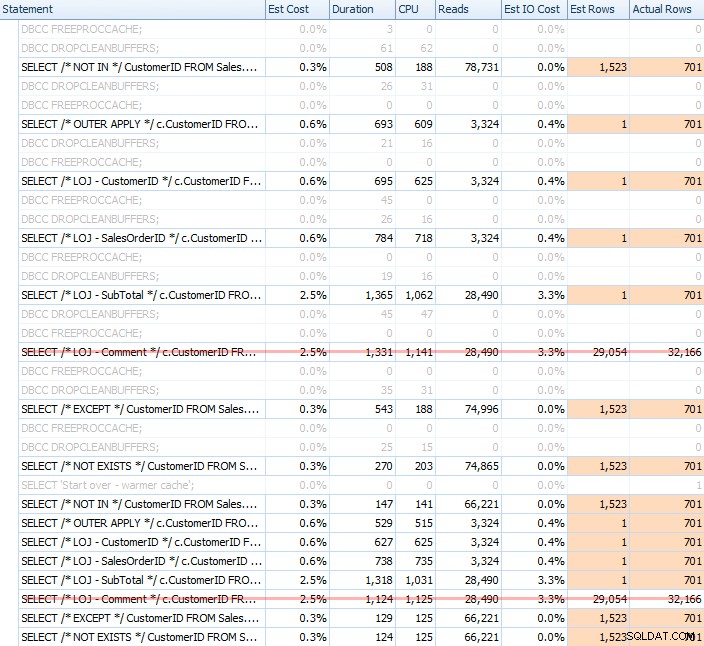
Eliminaré el resultado incorrecto de la combinación cuando muestre el rendimiento promedio de 20 ejecuciones en un gráfico (solo lo incluí para demostrar cuán incorrectos son los resultados), y ejecuté las consultas en orden diferente en las pruebas para asegurarme que una consulta no se estaba beneficiando constantemente del trabajo de una consulta anterior. Centrándonos en la duración, estos son los resultados:
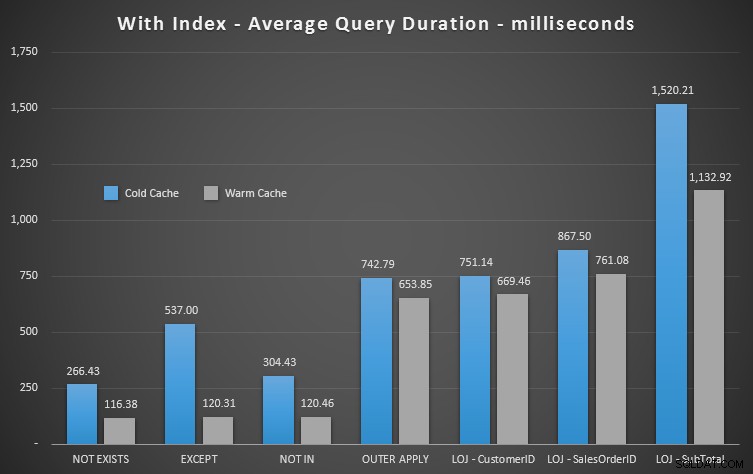
Si observamos la duración e ignoramos las lecturas, NOT EXISTS es su ganador, pero no por mucho. EXCEPT y NOT IN no se quedan atrás, pero nuevamente, debe observar más que el rendimiento para determinar si estas opciones son válidas y probarlas en su escenario.
¿Qué pasa si no hay un índice de apoyo?
Las consultas anteriores se benefician, por supuesto, del índice en Sales.SalesOrderHeaderEnlarged.CustomerID . ¿Cómo cambian estos resultados si bajamos este índice? Volví a ejecutar el mismo conjunto de pruebas, después de eliminar el índice:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Esta vez hubo mucha menos desviación en términos de rendimiento entre los diferentes métodos. Primero mostraré los planes para cada método (la mayoría de los cuales, como es lógico, indican la utilidad del índice faltante que acabamos de eliminar). Luego, mostraré un nuevo gráfico que representa el perfil de rendimiento tanto con un caché frío como con un caché tibio.
NO EN, EXCEPTO, NO EXISTE (los tres eran idénticos)
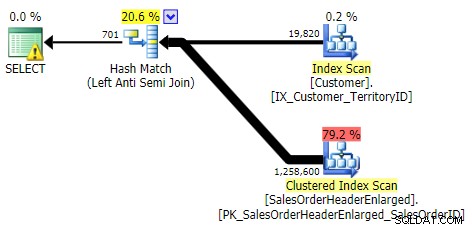
APLICACIÓN EXTERIOR
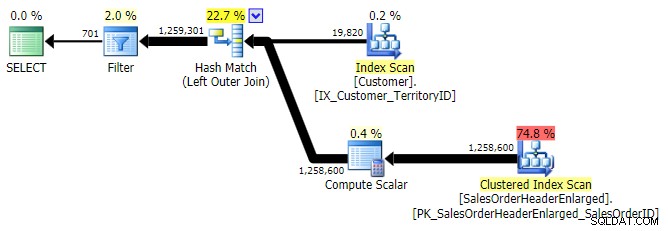
UNIÓN EXTERNA IZQUIERDA (los tres eran idénticos excepto por el número de filas)
Resultados de rendimiento
Podemos ver de inmediato cuán útil es el índice cuando observamos estos nuevos resultados. En todos los casos excepto en uno (la combinación externa izquierda que, de todos modos, sale del índice), los resultados son claramente peores cuando eliminamos el índice:
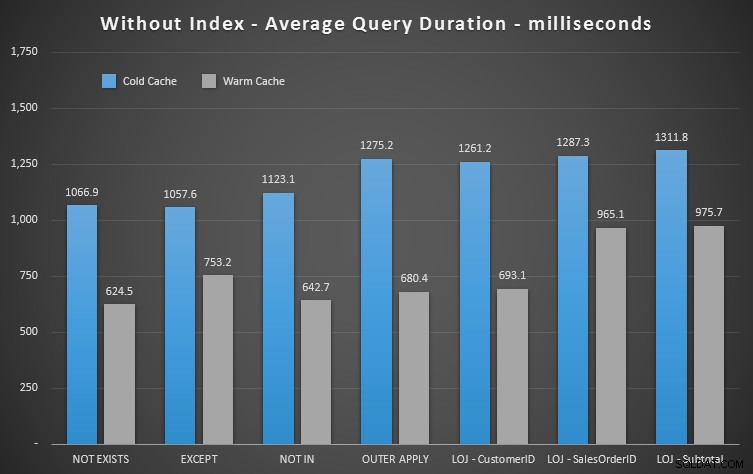
Entonces podemos ver que, si bien hay un impacto menos notable, NOT EXISTS sigue siendo su ganador marginal en términos de duración. Y en situaciones donde los otros enfoques son susceptibles a la volatilidad del esquema, también es su opción más segura.
Conclusión
Esta fue solo una forma muy larga de decirte que, para el patrón de encontrar todas las filas en la tabla A donde no existe alguna condición en la tabla B, NOT EXISTS normalmente va a ser su mejor opción. Pero, como siempre, debe probar estos patrones en su propio entorno, utilizando su esquema, datos y hardware, y combinándolos con sus propias cargas de trabajo.