Encontrar "ToTime" por agregados en lugar de una unión
Me gustaría compartir una consulta realmente salvaje que solo requiere 1 escaneo de la tabla con 1 lectura lógica. En comparación, la mejor otra respuesta en la página, la consulta de Simon Kingston, requiere 2 escaneos.
En un conjunto de datos muy grande (17 408 filas de entrada, que producen 8193 filas de resultados) se necesita CPU 574 y tiempo 2645, mientras que la consulta de Simon Kingston requiere CPU 63 820 y tiempo 37 108.
Es posible que con los índices, las otras consultas en la página puedan funcionar muchas veces mejor, pero me parece interesante lograr una mejora de la CPU de 111x y una mejora de la velocidad de 14x simplemente reescribiendo la consulta.
(Tenga en cuenta:no pretendo faltarle el respeto a Simon Kingston ni a nadie más; simplemente estoy entusiasmado con mi idea de que esta consulta funcione tan bien. Su consulta es mejor que la mía, ya que su rendimiento es suficiente y en realidad es comprensible y mantenible , a diferencia de la mía.)
Aquí está la consulta imposible. Es difícil de entender. Fue difícil de escribir. Pero es impresionante. :)
WITH Ranks AS (
SELECT
T = Dense_Rank() OVER (ORDER BY Time, Num),
N = Dense_Rank() OVER (PARTITION BY Name ORDER BY Time, Num),
*
FROM
#Data D
CROSS JOIN (
VALUES (1), (2)
) X (Num)
), Items AS (
SELECT
FromTime = Min(Time),
ToTime = Max(Time),
Name = IsNull(Min(CASE WHEN Num = 2 THEN Name END), Min(Name)),
I = IsNull(Min(CASE WHEN Num = 2 THEN T - N END), Min(T - N)),
MinNum = Min(Num)
FROM
Ranks
GROUP BY
T / 2
)
SELECT
FromTime = Min(FromTime),
ToTime = CASE WHEN MinNum = 2 THEN NULL ELSE Max(ToTime) END,
Name
FROM Items
GROUP BY
I, Name, MinNum
ORDER BY
FromTime
Nota:Esto requiere SQL 2008 o superior. Para que funcione en SQL 2005, cambie la cláusula VALUES a SELECT 1 UNION ALL SELECT 2 .
Consulta actualizada
Después de pensar un poco en esto, me di cuenta de que estaba realizando dos tareas lógicas separadas al mismo tiempo, y esto hizo que la consulta se complicara innecesariamente:1) podar las filas intermedias que no tienen relación con la solución final (filas que no comienzan una nueva tarea) y 2) extraiga el valor "ToTime" de la siguiente fila. Realizando el #1 antes #2, ¡la consulta es más simple y funciona con aproximadamente la mitad de la CPU!
Así que aquí está la consulta simplificada que primero recorta las filas que no nos interesan, luego obtiene el valor ToTime usando agregados en lugar de JOIN. Sí, tiene 3 funciones de ventana en lugar de 2, pero en última instancia debido a la menor cantidad de filas (después de eliminar las que no nos interesan) tiene menos trabajo que hacer:
WITH Ranks AS (
SELECT
Grp =
Row_Number() OVER (ORDER BY Time)
- Row_Number() OVER (PARTITION BY Name ORDER BY Time),
[Time], Name
FROM #Data D
), Ranges AS (
SELECT
Result = Row_Number() OVER (ORDER BY Min(R.[Time]), X.Num) / 2,
[Time] = Min(R.[Time]),
R.Name, X.Num
FROM
Ranks R
CROSS JOIN (VALUES (1), (2)) X (Num)
GROUP BY
R.Name, R.Grp, X.Num
)
SELECT
FromTime = Min([Time]),
ToTime = CASE WHEN Count(*) = 1 THEN NULL ELSE Max([Time]) END,
Name = IsNull(Min(CASE WHEN Num = 2 THEN Name ELSE NULL END), Min(Name))
FROM Ranges R
WHERE Result > 0
GROUP BY Result
ORDER BY FromTime;
Esta consulta actualizada tiene los mismos problemas que presenté en mi explicación, sin embargo, son más fáciles de resolver porque no estoy tratando con las filas adicionales innecesarias. También veo que Row_Number() / 2 valor de 0 que tuve que excluir, y no estoy seguro de por qué no lo excluí de la consulta anterior, pero en cualquier caso, ¡funciona perfectamente y es increíblemente rápido!
Aplique exterior Ordena las cosas
Por último, aquí hay una versión básicamente idéntica a la consulta de Simon Kingston que creo que es una sintaxis más fácil de entender.
SELECT
FromTime = Min(D.Time),
X.ToTime,
D.Name
FROM
#Data D
OUTER APPLY (
SELECT TOP 1 ToTime = D2.[Time]
FROM #Data D2
WHERE
D.[Time] < D2.[Time]
AND D.[Name] <> D2.[Name]
ORDER BY D2.[Time]
) X
GROUP BY
X.ToTime,
D.Name
ORDER BY
FromTime;
Aquí está la secuencia de comandos de configuración si desea realizar una comparación de rendimiento en un conjunto de datos más grande:
CREATE TABLE #Data (
RecordId int,
[Time] int,
Name varchar(10)
);
INSERT #Data VALUES
(1, 10, 'Running'),
(2, 18, 'Running'),
(3, 21, 'Running'),
(4, 29, 'Walking'),
(5, 33, 'Walking'),
(6, 57, 'Running'),
(7, 66, 'Running'),
(8, 77, 'Running'),
(9, 81, 'Walking'),
(10, 89, 'Running'),
(11, 93, 'Walking'),
(12, 99, 'Running'),
(13, 107, 'Running'),
(14, 113, 'Walking'),
(15, 124, 'Walking'),
(16, 155, 'Walking'),
(17, 178, 'Running');
GO
insert #data select recordid + (select max(recordid) from #data), time + (select max(time) +25 from #data), name from #data
GO 10
Explicación
Esta es la idea básica detrás de mi consulta.
-
Los tiempos que representan un cambio deben aparecer en dos filas adyacentes, una para finalizar la actividad anterior y otra para comenzar la siguiente actividad. La solución natural a esto es una unión para que una fila de salida pueda extraerse de su propia fila (para la hora de inicio) y la siguiente modificada fila (para la hora de finalización).
-
Sin embargo, mi consulta cumple con la necesidad de hacer que las horas de finalización aparezcan en dos filas diferentes al repetir la fila dos veces, con
CROSS JOIN (VALUES (1), (2)). Ahora tenemos todas nuestras filas duplicadas. La idea es que, en lugar de usar JOIN para hacer cálculos entre columnas, usaremos alguna forma de agregación para colapsar cada par de filas deseadas en una sola. -
La siguiente tarea es hacer que cada fila duplicada se divida correctamente para que una instancia vaya con el par anterior y otra con el par siguiente. Esto se logra con la columna T, un
ROW_NUMBER()ordenado porTime, y luego dividido por 2 (aunque lo cambié para hacer DENSE_RANK() por simetría, ya que en este caso devuelve el mismo valor que ROW_NUMBER). Para mayor eficiencia, realicé la división en el siguiente paso para que el número de fila pudiera reutilizarse en otro cálculo (siga leyendo). Dado que el número de fila comienza en 1, y dividir por 2 implícitamente se convierte en int, esto tiene el efecto de producir la secuencia0 1 1 2 2 3 3 4 4 ...que tiene el resultado deseado:agrupando por este valor calculado, ya que también ordenamos porNumen el número de fila, ahora hemos logrado que todos los conjuntos después del primero estén compuestos por un Num =2 de la fila "anterior" y un Num =1 de la fila "siguiente". -
La siguiente tarea difícil es encontrar una manera de eliminar las filas que no nos interesan y de alguna manera colapsar la hora de inicio de un bloque en la misma fila que la hora de finalización de un bloque. Lo que queremos es una manera de conseguir que cada conjunto discreto de Correr o Caminar tenga su propio número para que podamos agruparlos por él.
DENSE_RANK()es una solución natural, pero un problema es que presta atención a cada valor en elORDER BYcláusula:no tenemos sintaxis para hacerDENSE_RANK() OVER (PREORDER BY Time ORDER BY Name)para que elTimeno causa elRANKcálculo a cambiar excepto en cada cambio enName. Después de pensarlo un poco, me di cuenta de que podía extraer un poco de la lógica detrás de la solución de islas agrupadas de Itzik Ben-Gan, y descubrí que el rango de las filas ordenadas porTime, restado del rango de las filas divididas porNamey ordenado porTime, produciría un valor que fuera el mismo para cada fila en el mismo grupo pero diferente de otros grupos. La técnica genérica de islas agrupadas consiste en crear dos valores calculados que ascienden al unísono con las filas, como4 5 6y1 2 3, que cuando se resta dará el mismo valor (en este caso de ejemplo3 3 3como resultado de4 - 1,5 - 2y6 - 3). Nota:inicialmente comencé conROW_NUMBER()para miNcálculo pero no estaba funcionando. La respuesta correcta fueDENSE_RANK()aunque lamento decir que no recuerdo por qué concluí esto en ese momento, y tendría que sumergirme nuevamente para resolverlo. Pero de todos modos, eso es lo queT-Ncalcula:un número que se puede agrupar para aislar cada "isla" de un estado (ya sea Corriendo o Caminando). -
Pero este no fue el final porque hay algunas arrugas. En primer lugar, la fila "siguiente" de cada grupo contiene los valores incorrectos para
Name,NyT. Solucionamos esto seleccionando, de cada grupo, el valor deNum = 2fila cuando existe (pero si no existe, entonces usamos el valor restante). Esto produce expresiones comoCASE WHEN NUM = 2 THEN x END:esto eliminará correctamente los valores incorrectos de la fila "siguiente". -
Después de experimentar un poco, me di cuenta de que no era suficiente agrupar por
T - Npor sí mismo, porque tanto los grupos Caminar como los grupos Correr pueden tener el mismo valor calculado (en el caso de mis datos de muestra proporcionados hasta 17, hay dosT - Nvalores de 6). Pero simplemente agrupando porNametambién resuelve este problema. Ningún grupo de "Correr" o "Caminar" tendrá el mismo número de valores intermedios del tipo opuesto. Es decir, dado que el primer grupo comienza con "Correr", y hay dos filas "Caminantes" antes del siguiente grupo "Correr", entonces el valor de N será 2 menos que el valor deTen ese próximo grupo de "Correr". Me acabo de dar cuenta de que una forma de pensar en esto es que elT - NEl cálculo cuenta el número de filas antes de la fila actual que NO pertenecen al mismo valor "Corriendo" o "Caminando". Un poco de pensamiento mostrará que esto es cierto:si pasamos al tercer grupo de "Correr", es solo el tercer grupo en virtud de tener un grupo de "Caminar" que los separa, por lo que tiene un número diferente de filas intermedias que entran antes, y debido a que comienza en una posición más alta, es lo suficientemente alto como para que los valores no se puedan duplicar. -
Finalmente, dado que nuestro grupo final consta de una sola fila (no hay hora de finalización y necesitamos mostrar un
NULLen cambio) Tuve que lanzar un cálculo que podría usarse para determinar si teníamos una hora de finalización o no. Esto se logra conMin(Num)expresión y finalmente detectando que cuando Min(Num) era 2 (lo que significa que no teníamos una fila "siguiente") luego muestra unNULLen lugar deMax(ToTime)valor.
Espero que esta explicación sea de alguna utilidad para la gente. No sé si mi técnica de "multiplicación de filas" será generalmente útil y aplicable a la mayoría de los escritores de consultas SQL en entornos de producción debido a la dificultad de entenderla y la dificultad de mantenimiento que seguramente presentará a la próxima persona que visite el código (la reacción probablemente sea "¿¡Qué diablos está haciendo!?!" seguido de un rápido "¡Hora de reescribir!").
Si has llegado hasta aquí, te agradezco tu tiempo y por complacerme en mi pequeña excursión a la increíblemente-divertida-tierra-de-rompecabezas-sql.
Véalo usted mismo
alias simulando un "RESERVA POR":
Una última nota. Para ver cómo T - N hace el trabajo, y teniendo en cuenta que el uso de esta parte de mi método puede no ser aplicable en general a la comunidad de SQL, ejecute la siguiente consulta en las primeras 17 filas de los datos de muestra:
WITH Ranks AS (
SELECT
T = Dense_Rank() OVER (ORDER BY Time),
N = Dense_Rank() OVER (PARTITION BY Name ORDER BY Time),
*
FROM
#Data D
)
SELECT
*,
T - N
FROM Ranks
ORDER BY
[Time];
Esto produce:
RecordId Time Name T N T - N
----------- ---- ---------- ---- ---- -----
1 10 Running 1 1 0
2 18 Running 2 2 0
3 21 Running 3 3 0
4 29 Walking 4 1 3
5 33 Walking 5 2 3
6 57 Running 6 4 2
7 66 Running 7 5 2
8 77 Running 8 6 2
9 81 Walking 9 3 6
10 89 Running 10 7 3
11 93 Walking 11 4 7
12 99 Running 12 8 4
13 107 Running 13 9 4
14 113 Walking 14 5 9
15 124 Walking 15 6 9
16 155 Walking 16 7 9
17 178 Running 17 10 7
La parte importante es que cada grupo de "Caminar" o "Correr" tiene el mismo valor para T - N que es distinto de cualquier otro grupo con el mismo nombre.
Rendimiento
No quiero insistir en el punto de que mi consulta es más rápida que la de otras personas. Sin embargo, dado lo llamativa que es la diferencia (cuando no hay índices) quería mostrar los números en formato de tabla. Esta es una buena técnica cuando se necesita un alto rendimiento de este tipo de correlación de fila a fila.
Antes de ejecutar cada consulta, usé DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; . Establecí MAXDOP en 1 para cada consulta para eliminar los efectos del paralelismo que colapsan el tiempo. Seleccioné cada conjunto de resultados en variables en lugar de devolverlos al cliente para medir solo el rendimiento y no la transmisión de datos del cliente. Todas las consultas recibieron las mismas cláusulas ORDER BY. Todas las pruebas utilizaron 17 408 filas de entrada que arrojaron 8193 filas de resultados.
No se muestran resultados por las siguientes personas/razones:
RichardTheKiwi *Could not test--query needs updating*
ypercube *No SQL 2012 environment yet :)*
Tim S *Did not complete tests within 5 minutes*
Sin índice:
CPU Duration Reads Writes
----------- ----------- ----------- -----------
ErikE 344 344 99 0
Simon Kingston 68672 69582 549203 49
Con índice CREATE UNIQUE CLUSTERED INDEX CI_#Data ON #Data (Time); :
CPU Duration Reads Writes
----------- ----------- ----------- -----------
ErikE 328 336 99 0
Simon Kingston 70391 71291 549203 49 * basically not worse
Con índice CREATE UNIQUE CLUSTERED INDEX CI_#Data ON #Data (Time, Name); :
CPU Duration Reads Writes
----------- ----------- ----------- -----------
ErikE 375 414 359 0 * IO WINNER
Simon Kingston 172 189 38273 0 * CPU WINNER
Así que la moraleja de la historia es:
Los índices apropiados son más importantes que la consulta mágica
Con el índice apropiado, la versión de Simon Kingston gana en general, especialmente cuando incluye la complejidad/mantenibilidad de la consulta.
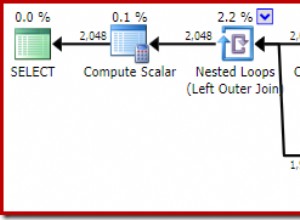
¡Presta atención a esta lección! 38.000 lecturas no son realmente tantas, y la versión de Simon Kingston se ejecutó en la mitad del tiempo que la mía. El aumento de velocidad de mi consulta se debió completamente a que no había un índice en la tabla, y el costo catastrófico concomitante que esto le otorgó a cualquier consulta que necesitara una combinación (que la mía no necesitaba):un Hash Match de escaneo completo de la tabla matando su rendimiento. Con un índice, su consulta pudo hacer un bucle anidado con una búsqueda de índice agrupado (también conocida como búsqueda de marcador) que hizo que las cosas realmente rápido.
Es interesante que un índice agrupado en el tiempo por sí solo no fue suficiente. Aunque las Horas eran únicas, lo que significa que solo ocurría un Nombre por vez, aún necesitaba que el Nombre fuera parte del índice para poder utilizarlo correctamente.
¡Agregar el índice agrupado a la tabla cuando estaba lleno de datos tomó menos de 1 segundo! No descuides tus índices.