Ya cubrimos algo de teoría sobre la configuración de grupos de disponibilidad Always ON para servidores SQL basados en Linux. El artículo actual se centrará en la práctica.
Vamos a presentar el proceso paso a paso para configurar los grupos de disponibilidad Always ON de SQL Server entre dos réplicas sincrónicas. Además, destacaremos el uso de la réplica solo de configuración para realizar una conmutación por error automática.
Antes de comenzar, le recomendaría que consulte el artículo anterior y actualice sus conocimientos.
El siguiente diagrama de diseño muestra la réplica síncrona de dos nodos y una réplica solo de configuración que nos ayudan a garantizar la conmutación automática por error y la protección de datos.
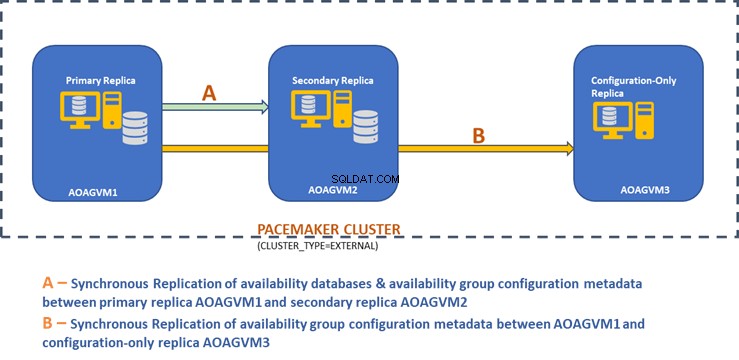
Exploramos este diseño en el artículo mencionado anteriormente, así que consúltelo para obtener información antes de continuar con las tareas prácticas.
Instalar SQL Server en sistemas Ubuntu
El diagrama de diseño anterior menciona 3 sistemas Ubuntu:aoagvm1 , aoagvm2 y aoagvm3 con las instancias de SQL Server instaladas. Consulte las instrucciones sobre cómo instalar SQL Server en Ubuntu:el ejemplo se relaciona con SQL Server 2019 en el sistema Ubuntu 18.04. Puede continuar e instalar SQL Server 2019 en los 3 nodos (asegúrese de instalar la misma versión de compilación).
Para ahorrar costos de licencia, puede instalar la edición SQL Server Express para la réplica del tercer nodo. Esta funcionará como una réplica solo de configuración sin alojar ninguna base de datos de disponibilidad.
Una vez que SQL Server está instalado en los 3 nodos, podemos configurar el grupo de disponibilidad entre ellos.
Configurar grupos de disponibilidad entre tres nodos
Antes de continuar, valide su entorno:
- Asegúrese de que haya comunicación entre los 3 nodos.
- Verifique y actualice el nombre de la computadora para cada host ejecutando el comando sudo vi /etc/hostname
- Actualice el archivo de host con la dirección IP y los nombres de nodo para cada nodo. Puede usar el comando sudo vi /etc/hosts para hacer esto
- Asegúrese de tener todas las instancias ejecutándose más allá de SQL Server 2017 CU1 si no está utilizando SQL Server 2019
Ahora, comencemos a configurar el grupo de disponibilidad Always ON de SQL Server entre 3 nodos. Necesitamos habilitar la función de grupo de disponibilidad en los 3 nodos.
Ejecute el siguiente comando (tenga en cuenta que debe reiniciar el servicio de SQL Server después de esa acción):
--Enable Availability Group feature
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
--Restart SQL Server service
sudo systemctl restart mssql-server
He ejecutado el comando anterior en el nodo principal. Debe repetirse para los dos nodos restantes.
El resultado está debajo:ingrese el nombre de usuario y la contraseña cuando se le solicite.
example@sqldat.com:~$ sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
SQL Server needs to be restarted to apply this setting. Please run
'systemctl restart mssql-server.service'.
example@sqldat.com:~$ systemctl restart mssql-server
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to restart 'mssql-server.service'.
Authenticating as: Ubuntu (aoagvm1)
Password:
El siguiente paso es habilitar los Eventos extendidos siempre activados para cada instancia de SQL Server. Aunque este es un paso opcional, debe habilitarlo para solucionar cualquier problema que pueda surgir más adelante. Conéctese a la instancia de SQL Server usando SQLCMD y ejecuta el siguiente comando:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
Go
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
Go
El resultado es el siguiente:
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
2>GO
1>
Una vez que habilite esta opción en el nodo de réplica principal, haga lo mismo con los nodos aoagvm2 y aoagvm3 restantes.
Las instancias de SQL Server que se ejecutan en Linux usan certificados para autenticar la comunicación entre los puntos finales de creación de reflejo. Entonces, la siguiente opción es crear el certificado en la réplica principal aoagvm1 .
Primero, creamos una clave maestra y un certificado. Luego hacemos una copia de seguridad de este certificado en un archivo y aseguramos el archivo con una clave privada. Ejecute el siguiente script T-SQL en el nodo de réplica principal:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
--Configure Certificates
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk',ENCRYPTION BY PASSWORD = 'example@sqldat.com');
La salida:
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
2>CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
3>GO
1>BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
2>WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk',ENCRYPTION BY PASSWORD = 'example@sqldat.com');
3>GO
1>
El nodo de réplica principal ahora tiene dos archivos nuevos. Uno es el archivo de certificado dbm_certificate.cer y el archivo de clave privada dbm_certificate.pvk en el /var/opt/mssql/data/ ubicación.
Copie los dos archivos anteriores en la misma ubicación en los dos nodos restantes (AOAGVM2 y AOAGVM3) que participarán en la configuración del grupo de disponibilidad. Puede usar el comando SCP o cualquier utilidad de terceros para copiar estos dos archivos en el servidor de destino.
Una vez que los archivos se copian en los dos nodos restantes, asignaremos permisos a mssql usuario para acceder a estos archivos en los 3 nodos. Para eso, ejecute el siguiente comando y luego ejecútelo para el tercer nodo aoagvm3 también:
--Copy files to aoagvm2 node
cd /var/opt/mssql/data
scp dbm_certificate.* example@sqldat.com:var/opt/mssql/data/
--Grant permission to user mssql to access both newly created files
cd /var/opt/mssql/data
chown mssql:mssql dbm_certificate.*
Crearemos la clave maestra y los archivos de certificado con la ayuda de los dos archivos anteriores copiados en los dos nodos restantes aoagvm2 y aoagvm3 . Ejecute el siguiente comando en esos dos nodos para crear la clave maestra :
--Create master key and certificate on remaining two nodes
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
CREATE CERTIFICATE dbm_certificate
FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = 'example@sqldat.com');
He ejecutado el comando anterior en el segundo nodo aoagvm2 para crear la clave maestra y certificado . Echa un vistazo a la salida de ejecución. Asegúrese de utilizar las mismas contraseñas que cuando creó y realizó una copia de seguridad del certificado y la clave maestra.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
2>CREATE CERTIFICATE dbm_certificate
3>FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
4>WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = 'example@sqldat.com');
5>GO
1>
Ejecute el comando anterior en el AOAGVM3 nodo también.
Ahora, configuramos los extremos de la creación de reflejo de la base de datos; antes creamos certificados para ellos. El punto final de duplicación llamado hadr_endpoint debe estar en los 3 nodos según su tipo de rol respectivo.
Como las bases de datos de disponibilidad están alojadas en solo 2 nodos aoagvm1 y aoagvm2, ejecutaremos la siguiente declaración solo en esos nodos. El tercer nodo actuará como testigo, por lo que simplemente cambiaremos FUNCIÓN. ser testigo en el siguiente script y luego ejecute T-SQL en el tercer nodo aoagvm3 . El guión es:
--Configure database mirroring endpoint Hadr_endpoint on nodes aoagvm1 and aoagvm2
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES);
--Start the newly created endpoint
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
Este es el resultado del comando anterior en el nodo de réplica principal. Me he conectado a sqlcmd y lo ejecutó. Asegúrese de hacer lo mismo en el segundo nodo de réplica aoagvm2 también.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE ENDPOINT [Hadr_endpoint]
2>AS TCP (LISTENER_PORT = 5022)
3>FOR DATABASE_MIRRORING (ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES);
4>Go
1>ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
2>Go
1>
Una vez que haya ejecutado el script T-SQL anterior en los primeros 2 nodos, debemos modificarlo para el tercer nodo:cambie el ROL a WITNESS.
Ejecute el siguiente script para crear el punto final de creación de reflejo de la base de datos en el nodo testigo AOAGVM3 . Si desea alojar bases de datos de disponibilidad allí, ejecute también el comando anterior en el nodo de 3 réplicas. Pero asegúrese de haber instalado la edición correcta de SQL Server para lograr esta capacidad.
Si instaló la edición SQL Server Express en el nodo 3 para implementar solo configuración réplica , solo puede configurar FUNCIÓN como testigo para este nodo:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
----Configure database mirroring endpoint Hadr_endpoint on 3rd node aoagvm3
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (ROLE = WITNESS, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES);
--Start the newly created endpoint on aoagvm3
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
Ahora tenemos que crear el grupo de disponibilidad llamado ag1 .
Conéctese a la instancia de SQL Server mediante sqlcmd y ejecute el siguiente comando en el nodo de réplica principal aoagvm1 :
--Connect to the local SQL Server instance using sqlcmd hosted on primary replica node aoagvm1
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
--Create availability group ag1
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'aoagvm1’ WITH (ENDPOINT_URL = N'tcp://aoagvm1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC),
N'aoagvm2' WITH (ENDPOINT_URL = N'tcp://aoagvm2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC),
N'aoagvm3' WITH (ENDPOINT_URL = N'tcp://aoagvm3:5022',
AVAILABILITY_MODE = CONFIGURATION_ONLY);
--Assign required permission
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
El script anterior configura réplicas de grupos de disponibilidad con los siguientes parámetros de configuración (acabamos de usarlos en el script T-SQL):
- CLUSTER_TYPE =EXTERNO porque estamos configurando un grupo de disponibilidad en instalaciones de SQL Server basadas en Linux
- MODO_SIEMBRA =AUTOMÁTICO hace que SQL Server cree automáticamente una base de datos en cada réplica secundaria. Las bases de datos de disponibilidad no se crearán en la réplica de solo configuración
- FAILOVER_MODE =EXTERNO tanto para réplicas primarias como secundarias. significa que la réplica interactúa con un administrador de recursos de clúster externo, como Pacemaker
- MODO_DISPONIBILIDAD =COMPROMISO_SINCRONICO para réplicas primarias y secundarias para conmutación por error automática
- MODO_DISPONIBILIDAD =CONFIGURACIÓN_SÓLO para la tercera réplica que funciona como una réplica de solo configuración
También necesitamos crear un inicio de sesión de Pacemaker en todas las instancias de SQL Server. Este usuario debe tener asignado el ALTER , CONTROL y VER DEFINICIÓN permisos en el grupo de disponibilidad en todas las réplicas. Para otorgar permisos, ejecute el siguiente script T-SQL en los 3 nodos de réplica inmediatamente. Primero, crearemos un inicio de sesión de Pacemaker. Luego, asignaremos los permisos anteriores a ese inicio de sesión.
--Create pacemaker login on each SQL Server instance. Run below commands on all 3 SQL Server instances
CREATE LOGIN pacemaker WITH PASSWORD = 'example@sqldat.com@12'
--Grant permission to pacemaker login on newly created availability group. Run it on all 3 SQL Server instances
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemaker
GRANT VIEW SERVER STATE TO pacemaker
Después de asignar los permisos apropiados al inicio de sesión de Pacemaker en las 3 réplicas, ejecutamos los siguientes scripts T-SQL para unir las réplicas secundarias aoagvm2 y aoagvm3 al grupo de disponibilidad recién creado ag1 . Ejecute los siguientes comandos en las réplicas secundarias aoagvm2 y aoagvm3 .
--Execute below commands on aoagvm2 and aoagvm3 to join availability group ag1
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
A continuación se muestra el resultado de las ejecuciones anteriores en el nodo aoagvm2 . Asegúrese de ejecutarlo en aoagvm3 nodo también.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
2>Go
1>ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
2>Go
1>
Así, hemos configurado el Grupo de disponibilidad. Ahora, necesitamos agregar un usuario o una base de datos de prueba a este grupo de disponibilidad. Si ya ha creado una base de datos de usuario en la réplica del nodo principal, simplemente ejecute una copia de seguridad completa y luego deje que la inicialización automática la restaure en el nodo secundario.
Por lo tanto, ejecute el siguiente comando:
--Run a full backup of test database or user database hosted on primary replica aoagvm1
BACKUP DATABASE [Test] TO DISK = N'/var/opt/mssql/data/Test_15June.bak';
Agreguemos esta base de datos Prueba al grupo de disponibilidad ag1 . Ejecute la siguiente instrucción T-SQL en el nodo principal aoagvm1 . Puede utilizar sqlcmd utilidad para ejecutar sentencias T-SQL.
--Add user database or test database to the availability group ag1
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [Test];
Puede verificar la base de datos de usuario o una base de datos de prueba que haya agregado al grupo de disponibilidad buscando en la instancia secundaria de SQL Server, ya sea que se haya creado en réplicas secundarias o no. Puede usar SQL Server Management Studio o ejecutar una declaración T-SQL simple para obtener los detalles sobre esta base de datos.
--Verify test database is created on a secondary replica or not. Run it on secondary replica aoagvm2.
SELECT * FROM sys.databases WHERE name = 'Test';
GO
Obtendrá la Prueba base de datos creada en la réplica secundaria.
Con el paso anterior, el grupo de disponibilidad AlwaysOn se ha configurado entre los tres nodos. Sin embargo, estos nodos aún no están agrupados. Nuestro siguiente paso es instalar el marcapasos agruparse en ellos. Luego agregaremos el Grupo de disponibilidad ag1 como recurso para ese clúster.
Configuración de clúster de PACEMAKER entre tres nodos
Por lo tanto, utilizaremos un administrador de recursos de clúster externo PACEMAKER entre los 3 nodos para soporte de clúster. Comencemos habilitando los puertos de firewall entre los 3 nodos.
Abra los puertos del cortafuegos con el siguiente comando:
--Run the below commands on all 3 nodes to open Firewall Ports
sudo ufw allow 2224/tcp
sudo ufw allow 3121/tcp
sudo ufw allow 21064/tcp
sudo ufw allow 5405/udp
sudo ufw allow 1433/tcp
sudo ufw allow 5022/tcp
sudo ufw reload
--If you don't want to open specific firewall ports then alternatively you can disable the firewall on all 3 nodes by running the below command (THIS IS ALTERNATE & OPTIONAL APPROACH)
sudo ufw disable
Vea el resultado:este es de la réplica principal AOAGVM1 . Debe ejecutar los comandos anteriores en los tres nodos, uno por uno. El resultado debería ser similar.
example@sqldat.com:~$ sudo ufw allow 2224/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 3121/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 21064/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 5405/udp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 1433/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 5022/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw reload
Firewall not enabled (skipping reload)
Instalar marcapasos y corosync paquetes en los 3 nodos. Ejecute el siguiente comando en cada nodo:configurará Marcapasos , corosync y agente de esgrima .
--Install Pacemaker packages on all 3 nodes aoagvm1, aoagvm2 and aoagvm3 by running the below command
sudo apt-get install pacemaker pcs fence-agents resource-agents
La salida es enorme – casi 20 páginas. He copiado la primera y la última línea para ilustrarlo (puedes ver todos los paquetes instalados):
example@sqldat.com:~$ sudo apt-get install pacemaker pcs fence-agents resource-agents
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
cluster-glue corosync fonts-dejavu-core fonts-lato fonts-liberation ibverbs-providers javascript-common libcfg6 libcib4 libcmap4 libcorosync-common4 libcpg4
libcrmcluster4 libcrmcommon3 libcrmservice3 libdbus-glib-1-2 libesmtp6 libibverbs1 libjs-jquery liblrm2 liblrmd1 libnet-telnet-perl libnet1 libnl-3-200
libnl-route-3-200 libnspr4 libnss3 libopenhpi3 libopenipmi0 libpe-rules2 libpe-status10 libpengine10 libpils2 libplumb2 libplumbgpl2 libqb0 libquorum5 librdmacm1
libruby2.5 libsensors4 libsgutils2-2 libsnmp-base libsnmp30 libstatgrab10 libstonith1 libstonithd2 libtimedate-perl libtotem-pg5 libtransitioner2 libvotequorum8
libxml2-utils openhpid pacemaker-cli-utils pacemaker-common pacemaker-resource-agents python-pexpect python-ptyprocess python-pycurl python3-bs4 python3-html5lib
python3-lxml python3-pycurl python3-webencodings rake ruby ruby-activesupport ruby-atomic ruby-backports ruby-did-you-mean ruby-ethon ruby-ffi ruby-highline
ruby-i18n ruby-json ruby-mime-types ruby-mime-types-data ruby-minitest ruby-multi-json ruby-net-telnet ruby-oj ruby-open4 ruby-power-assert ruby-rack
ruby-rack-protection ruby-rack-test ruby-rpam-ruby19 ruby-sinatra ruby-sinatra-contrib ruby-test-unit ruby-thread-safe ruby-tilt ruby-tzinfo ruby2.5
rubygems-integration sg3-utils snmp unzip xsltproc zip
Suggested packages:
ipmitool python-requests python-suds apache2 | lighttpd | httpd lm-sensors snmp-mibs-downloader python-pexpect-doc libcurl4-gnutls-dev python-pycurl-dbg
python-pycurl-doc python3-genshi python3-lxml-dbg python-lxml-doc python3-pycurl-dbg ri ruby-dev bundler
The following NEW packages will be installed:
cluster-glue corosync fence-agents fonts-dejavu-core fonts-lato fonts-liberation ibverbs-providers javascript-common libcfg6 libcib4 libcmap4 libcorosync-common4
libcpg4 libcrmcluster4 libcrmcommon3 libcrmservice3 libdbus-glib-1-2 libesmtp6 libibverbs1 libjs-jquery liblrm2 liblrmd1 libnet-telnet-perl libnet1 libnl-3-200
libnl-route-3-200 libnspr4 libnss3 libopenhpi3 libopenipmi0 libpe-rules2 libpe-status10 libpengine10 libpils2 libplumb2 libplumbgpl2 libqb0 libquorum5 librdmacm1
libruby2.5 libsensors4 libsgutils2-2 libsnmp-base libsnmp30 libstatgrab10 libstonith1 libstonithd2 libtimedate-perl libtotem-pg5 libtransitioner2 libvotequorum8
libxml2-utils openhpid pacemaker pacemaker-cli-utils pacemaker-common pacemaker-resource-agents pcs python-pexpect python-ptyprocess python-pycurl python3-bs4
python3-html5lib python3-lxml python3-pycurl python3-webencodings rake resource-agents ruby ruby-activesupport ruby-atomic ruby-backports ruby-did-you-mean
ruby-ethon ruby-ffi ruby-highline ruby-i18n ruby-json ruby-mime-types ruby-mime-types-data ruby-minitest ruby-multi-json ruby-net-telnet ruby-oj ruby-open4
ruby-power-assert ruby-rack ruby-rack-protection ruby-rack-test ruby-rpam-ruby19 ruby-sinatra ruby-sinatra-contrib ruby-test-unit ruby-thread-safe ruby-tilt
ruby-tzinfo ruby2.5 rubygems-integration sg3-utils snmp unzip xsltproc zip
0 upgraded, 103 newly installed, 0 to remove and 2 not upgraded.
Need to get 19.6 MB of archives.
After this operation, 86.0 MB of additional disk space will be used.
Do you want to continue? [Y/n] Y
Get:1 https://azure.archive.ubuntu.com/ubuntu bionic/main amd64 fonts-lato all 2.0-2 [2698 kB]
Get:2 https://azure.archive.ubuntu.com/ubuntu bionic/main amd64 libdbus-glib-1-2 amd64 0.110-2 [58.3 kB]
…………
--------
Una vez que el marcapasos la instalación del clúster ha finalizado, el hacluster el usuario se completará automáticamente mientras ejecuta el siguiente comando:
example@sqldat.com:~$ cat /etc/passwd|grep hacluster
hacluster:x:111:115::/var/lib/pacemaker:/usr/sbin/nologin
Ahora, podemos establecer la contraseña para el usuario predeterminado creado durante la instalación de Pacemaker y el Corosync paquetes Asegúrese de usar la misma contraseña en los 3 nodos. Utilice el siguiente comando:
--Set default user password on all 3 nodes
sudo passwd hacluster
Introduzca la contraseña cuando se le solicite:
example@sqldat.com:~$ sudo passwd hacluster
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
El siguiente paso es habilitar e iniciar el pcsd servicio y marcapasos en los 3 nodos. Permite que los 3 nodos se unan al clúster después de reiniciar. Ejecute el siguiente comando en los 3 nodos para realizar este paso:
--Enable and start pcsd service and pacemaker
sudo systemctl enable pcsd
sudo systemctl start pcsd
sudo systemctl enable pacemaker
Ver la ejecución en la réplica principal aoagvm1 . Asegúrese de ejecutarlo también en los dos nodos restantes.
--Enable pcsd service
example@sqldat.com:~$ sudo systemctl enable pcsd
Synchronizing state of pcsd.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pcsd
--Start pcsd service
example@sqldat.com:~$ sudo systemctl start pcsd
--Enable Pacemaker
example@sqldat.com:~$ sudo systemctl enable pacemaker
Synchronizing state of pacemaker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pacemaker
Hemos configurado el Marcapasos paquetes Ahora creamos un clúster.
Primero, asegúrese de no tener ningún clúster configurado previamente en esos sistemas. Puede destruir cualquier configuración de clúster existente de todos los nodos ejecutando los siguientes comandos. Tenga en cuenta que la eliminación de cualquier configuración de clúster detendrá todos los servicios de clúster y deshabilitará el marcapasos servicio:debe volver a habilitarse.
--Destroy previously configured clusters to clean the systems
sudo pcs cluster destroy
--Reenable Pacemaker
sudo systemctl enable pacemaker
A continuación se muestra el resultado del nodo de réplica principal aoagvm1 .
--Destroy previously configured clusters to clean the systems
example@sqldat.com:~$ sudo pcs cluster destroy
Shutting down pacemaker/corosync services...
Killing any remaining services...
Removing all cluster configuration files...
--Reenable Pacemaker
example@sqldat.com:~$ sudo systemctl enable pacemaker
Synchronizing state of pacemaker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pacemaker
A continuación, creamos el clúster de 3 nodos entre los 3 nodos de la réplica principal aoagvm1 . Importante :ejecute los siguientes comandos solo desde su nodo principal !
--Create cluster. Modify below command with your node names, hacluster password and clustername
sudo pcs cluster auth <node1> <node2> <node3> -u hacluster -p <password for hacluster>
sudo pcs cluster setup --name <clusterName> <node1> <node2...> <node3>
sudo pcs cluster start --all
sudo pcs cluster enable --all
Vea el resultado en el nodo de réplica principal:
example@sqldat.com:~$ sudo pcs cluster auth aoagvm1 aoagvm2 aoagvm3 -u hacluster -p hacluster
aoagvm1: Authorized
aoagvm2: Authorized
aoagvm3: Authorized
example@sqldat.com:~$ sudo pcs cluster setup --name aoagvmcluster aoagvm1 aoagvm2 aoagvm3
Destroying cluster on nodes: aoagvm1, aoagvm2, aoagvm3...
aoagvm1: Stopping Cluster (pacemaker)...
aoagvm2: Stopping Cluster (pacemaker)...
aoagvm3: Stopping Cluster (pacemaker)...
aoagvm1: Successfully destroyed cluster
aoagvm2: Successfully destroyed cluster
aoagvm3: Successfully destroyed cluster
Sending 'pacemaker_remote authkey' to 'aoagvm1', 'aoagvm2', 'aoagvm3'
aoagvm1: successful distribution of the file 'pacemaker_remote authkey'
aoagvm2: successful distribution of the file 'pacemaker_remote authkey'
aoagvm3: successful distribution of the file 'pacemaker_remote authkey'
Sending cluster config files to the nodes...
aoagvm1: Succeeded
aoagvm2: Succeeded
aoagvm3: Succeeded
Synchronizing pcsd certificates on nodes aoagvm1, aoagvm2, aoagvm3...
aoagvm1: Success
aoagvm2: Success
aoagvm3: Success
Restarting pcsd on the nodes to reload the certificates...
aoagvm1: Success
aoagvm2: Success
aoagvm3: Success
example@sqldat.com:~$ sudo pcs cluster start --all
aoagvm1: Starting Cluster...
aoagvm2: Starting Cluster...
aoagvm3: Starting Cluster...
example@sqldat.com:~$ sudo pcs cluster enable --all
aoagvm1: Cluster Enabled
aoagvm2: Cluster Enabled
aoagvm3: Cluster Enabled
Esgrima es una de las configuraciones esenciales al usar el clúster PACEMAKER en producción. Debe configurar vallas para su clúster para asegurarse de que no se dañen los datos en caso de interrupciones .
Hay dos tipos de implementación de cercas:
- Nivel de recursos – asegura que un nodo no puede usar uno o más recursos.
- Nivel de nodo – asegura que un nodo no ejecute ningún recurso en absoluto.
Generalmente usamos STONITH como configuración de cercado:el cercado a nivel de nodo para PACEMAKER .
Cuando MARCAPASOS no puede determinar el estado de un nodo o un recurso en un nodo, la cerca lleva el clúster a un estado conocido nuevamente. Para lograr esto, PACEMAKER requiere que habilitemos STONITH , que significa Dispara al otro nodo en la cabeza .
No nos centraremos en la configuración de vallas en este artículo porque la configuración de vallas a nivel de nodo depende en gran medida del entorno individual. Para nuestro escenario, lo deshabilitaremos ejecutando el siguiente comando:
--Disable fencing (STONITH)
sudo pcs property set stonith-enabled=false
Sin embargo, si tiene previsto utilizar marcapasos en un entorno de producción, debe planificar la implementación de STONITH según su entorno y mantenerla habilitada.
A continuación, estableceremos algunas propiedades esenciales del clúster:cluster-recheck-interval, start-failure-is-fatal, y fallo-tiempo de espera .
Según MSDN, si fallo-tiempo de espera se establece en 60 segundos y cluster-recheck-interval está configurado en 120 segundos, el reinicio se intenta en un intervalo mayor a 60 segundos pero menor a 120 segundos. Microsoft recomienda establecer un valor para cluster-recheck-interval mayor que el valor de failure-timeout . Otra configuración start-failure-is-fatal debe establecerse como verdadero . De lo contrario, el clúster no iniciará la conmutación por error de la réplica principal a su réplica secundaria respectiva, en caso de que se produzcan interrupciones permanentes.
Ejecute los siguientes comandos para configurar las 3 propiedades importantes del clúster:
--Set cluster property cluster-recheck-interval to 2 minutes
sudo pcs property set cluster-recheck-interval=2min
--Set start-failure-is-fatal to True
sudo pcs property set start-failure-is-fatal=true
--Set failure-timeout to 60 seconds. Ag1 is the name of the availability group. Change this name with your availability group name.
pcs resource update ag1 meta failure-timeout=60s
Integre el grupo de disponibilidad en el grupo de clústeres de marcapasos
Aquí, nuestro objetivo es describir el proceso de integración del grupo de disponibilidad recién creado ag1 al nuevo marcapasos grupo de clústeres.
Primero, instalaremos el agente de recursos de SQL Server para la integración con Pacemaker en los 3 nodos:
--Install SQL Server Resource Agent on all 3 nodes
sudo apt-get install mssql-server-ha
He ejecutado el comando anterior en los 3 nodos. Vea el resultado a continuación (tomado de aoagvm1 ):
--Install SQL Server resource agent for integration with Pacemaker
example@sqldat.com:~$ sudo apt-get install mssql-server-ha
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
mssql-server-ha
0 upgraded, 1 newly installed, 0 to remove, and 2 not upgraded.
Need to get 1486 kB of archives.
After this operation, 9151 kB of additional disk space will be used.
Get:1 https://packages.microsoft.com/ubuntu/16.04/mssql-server-preview xenial/main amd64 mssql-server-ha amd64 15.0.1600.8-1 [1486 kB]
Fetched 1486 kB in 0s (4187 kB/s)
Selecting previously unselected package mssql-server-ha.
(Reading database ... 90430 files and directories currently installed.)
Preparing to unpack .../mssql-server-ha_15.0.1600.8-1_amd64.deb ...
Unpacking mssql-server-ha (15.0.1600.8-1) ...
Setting up mssql-server-ha (15.0.1600.8-1) ...
Repita los pasos anteriores en los 2 nodos restantes.
Ya hemos creado el Marcapasos inicie sesión en todas las instancias de SQL Server alojadas en 3 nodos cuando hayamos configurado el grupo de disponibilidad ag1 . Ahora, asignamos el rol de administrador del sistema en las 3 instancias de SQL Server. Puede conectarse usando sqlcmd para ejecutar este comando T-SQL. Si no ha creado el Marcapasos login, you can run the below command to do it.
--Create a pacemaker login if you missed creating it in the above section.
USE master
Go
CREATE LOGIN pacemaker WITH PASSWORD = 'example@sqldat.com@12'
Go
--Assign sysadmin role to pacemaker login on all 3 nodes. Run this T-SQL on all 3 SQL Server instances.
ALTER SERVER ROLE [sysadmin] ADD MEMBER [pacemaker]
We must save the above SQL Server Pacemaker login and its credentials on all 3 nodes. Run the below command there:
--Save pacemaker login credentials on all 3 nodes by executing below commands on each node
echo 'pacemaker' >> ~/pacemaker-passwd
echo 'example@sqldat.com@12' >> ~/pacemaker-passwd
sudo mv ~/pacemaker-passwd /var/opt/mssql/secrets/passwd
sudo chown root:root /var/opt/mssql/secrets/passwd
sudo chmod 400 /var/opt/mssql/secrets/passwd
We will create the Availability Group Resource as master/subordinate .
We are using the pcs resource create command to create the Availability Group resource and set its properties. The following command will create the ocf:mssql:ag resource for the Availability Group ag1 .
The Pacemaker resource agent automatically sets the value of REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT on the Availability Group based on the Availability Group’s configuration during the creation of the Availability Group resource.
Execute the below command:
--Create availability group resource ocf:mssql:ag
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=ag1 meta failure-timeout=30s --master meta notify=true
Next, we create a virtual IP resource in Pacemaker . Ensure you have the unused private IP address from your network . Replace the IP value with your virtual IP address. This IP will point to the primary replica and you can use it to make databases connections with active nodes.
The command is below:
--Configure virtual IP resource
sudo pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=10.50.0.7
We are adding the colocation constraint and ordering constraint to the Pacemaker cluster configuration . These constraints help the virtual IP resource to make decisions on resources, e.g., where they should run.
Constraints have some scores, and Pacemaker uses these scores to make decisions. Scores are calculated per resource. The cluster resource manager chooses the node with the highest score for a particular resource.
The colocation constraint has an implicit ordering constraint . We need to add an ordering constraint to prevent the IP address from temporarily pointing to the node with the pre-failover secondary . Ordering constraint ensures the cluster comes online in a particular sequential manner.
Run the below commands to add colocation constraint and ordering constraint to the cluster.
--Add colocation constraint
sudo pcs constraint colocation add virtualip ag_cluster-master INFINITY with-rsc-role=Master
--Add ordering constraint
sudo pcs constraint order promote ag_cluster-master then start virtualip
Hence, Two-Node Synchronous Replicas (aoagvm1 &aoagvm2) and a Configuration-Only Replica (aoagvm3) on PACEMAKER Cluster between 3-Node Ubuntu Systems has been completed.
We can test the configuration to validate the automatic failover. Run the below command to check the status of the Pacemaker grupo. The command also initiates the Availability Group failover.
Remember, once you couple your Availability Group with the PACEMAKER cluster, you cannot use T-SQL statements to initiate the Availability Group failovers. You can also shut down the primary replica to initiate the automatic failover.
The command is the following:
--Validate the PACEMAKER cluster configuration
sudo pcs status
--Initiate availability group failover to verify AOAG configuration
sudo pcs resource move ag_cluster-master aoagvm2 –master
Conclusión
This article was meant to help you understand the configuration of the Two-Node Synchronous Replicas and a Configuration-Only Replica on PACEMAKER Cluster. We hope that you got useful information that will help you in your workflow.
Always plan all steps carefully and do proper testing in a lower life cycle before deploying to your production environment.
We’ll be glad to hear your thoughts about this topic. Feel free to leave your feedback in a comment section.