Este artículo es el tercero de una serie sobre umbrales de optimización para agrupar y agregar datos. En la Parte 1, cubrí el algoritmo Stream Aggregate pedido por adelantado. En la Parte 2, cubrí el algoritmo Sort + Stream Aggregate no ordenado previamente. En esta parte, cubro el algoritmo Hash Match (Agregado), al que me referiré simplemente como Hash Aggregate. También proporciono un resumen y una comparación entre los algoritmos que cubro en la Parte 1, Parte 2 y Parte 3.
Usaré la misma base de datos de muestra llamada PerformanceV3, que usé en los artículos anteriores de la serie. Solo asegúrese de que antes de ejecutar los ejemplos en el artículo, primero ejecute el siguiente código para eliminar un par de índices innecesarios:
SOLTA EL ÍNDICE idx_nc_sid_od_cid EN dbo.Orders;SUELTA EL ÍNDICE idx_unc_od_oid_i_cid_eid EN dbo.Orders;
Los únicos dos índices que deben quedar en esta tabla son idx_cl_od (agrupados con orderdate como clave) y PK_Orders (no agrupados con orderid como clave).
Agregado de hash
El algoritmo Hash Aggregate organiza los grupos en una tabla hash en función de alguna función hash elegida internamente. A diferencia del algoritmo Stream Aggregate, no necesita consumir las filas en orden de grupo. Considere la siguiente consulta (la llamaremos Consulta 1) como ejemplo (forzar un agregado de hash y un plan en serie):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
La Figura 1 muestra el plan para la Consulta 1.
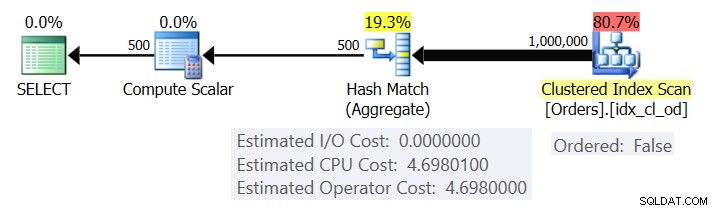
Figura 1:Plan para Consulta 1
El plan escanea las filas del índice agrupado usando una propiedad Ordenado:Falso (no es necesario escanear para entregar las filas ordenadas por la clave de índice). Por lo general, el optimizador preferirá escanear el índice de cobertura más estrecho, que en nuestro caso resulta ser el índice agrupado. El plan crea una tabla hash con las columnas agrupadas y los agregados. Nuestra consulta solicita un agregado COUNT de tipo INT. El plan en realidad lo calcula como un valor de tipo BIGINT, por lo tanto, el operador Compute Scalar, aplicando conversión implícita a INT.
Microsoft no comparte públicamente los algoritmos hash que utilizan. Esta es una tecnología muy patentada. Aún así, para ilustrar el concepto, supongamos que SQL Server usa la función hash % 250 (módulo 250) para nuestra consulta anterior. Antes de procesar cualquier fila, nuestra tabla hash tiene 250 cubos que representan los 250 resultados posibles de la función hash (0 a 249). A medida que SQL Server procesa cada fila, aplica la función hash
orderid empid ------- ----- 320 330 5660 253820 3850 11000 255700 31240 253350 4400 255
La Figura 2 muestra tres estados de la tabla hash:antes de que se procesen las filas, después de que se procesen las primeras 5 filas y después de que se procesen las primeras 10 filas. Cada elemento de la lista enlazada contiene la tupla (empid, COUNT(*)).
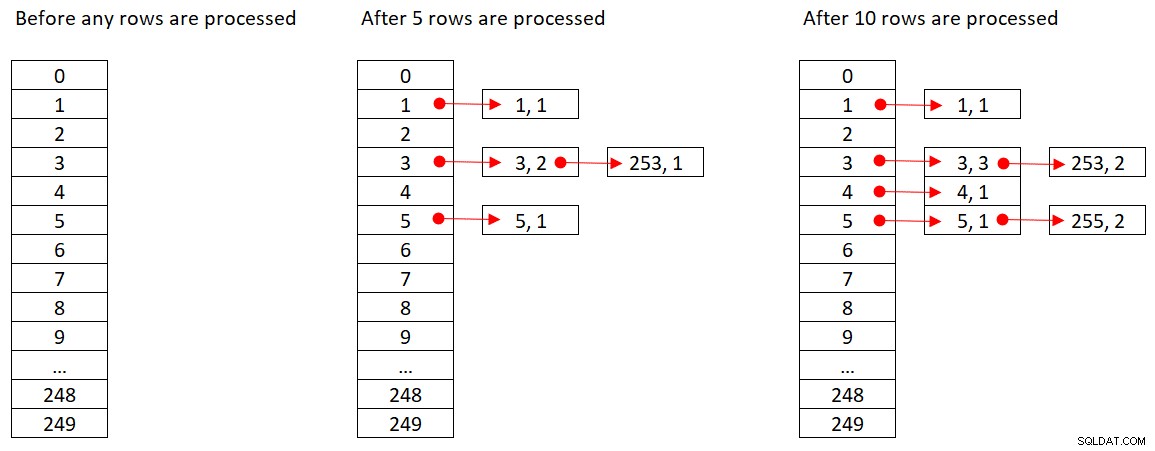
Figura 2:Estados de la tabla hash
Una vez que el operador Hash Aggregate termina de consumir todas las filas de entrada, la tabla hash tiene todos los grupos con el estado final del agregado.
Al igual que el operador Sort, el operador Hash Aggregate requiere una concesión de memoria y, si se queda sin memoria, debe pasar a tempdb; sin embargo, mientras que la ordenación requiere una concesión de memoria que sea proporcional al número de filas que se van a ordenar, el hashing requiere una concesión de memoria que sea proporcional al número de grupos. Entonces, especialmente cuando el conjunto de agrupación tiene alta densidad (pequeño número de grupos), este algoritmo requiere significativamente menos memoria que cuando se requiere una clasificación explícita.
Considere las siguientes dos consultas (llámelas Consulta 1 y Consulta 2):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECCIONE empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
La Figura 3 compara las concesiones de memoria para estas consultas.

Figura 3:Planes para Consulta 1 y Consulta 2
Observe la gran diferencia entre las concesiones de memoria en los dos casos.
En cuanto al costo del operador Hash Aggregate, volviendo a la Figura 1, observe que no hay costo de E/S, sino solo un costo de CPU. A continuación, intente aplicar ingeniería inversa a la fórmula de cálculo de costos de la CPU utilizando técnicas similares a las que cubrí en las partes anteriores de la serie. Los factores que potencialmente pueden afectar el costo del operador son la cantidad de filas de entrada, la cantidad de grupos de salida, la función agregada utilizada y por qué se agrupa (cardinalidad del conjunto de agrupación, tipos de datos utilizados).
Es de esperar que este operador tenga un costo inicial en preparación para construir la tabla hash. También esperaría que escalara linealmente con respecto al número de filas y grupos. Eso es de hecho lo que encontré. Sin embargo, mientras que los costos de los operadores Stream Aggregate y Sort no se ven afectados por la agrupación, parece que el costo del operador Hash Aggregate sí lo está, tanto en términos de la cardinalidad del conjunto de agrupación como de los tipos de datos utilizados.
Para observar que la cardinalidad del conjunto de agrupación afecta el costo del operador, verifique los costos de CPU de los operadores Hash Aggregate en los planes para las siguientes consultas (llámelas Consulta 3 y Consulta 4):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECCIONE orderid % 50 AS grp1, orderid % 20 AS grp2, MAX (fecha de pedido) COMO maxod FROM (SELECCIONE TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPCIÓN (HASH GROUP, MAXDOP 1 );
Por supuesto, desea asegurarse de que el número estimado de filas de entrada y grupos de salida sea el mismo en ambos casos. Los planes estimados para estas consultas se muestran en la Figura 4.
Figura 4:Planes para Consulta 3 y Consulta 4
Como puede ver, el costo de CPU del operador Hash Aggregate es 0,16903 cuando se agrupa por una columna de enteros y 0,174016 cuando se agrupa por dos columnas de enteros, siendo todo lo demás igual. Esto significa que la cardinalidad del conjunto de agrupación afecta el costo.
En cuanto a si el tipo de datos del elemento agrupado afecta el costo, utilicé las siguientes consultas para verificar esto (llámelas Consulta 5, Consulta 6 y Consulta 7):
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY CAST(orderid AS SMALLINT) % OPCIÓN CAST (1000 COMO SMALLINT) (GRUPO HASH, MAXDOP 1); SELECCIONE orderid % 1000 AS grp, MAX(orderdate) COMO maxod FROM (SELECCIONE TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECCIONE CAST (orderid COMO BIGINT) % CAST (1000 COMO BIGINT) COMO grp, MAX (fecha de pedido) COMO maxod FROM (SELECCIONE TOP (20000) * FROM dbo.Orders) AS D GROUP BY CAST (orderid COMO BIGINT) % CAST (1000) COMO BIGINT) OPCIÓN (GRUPO HASH, MAXDOP 1);
Los planes para las tres consultas tienen el mismo número estimado de filas de entrada y grupos de salida, pero todos obtienen costos de CPU estimados diferentes (0,121766, 0,16903 y 0,171716), por lo tanto, el tipo de datos utilizado afecta el costo.
El tipo de función agregada también parece tener un impacto en el costo. Por ejemplo, considere las siguientes dos consultas (llámelas Consulta 8 y Consulta 9):
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECCIONE orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
El costo de CPU estimado para Hash Aggregate en el plan para la consulta 8 es 0,166344 y en la consulta 9 es 0,16903.
Podría ser un ejercicio interesante tratar de averiguar exactamente de qué manera la cardinalidad del conjunto de agrupación, los tipos de datos y la función agregada utilizada afectan el costo; Simplemente no perseguí este aspecto del cálculo de costos. Entonces, después de elegir el conjunto de agrupación y la función agregada para su consulta, puede aplicar ingeniería inversa a la fórmula de costos. Por ejemplo, hagamos ingeniería inversa de la fórmula de costos de CPU para el operador Hash Aggregate al agrupar por una sola columna entera y devolver el agregado MAX (fecha de pedido). La fórmula debe ser:
Costo de CPU del operador =Utilizando las técnicas que demostré en los artículos anteriores de la serie, obtuve la siguiente fórmula de ingeniería inversa:
Costo de CPU del operador =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087Puede comprobar la precisión de la fórmula mediante las siguientes consultas:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECCIONE orderid % 2000 AS grp, MAX(orderdate) COMO maxod FROM (SELECCIONE TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECCIONE orderid % 3000 AS grp, MAX(orderdate) COMO maxod FROM (SELECCIONE TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECCIONE orderid % 6000 AS grp, MAX(orderdate) COMO maxod FROM (SELECCIONE TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECCIONE orderid % 5000 AS grp, MAX(orderdate) COMO maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
Obtengo los siguientes resultados:
numrows numgroupscostopredichocostoestimado----------- ----------- -------------- ------- ------- 100000 1000 0.703315 0.703316100000 2000 0.721023 0.721024200000 3000 1.40659 1.40659200000 6000 1.45972 1.45972500000 5000 3.44558 3.44558500000 10000 3.53412 3.53412 La fórmula parece ser acertada.Resumen y comparación de costos
Ahora tenemos las fórmulas de cálculo de costos para las tres estrategias disponibles:Stream Aggregate preordenado, Sort + Stream Aggregate y Hash Aggregate. La siguiente tabla resume y compara las características de costeo de los tres algoritmos:
| Agregado de flujo reservado | Ordenar + Stream Agregado | Agregado de hash | |
| Fórmula | @numrows * 0.0000006 + @numgroups * 0.0000005 | 0,0112613 + Pequeño número de filas: 9.99127891201865E-05 + @numrows * REGISTRO(@numrows) * 2.25061348918698E-06 Gran número de filas: 1.35166186417734E-04 + @numrows * REGISTRO(@numrows) * 6.62193536908588E-06 + @numrows * 0.0000006 + @numgroups * 0.0000005 | 0.017749 + @numrows * 0.00000667857 + @numgroups * 0.0000177087
* Agrupación por columna de un solo entero, devolviendo MAX( |
| Escalado | lineal | n registro n | lineal |
| Coste de E/S de inicio | ninguno | 0.0112613 | ninguno |
| Coste de CPU de inicio | ninguno | ~ 0,0001 | 0.017749 |
De acuerdo con estas fórmulas, la Figura 5 muestra la forma en que cada una de las estrategias escala para diferentes números de filas de entrada, usando un número fijo de grupos de 500 como ejemplo.
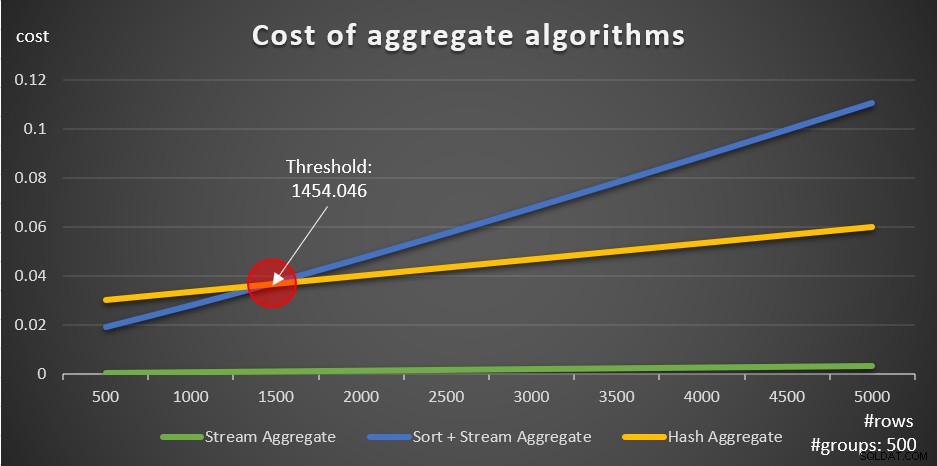
Figura 5:Costo de algoritmos agregados
Puede ver claramente que si los datos están preordenados, por ejemplo, en un índice de cobertura, la estrategia de Stream Aggregate preordenada es la mejor opción, independientemente de cuántas filas estén involucradas. Por ejemplo, suponga que necesita consultar la tabla Pedidos y calcular la fecha máxima de pedido para cada empleado. Creas el siguiente índice de cobertura:
CREAR ÍNDICE idx_eid_od EN dbo.Orders(empid, orderdate);
Aquí hay cinco consultas, que emulan una tabla de pedidos con diferentes números de filas (10 000, 20 000, 30 000, 40 000 y 50 000):
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECCIONE empid, MAX (fecha de pedido) COMO maxod DESDE (SELECCIONE SUPERIOR (20000) * DESDE dbo.Pedidos) COMO D GRUPO POR empid; SELECCIONE empid, MAX (fecha de pedido) COMO maxod DESDE (SELECCIONE SUPERIOR (30000) * DESDE dbo.Pedidos) COMO D GRUPO POR empid; SELECCIONE empid, MAX (fecha de pedido) COMO maxod DESDE (SELECCIONE SUPERIOR (40000) * DESDE dbo.Pedidos) COMO D GRUPO POR empid; SELECCIONE empid, MAX(fechapedido) COMO maxod DESDE (SELECCIONE SUPERIOR (50000) * DESDE dbo.Pedidos) COMO D GRUPO POR empid;
La Figura 6 muestra los planes para estas consultas.
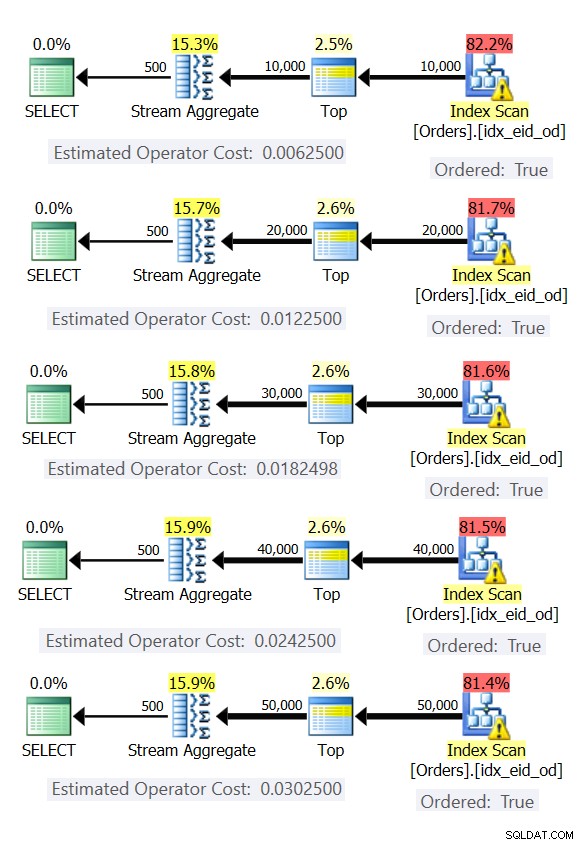
Figura 6:Planes con estrategia Stream Aggregate reservada
En todos los casos, los planes realizan un escaneo ordenado del índice de cobertura y aplican el operador Stream Aggregate sin necesidad de una clasificación explícita.
Utilice el siguiente código para eliminar el índice que creó para este ejemplo:
SUELTA EL ÍNDICE idx_eid_od EN dbo.Orders;
La otra cosa importante a tener en cuenta sobre los gráficos en la Figura 5 es lo que sucede cuando los datos no están ordenados previamente. Esto sucede cuando no hay un índice de cobertura en su lugar, así como cuando agrupa por expresiones manipuladas en lugar de columnas base. Hay un umbral de optimización, en nuestro caso de 1454.046 filas, por debajo del cual la estrategia Sort + Stream Aggregate tiene un costo más bajo, y por encima del cual la estrategia Hash Aggregate tiene un costo más bajo. Esto tiene que ver con el hecho de que el primero tiene un costo de inicio más bajo, pero se escala de manera n log n, mientras que el segundo tiene un costo de inicio más alto pero se escala linealmente. Esto hace que el primero sea el preferido con un pequeño número de filas de entrada. Si nuestras fórmulas de ingeniería inversa son precisas, las siguientes dos consultas (llámelas Consulta 10 y Consulta 11) deberían tener planes diferentes:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
Los planes para estas consultas se muestran en la Figura 7.
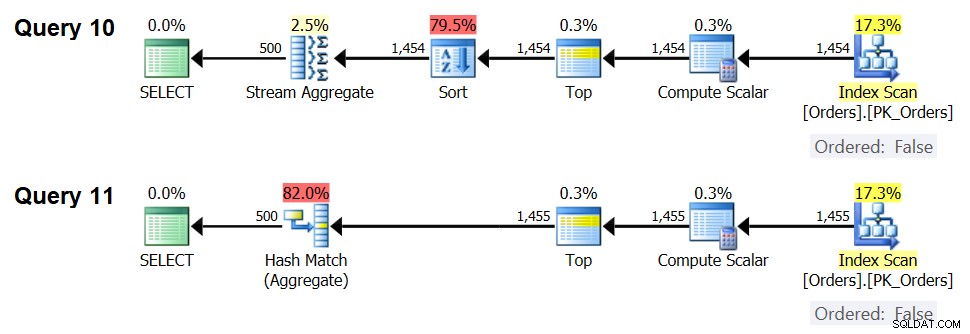
Figura 7:Planes para Consulta 10 y Consulta 11
De hecho, con 1454 filas de entrada (por debajo del umbral de optimización), el optimizador prefiere naturalmente el algoritmo Sort + Stream Aggregate para la Consulta 10, y con 1455 filas de entrada (por encima del umbral de optimización), el optimizador naturalmente prefiere el algoritmo Hash Aggregate para la Consulta 11 .
Potencial para el operador Agregado adaptativo
Uno de los aspectos complicados de los umbrales de optimización son los problemas de rastreo de parámetros cuando se usan consultas sensibles a parámetros en procedimientos almacenados. Considere el siguiente procedimiento almacenado como ejemplo:
CREAR O ALTERAR PROC dbo.EmpOrders @initialorderid AS INTAS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid>=@initialorderid GROUP BY empid;GO
Crea el siguiente índice óptimo para admitir la consulta de procedimiento almacenado:
CREAR ÍNDICE idx_oid_i_eid EN dbo.Orders(orderid) INCLUDE(empid);
Creó el índice con orderid como clave para admitir el filtro de rango de la consulta e incluyó empid para la cobertura. Esta es una situación en la que realmente no puede crear un índice que admita el filtro de rango y tenga las filas filtradas ordenadas previamente por el conjunto de agrupación. Esto significa que el optimizador tendrá que elegir entre los algoritmos Sort + stream Aggregate y Hash Aggregate. Según nuestras fórmulas de costos, el umbral de optimización está entre 937 y 938 filas de entrada (digamos, 937,5 filas).
Suponga que ejecuta el procedimiento almacenado por primera vez con un ID de orden inicial de entrada que le brinda una pequeña cantidad de coincidencias (por debajo del umbral):
EXEC dbo.EmpOrders @initialorderid =999991;
SQL Server produce un plan que utiliza el algoritmo Sort + Stream Aggregate y almacena en caché el plan. Las ejecuciones posteriores reutilizan el plan en caché, independientemente de cuántas filas estén involucradas. Por ejemplo, la siguiente ejecución tiene un número de coincidencias por encima del umbral de optimización:
EXEC dbo.EmpOrders @initialorderid =990001;
Aún así, reutiliza el plan almacenado en caché a pesar de que no es óptimo para esta ejecución. Ese es un problema clásico de rastreo de parámetros.
SQL Server 2017 presenta capacidades de procesamiento de consultas adaptables, que están diseñadas para hacer frente a tales situaciones al determinar durante la ejecución de la consulta qué estrategia emplear. Entre esas mejoras se encuentra un operador de unión adaptable que, durante la ejecución, determina si se activa un algoritmo de bucle o hash en función de un umbral de optimización calculado. Nuestra historia agregada pide un operador de Agregado adaptativo similar, que durante la ejecución elegiría entre una estrategia de Agregado de Ordenación + Flujo y una estrategia de Agregado Hash, en función de un umbral de optimización calculado. La Figura 8 ilustra un pseudoplan basado en esta idea.
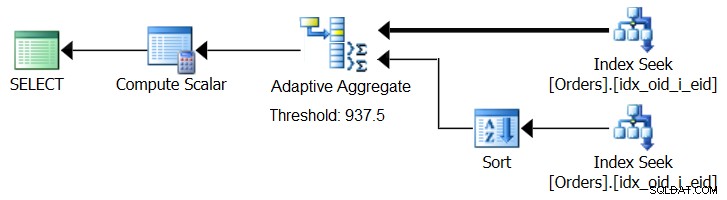
Figura 8:Pseudoplan con operador Agregado adaptativo
Por ahora, para obtener dicho plan, debe usar Microsoft Paint. Pero dado que el concepto de procesamiento de consultas adaptable es tan inteligente y funciona tan bien, es razonable esperar ver más mejoras en esta área en el futuro.
Ejecute el siguiente código para descartar el índice que creó para este ejemplo:
SUELTA EL ÍNDICE idx_oid_i_eid EN dbo.Orders;
Conclusión
En este artículo, cubrí el costo y la escala del algoritmo Hash Aggregate y lo comparé con las estrategias Stream Aggregate y Sort + Stream Aggregate. Describí el umbral de optimización que existe entre las estrategias Sort + Stream Aggregate y Hash Aggregate. Con un pequeño número de filas de entrada, se prefiere el primero y con un gran número, el último. También describí la posibilidad de agregar un operador Agregado adaptativo, similar al operador Combinación adaptativa ya implementado, para ayudar a lidiar con los problemas de rastreo de parámetros cuando se usan consultas sensibles a parámetros. El próximo mes continuaré la discusión cubriendo consideraciones de paralelismo y casos que requieren reescrituras de consultas.