Como consultor que trabaja con SQL Server, muchas veces me piden que mire un servidor que parece tener problemas de rendimiento. Mientras realizo la clasificación en el servidor, hago ciertas preguntas, como:cuál es su uso normal de CPU, cuál es su latencia promedio de disco, cuál es su uso normal de memoria, etc. La respuesta suele ser "no sabemos" o "no estamos capturando esa información con regularidad". No tener una línea de base reciente hace que sea muy difícil saber cómo se ve el comportamiento anormal. Si no sabe qué es un comportamiento normal, ¿cómo sabe con certeza si las cosas están mejor o peor? A menudo uso las expresiones "si no lo estás monitoreando, no puedes medirlo" y "si no lo estás midiendo, no puedes administrarlo".
Desde una perspectiva de monitoreo, como mínimo, las organizaciones deben monitorear trabajos fallidos como copias de seguridad, mantenimiento de índices, DBCC CHECKDB y cualquier otro trabajo de importancia. Es fácil configurar notificaciones de falla para estos; sin embargo, también necesita un proceso para asegurarse de que los trabajos se ejecuten como se esperaba. He visto trabajos que se cuelgan y nunca se completan. Una notificación de falla no activaría una alarma ya que el trabajo nunca se realiza correctamente o falla.
A partir de una línea de base de rendimiento, hay varias métricas clave que deben capturarse. Creé un proceso que uso con clientes que captura métricas clave de forma regular y almacena esos valores en una base de datos de usuarios. Mi proceso es simple:una base de datos dedicada con procedimientos almacenados que usan scripts comunes que insertan los conjuntos de resultados en las tablas. Tengo trabajos del Agente SQL para ejecutar los procedimientos almacenados a intervalos regulares y un script de limpieza para purgar los datos anteriores a X días. Las métricas que siempre capturo incluyen:
Esperanza de vida de la página :PLE es probablemente una de las mejores formas de medir si su sistema está bajo presión de memoria interna. La mayoría de los sistemas tienen valores PLE que fluctúan durante las cargas de trabajo normales. Me gusta ver la tendencia de estos valores para saber cuáles son los valores mínimo, promedio y máximo. Me gusta tratar de entender qué causó que PLE cayera durante ciertos momentos del día para ver si esos procesos se pueden ajustar. Muchas veces, alguien está haciendo un escaneo de la tabla y vaciando el grupo de búfer. Ser capaz de indexar correctamente esas consultas puede ayudar. Solo asegúrese de estar monitoreando el contador PLE correcto; consulte aquí .
Utilización de la CPU :Tener una línea de base para la utilización de la CPU le permite saber si su sistema se encuentra repentinamente bajo presión de la CPU. A menudo, cuando un usuario se queja de problemas de rendimiento, observará que la CPU parece alta. Por ejemplo, si la CPU ronda el 80 %, es posible que lo consideren preocupante; sin embargo, si la CPU también fue del 80 % durante el mismo período de tiempo de las semanas anteriores cuando no se informaron problemas, la probabilidad de que la CPU sea el problema es muy baja. La tendencia de la CPU no es solo para capturar cuando la CPU aumenta y se mantiene en un valor alto constante. Tengo numerosas historias de cuando me pusieron en un puente de conferencia de gravedad porque había un problema con una aplicación. Siendo el DBA, usé el sombrero de "Aceptador de culpa predeterminado". Cuando el equipo de la aplicación dijo que había un problema con la base de datos, estaba en mí probar que no lo era, el servidor de la base de datos era culpable hasta que se probara su inocencia. Recuerdo vívidamente un incidente en el que el equipo de la aplicación estaba seguro de que el servidor de la base de datos estaba teniendo problemas porque los usuarios no podían conectarse. Habían leído en Internet que SQL Server podría estar sufriendo una inanición del grupo de subprocesos si rechazaba las conexiones. Salté al servidor y comencé a buscar recursos y qué procesos se estaban ejecutando actualmente. A los pocos minutos informé que el servidor en cuestión estaba muy aburrido. Según nuestras métricas de referencia, la CPU era normalmente del 60 % y estaba inactiva alrededor del 20 %, la esperanza de vida de la página era notablemente más alta de lo normal y no se producían bloqueos ni bloqueos, la E/S se veía muy bien, no había errores en ningún registro y los recuentos de sesiones fueron aproximadamente 1/3 de su recuento normal. Luego hice el comentario:"Parece que los usuarios ni siquiera están llegando al servidor de la base de datos". Eso llamó la atención de la gente de la red y se dieron cuenta de que un cambio que hicieron en el balanceador de carga no estaba funcionando correctamente y determinaron que más del 50 % de las conexiones se enrutaban incorrectamente y no llegaban al servidor de la base de datos. Si no hubiera sabido cuál era la línea de base, nos habría llevado mucho más tiempo llegar a la resolución.
E/S de disco :La captura de métricas de disco es muy importante. El DMV sys.dm_io_virtual_file_stats es acumulativo desde el último reinicio del servidor. La captura de sus latencias de E/S durante un intervalo de tiempo le dará una línea de base de lo que es normal durante ese tiempo. Confiar en el valor acumulativo puede brindarle datos sesgados de actividades posteriores al horario comercial o largos períodos en los que el sistema estuvo inactivo. Paul discutió eso aquí .
Tamaños de archivo de base de datos :tener un inventario de sus bases de datos que incluya el tamaño del archivo, el tamaño usado, el espacio libre y más puede ayudarlo a pronosticar el crecimiento de la base de datos. A menudo me piden que pronostique cuánto almacenamiento se necesitaría para un servidor de base de datos durante el próximo año. Sin conocer la tendencia de crecimiento semanal o mensual, no tengo forma de llegar a una cifra de manera inteligente. Una vez que empiezo a rastrear estos valores, puedo hacer una tendencia adecuada de esto. Además de las tendencias, también pude encontrar cuándo hubo un crecimiento inesperado de la base de datos. Cuando veo un crecimiento inesperado e investigo, generalmente encuentro que alguien duplicó una tabla para hacer algunas pruebas (¡sí, en producción!) o realizó algún otro proceso único. El seguimiento de este tipo de datos y la capacidad de responder cuando se producen anomalías ayuda a demostrar que es proactivo y vigila sus sistemas.
Estadísticas de espera :Supervisar las estadísticas de espera puede ayudarlo a comenzar a descubrir la causa de ciertos problemas de rendimiento. Muchos DBA nuevos se preocupan cuando comienzan a investigar las estadísticas de espera y no se dan cuenta de que las esperas siempre ocurren, y esa es la forma en que funciona el sistema de programación de SQL Server. También hay muchas esperas que pueden considerarse benignas o, en su mayoría, inofensivas. Paul Randal excluye estas esperas en su mayoría inofensivas en su popular script de estadísticas de espera. Paul también ha creado una amplia biblioteca de los distintos tipos de espera y clases de pestillo con descripciones y otra información sobre cómo solucionar problemas de esperas y pestillos.
He documentado mi proceso de recopilación de datos y puedes encontrar el código en mi blog . Dependiendo de la situación y los tipos de problemas que pueda tener un cliente, es posible que también desee capturar métricas adicionales. Glenn Berry escribió en su blog sobre un proceso que elaboró que captura el recuento promedio de tareas, el recuento promedio de tareas ejecutables, el recuento promedio de E/S pendientes, la utilización de la CPU del proceso de SQL Server y la esperanza de vida promedio de la página en todos los nodos NUMA. Una búsqueda rápida en Internet mostrará varios otros procesos de recopilación de datos que las personas han compartido, incluso el SQL Server Tiger Team tiene un proceso que utiliza T-SQL y PowerShell.
El uso de una base de datos personalizada y la creación de su propio paquete de recopilación de datos es una solución válida para capturar una línea base, pero la mayoría de nosotros no estamos en el negocio de crear soluciones completas de monitoreo de SQL Server. Hay mucho más que sería útil capturar, cosas como consultas de ejecución prolongada, consultas principales y procedimientos almacenados basados en memoria, E/S y CPU, interbloqueos, fragmentación de índices, transacciones por segundo y mucho más. Por eso, siempre recomiendo que los clientes compren una herramienta de monitoreo de terceros. Estos proveedores se especializan en mantenerse actualizados sobre las últimas tendencias y características de SQL Server para que pueda concentrar su tiempo en asegurarse de que SQL Server sea lo más estable y rápido posible.
Soluciones como SQL Sentry (para SQL Server) y DB Sentry (para Azure SQL Database) captura todas estas métricas por usted y le permite crear fácilmente diferentes líneas de base. Puede tener una línea de base normal, fin de mes, fin de trimestre y más. Luego puede aplicar la línea de base y ver visualmente cómo las cosas son diferentes. Más importante aún, puede configurar cualquier cantidad de alertas para diversas condiciones y recibir una notificación cuando las métricas excedan sus umbrales.
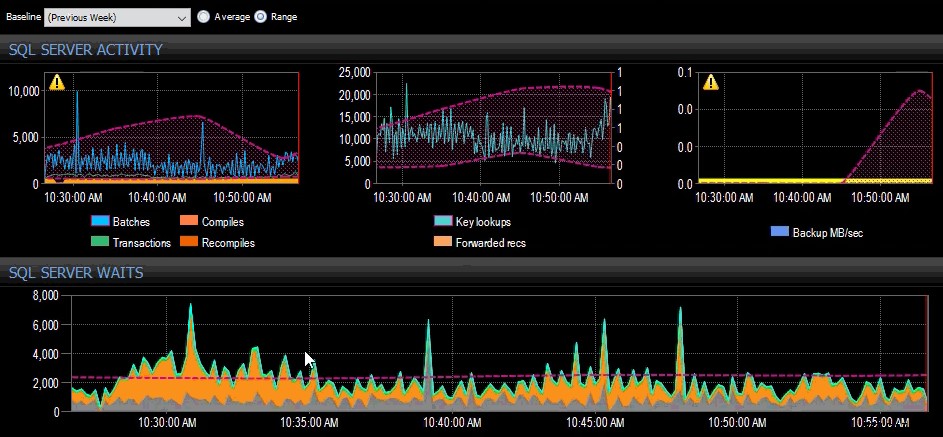 La línea base de la semana pasada se aplicó a varias métricas de SQL Server en el tablero de SQL Sentry.
La línea base de la semana pasada se aplicó a varias métricas de SQL Server en el tablero de SQL Sentry.
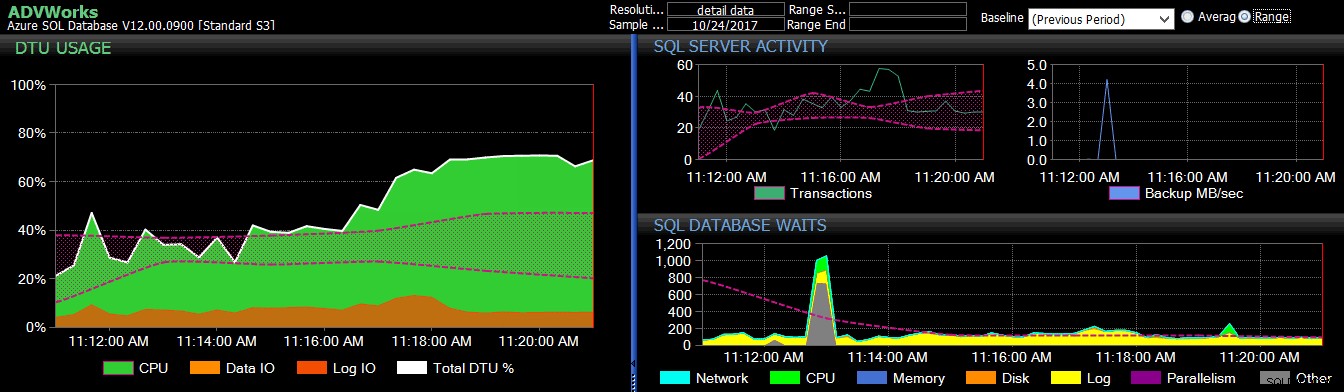 La referencia del período anterior se aplicó a varias métricas de Azure SQL Database en el panel de DB Sentry.
La referencia del período anterior se aplicó a varias métricas de Azure SQL Database en el panel de DB Sentry.
Para obtener más información sobre las líneas de base en SentryOne, consulte estas publicaciones en el blog de su equipo, o este video de martes de 2 minutos . ¿Está interesado en descargar una versión de prueba? También te tienen cubierto allí .