SQL Server Always ON Availability Group es una solución destinada a lograr una alta disponibilidad y recuperación ante desastres para las bases de datos de SQL Server. Podemos configurar esta funcionalidad entre las instalaciones de SQL Server basadas en Windows, las instalaciones de SQL Server basadas en Linux e incluso entre las instalaciones de Linux y SQL Server basadas en Windows juntas.
Los grupos de disponibilidad están estrechamente integrados con las tecnologías de clúster en forma de conmutación por error automática y protección de datos mediante la replicación de datos en sus respectivas réplicas secundarias. Sin embargo, no siempre es obligatorio tener un administrador de recursos de clúster para configurar grupos de disponibilidad.
Para configurar los grupos de disponibilidad de SQL Server, necesitamos WSFC – Clúster de conmutación por error de Windows Server tecnología para Windows instalaciones basadas en SQL Server y PACEMAKER para Linux instalaciones basadas en SQL Server.
MARCAPASOS es un administrador de recursos de clúster de código abierto que podemos usar para administrar recursos y garantizar la disponibilidad del sistema, en caso de que ocurra alguna falla en los sistemas Linux.
WSFC es un producto de Microsoft desarrollado para admitir los requisitos de clústeres basados en Windows.
Cuando observa los grupos de disponibilidad configurados dentro de SQL Server para ambos tipos de SO, parece similar en SQL Server Management Studio.
Sin embargo, este artículo explica los grupos de disponibilidad entre SQL Server basado en Ubuntu Linux instalaciones utilizando el PACEMAKER tecnología de clúster, por lo que solo consideraré esta configuración.
Configuración del tipo de clúster
Como he dicho anteriormente, tenemos tres variantes para configurar Grupos de Disponibilidad para SQL Server, dependiendo del SO:
- entre instalaciones de SQL Server basadas en Windows;
- entre instalaciones de SQL Server basadas en Linux;
- entre el tipo mixto de instalaciones de SQL Server basadas en Windows y Linux.
Microsoft ha introducido el Cluster_type opción de configuración para identificar y configurar una tecnología de clúster adecuada para los grupos de disponibilidad. Es un elemento de configuración que define qué tipo de tecnología de clúster usamos para los grupos de disponibilidad, sin importar en qué sistema operativo se base la instancia de SQL Server.
Puede obtener y validar la configuración existente del tipo de clúster mediante vista de administración dinámica (DMV) de SQL Server sys.availability_groups . Hay dos columnas llamadas cluster_type y cluster_type_desc . Podemos leer estas columnas para definir la configuración del tipo de clúster de la configuración del grupo de disponibilidad.
Esta opción de configuración tiene 3 valores para cumplir con los requisitos de tecnología de clúster para cada variante:
WSFC Debe usar la opción WSFC (clúster de conmutación por error del servidor de Windows) si tiene instalaciones de SQL Server basadas en Windows. No es compatible con instalaciones de SQL Server basadas en Linux.
EXTERNO . Si está configurando grupos de disponibilidad entre instalaciones de SQL Server basadas en Linux, debe usar el administrador de clústeres PACEMAKER y elegir EXTERNAL clúster tipo . El modo de conmutación por error también debe ser EXTERNO (en WSFC será Automático).
NINGUNO . Si no desea utilizar ninguna tecnología de agrupación en clústeres para sus grupos de disponibilidad, seleccione NINGUNO. . Esta opción se aplica si desea configurar grupos de disponibilidad entre instancias de SQL Server basadas en Linux y Windows. Incluso si ha configurado la agrupación en clústeres para su sistema, una vez que establezca el valor del tipo de clúster en NINGUNO, los grupos de disponibilidad no utilizarán la tecnología de clúster. El modo de conmutación por error para el tipo de clúster NINGUNO es siempre Manual .
Una nueva configuración:Secundarios sincronizados requeridos para confirmar
A partir de SQL Server 2017, Microsoft ha introducido una nueva configuración llamada required_synchronized_secondaries_to_commit . Habilita la opción de conmutación por error automática si ha configurado el tipo de clúster como EXTERNO para la configuración del clúster PACEMAKER.
El valor de esta configuración se establece de forma predeterminada cuando configura el agente de recursos de SQL Server mssql-server-ha y cree la configuración del clúster.
Además, puede modificar manualmente el valor según sus requisitos ejecutando el siguiente comando:
--Run below commands to change value for setting required_synchronized_secondaries_to_commit
--AGResourceName is the name of the resource configured for the Availability group
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<Value>
Nota:Podemos cambiar la configuración anterior solo a través de Pacemaker en Linux. Es imposible modificarlo usando la instrucción T-SQL para implementaciones basadas en Linux. Sin embargo, para las implementaciones basadas en Windows, podemos cambiar esta configuración mediante una instrucción T-SQL.
A continuación se muestran los valores posibles para required_synchronized_secondaries_to_commit
Réplicas para participar en un grupo de disponibilidad
La cantidad de réplicas que pueden participar en un grupo de disponibilidad depende de la edición de SQL Server instalada.
- El estándar de SQL Server la edición solo admite réplica de dos nodos para un grupo de disponibilidad junto con la réplica adicional solo de configuración.
- La empresa de SQL Server edición admite hasta nueve réplicas:una principal y ocho réplicas secundarias.
Dado que SQL Server Standard Edition solo admite dos réplicas (una réplica principal y una réplica secundaria), Microsoft ha introducido un nuevo concepto llamado réplica de solo configuración. en SQL Server 2017 CU1 para lograr una conmutación por error automática para servidores SQL que se ejecutan en sistemas Linux.
Hay dos posibles opciones de diseño:
- Tres réplicas sincrónicas. Esta configuración solo se puede implementar con la edición SQL Server Enterprise. Habrá 3 copias de sus bases de datos de disponibilidad. Esta arquitectura permite las 3 funcionalidades:escala de lectura, alta disponibilidad y protección de datos.
- Dos réplicas sincrónicas y una réplica solo de configuración. También puede configurar este diseño con la ayuda de la edición SQL Server Standard, ejecutando dos réplicas síncronas en la edición SQL Server Standard y la 3 réplica en la edición SQL Server Express, que actúa como réplica de solo configuración. Es un diseño rentable que admite alta disponibilidad con conmutación por error automática y protección de la base de datos.
Réplica de dos nodos
Las configuraciones de réplica de dos nodos for Availability Groups es una opción de implementación muy popular para garantizar la alta disponibilidad de las bases de datos de SQL Server. Logramos la conmutación por error automática con la ayuda de la tecnología de clúster de conmutación por error de Windows Server y un testigo de recurso compartido de archivos en las implementaciones de SQL Server basadas en Windows.
El recurso compartido de archivos generalmente se usa en un nodo adicional en WSFC para proporcionar una configuración de quórum para configuraciones de réplica de dos nodos. WSFC sincroniza todos los metadatos de configuración en ambas réplicas y en el tercer nodo o testigo del recurso compartido de archivos para una conmutación por error sin problemas. Todo el arbitraje de conmutación por error para el grupo de disponibilidad de SQL Server basado en Windows ocurre en la capa WSFC.
Si queremos lograr la conmutación por error automática para implementaciones de grupos de disponibilidad de SQL Server basadas en Linux, la configuración anterior no funcionará. Es porque WSFC solo se puede usar para instalaciones de SQL Server basadas en Windows.
Para abordar esta limitación y habilitar la conmutación por error automática para implementaciones de dos réplicas basadas en Linux, Microsoft ha introducido un nuevo concepto.
Réplica solo de configuración
Una réplica solo de configuración es una opción en la que instalamos una instancia adicional de SQL Server en el tercer nodo. Ese nodo funcionará como un servidor testigo para la configuración de réplica de dos nodos para admitir la conmutación por error automática. Podemos crear una réplica de solo configuración por grupo de disponibilidad .
Para instancias de SQL Server basadas en Linux donde usamos el tipo de clúster como EXTERNO para PACEMAKER, el arbitraje de conmutación por error no funciona en la capa de clúster como WSFC. Todo el arbitraje de conmutación por error ocurre en la capa de SQL Server porque todos los metadatos de configuración del grupo de disponibilidad se almacenan en las bases de datos maestras de cada réplica.
Microsoft ha introducido el concepto de réplica solo de configuración para manejar el quórum para los grupos de disponibilidad de SQL Server basados en Linux. Este concepto no aloja ninguna base de datos de usuarios para participar en un grupo de disponibilidad. Almacena toda la información de configuración del grupo de disponibilidad en la base de datos maestra para garantizar que todo el arbitraje de conmutación por error se realice sin problemas.
Puede usar cualquier edición de SQL Server para la réplica de solo configuración. Incluso la edición SQL Server Express se adaptará para ahorrar el costo de su licencia para la tercera réplica. Recuerde, la réplica de solo configuración no hospedará ninguna base de datos dentro del grupo de disponibilidad. Por lo tanto, tendrá solo dos copias de bases de datos en un grupo de disponibilidad.
De forma predeterminada, required_synchronized_secondaries_to_commit está establecido en 0 cuando usamos la réplica de solo configuración. Podemos modificar manualmente este valor a 1 si es necesario.
Eche un vistazo al diagrama de diseño de la réplica síncrona de dos nodos y una réplica solo de configuración para lograr la conmutación automática por error y la protección de datos.
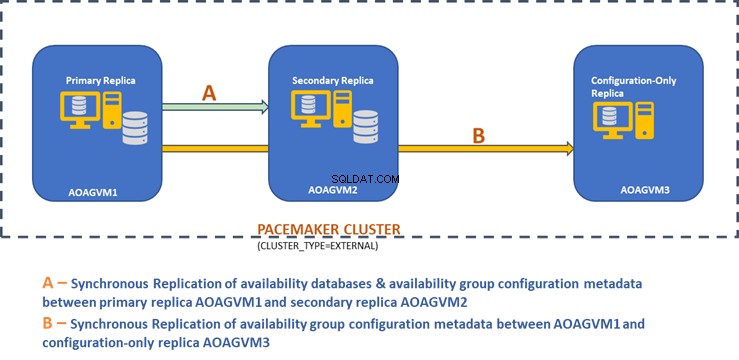
Podemos ver que hay 3 máquinas virtuales llamadas AOAGVM1, AOAGVM2 y AOAGVM3. Todos se ejecutan en el sistema Ubuntu Linux y SQL Server está configurado en los tres sistemas Linux. Las bases de datos de disponibilidad están alojadas en AOAGVM1 y AOAGVM2.
AOAGVM1 actúa como una réplica principal, mientras que AOAGVM2 es una réplica secundaria. AOAGVM3 sirve como réplica solo de configuración, que es la edición SQL Server Express. No hay bases de datos de usuarios alojadas en esta tercera réplica.
El clúster de Pacemaker se ha configurado entre los tres nodos para admitir la tecnología de clúster para la configuración del grupo de disponibilidad basado en Linux.
Para configurar o implementar el diseño anterior, debemos realizar los siguientes pasos:
- Instale SQL Server en tres sistemas Ubuntu (la edición SQL Server Express se adaptará a la réplica de solo configuración).
- Configure grupos de disponibilidad entre tres nodos.
- Configure el clúster PACEMAKER entre tres nodos.
- Agregue o integre el grupo de disponibilidad como un recurso en el grupo de clústeres.
Eche un vistazo al artículo relacionado para completar el paso 1 (instalación de instancias de SQL Server en tres nodos).
Estén atentos a mi próximo artículo donde explicaré el proceso paso a paso para implementar el diseño anterior. Nuestro objetivo será lograr la conmutación automática por error y la protección de datos mediante la réplica síncrona de 2 nodos y una réplica solo de configuración.
Estaremos encantados de escuchar sus pensamientos y consejos prácticos sobre este asunto. Siéntete libre de compartirlos en la sección de Comentarios.