Almacenar ~3,5 TB de datos e insertar alrededor de 1 K/s 24x7, y también consultar a una velocidad no especificada, es posible con SQL Server, pero hay más preguntas:
- ¿Qué requisito de disponibilidad tiene para esto? ¿99,999 % de tiempo de actividad o es suficiente el 95 %?
- ¿Qué requisito de confiabilidad tiene? ¿Le cuesta un millón de dólares perder un inserto?
- ¿Qué requisito de recuperabilidad tiene? Si pierde un día de datos, ¿importa?
- ¿Qué requisito de consistencia tienes? ¿Es necesario garantizar que una escritura sea visible en la próxima lectura?
Si necesita todos estos requisitos que destaqué, la carga que propone costará millones en hardware y licencias en un sistema relacional, cualquier sistema, sin importar los trucos que pruebe (fragmentación, partición, etc.). Un sistema nosql, por su propia definición, no cumpliría con todos estos requisitos.
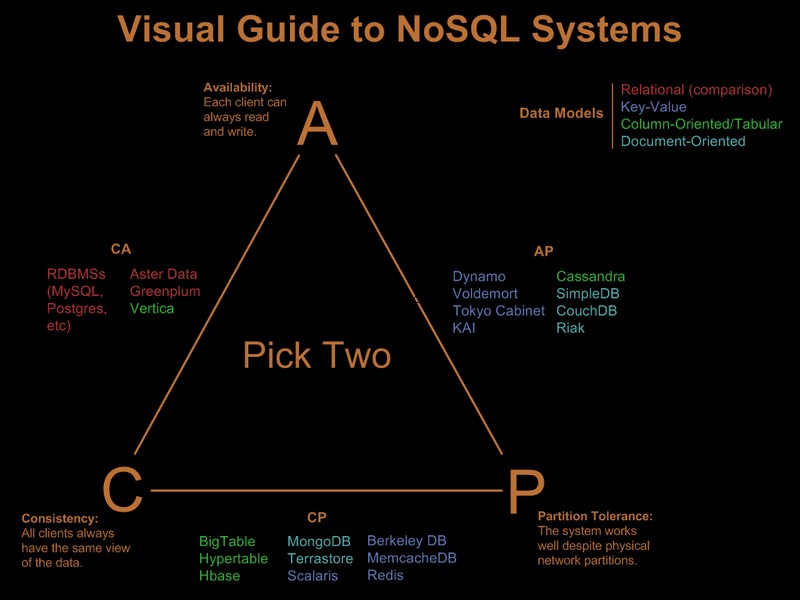
Entonces, obviamente, ya ha relajado algunos de estos requisitos. Hay una buena guía visual que compara las ofertas de nosql basadas en el paradigma 'elegir 2 de 3' en Visual Guide to NoSQL Systems:
Después de la actualización del comentario OP
Con SQL Server esto sería una implementación sencilla:
- una sola tabla agrupada (GUID, tiempo) clave. Sí, se va a fragmentar, pero la fragmentación afecta las lecturas anticipadas y las lecturas anticipadas son necesarias solo para escaneos de rango significativo. Dado que solo consulta un GUID específico y un rango de fechas, la fragmentación no importará mucho. Sí, es una clave ancha, por lo que las páginas sin hoja tendrán una densidad de clave baja. Sí, conducirá a un factor de relleno deficiente. Y sí, pueden ocurrir divisiones de página. A pesar de estos problemas, dados los requisitos, sigue siendo la mejor opción de clave agrupada.
- particione la tabla por tiempo para que pueda implementar la eliminación eficiente de los registros vencidos, a través de una ventana deslizante automática. Aumente esto con una reconstrucción de partición de índice en línea del último mes para eliminar el factor de relleno deficiente y la fragmentación introducida por el agrupamiento de GUID.
- habilitar la compresión de página. Dado que las claves agrupadas se agrupan primero por GUID, todos los registros de un GUID estarán uno al lado del otro, lo que brinda a la compresión de página una buena oportunidad para implementar la compresión de diccionario.
- necesitará una ruta de E/S rápida para el archivo de registro. Está interesado en un alto rendimiento, no en baja latencia para que un registro se mantenga al día con 1000 inserciones por segundo, por lo que la eliminación es imprescindible.
El particionamiento y la compresión de páginas requieren un servidor SQL Enterprise Edition, no funcionarán en Standard Edition y ambos son muy importantes para cumplir con los requisitos.
Como nota al margen, si los registros provienen de una granja de servidores web front-end, colocaría Express en cada servidor web y en lugar de INSERT en el back-end, SEND la información al back-end, usando una conexión/transacción local en el Express ubicado junto al servidor web. Esto proporciona una historia de disponibilidad mucho mejor para la solución.
Así es como lo haría en SQL Server. La buena noticia es que los problemas a los que se enfrentará se comprenden bien y se conocen las soluciones. eso no significa necesariamente que sea mejor que lo que podría lograr con Cassandra, BigTable o Dynamo. Dejaré que alguien más versado en cosas no-sql-ish argumente su caso.
Tenga en cuenta que nunca mencioné el modelo de programación, el soporte .Net y demás. Sinceramente, creo que son irrelevantes en grandes implementaciones. Hacen una gran diferencia en el proceso de desarrollo, pero una vez implementados, no importa qué tan rápido haya sido el desarrollo, si la sobrecarga de ORM mata el rendimiento :)