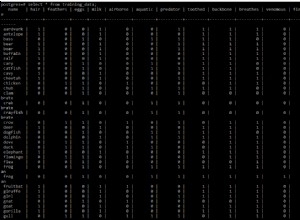
Puede resolver el problema obligando a que la intercalación utilizada en una consulta sea una intercalación particular, p. SQL_Latin1_General_CP1_CI_AS o DATABASE_DEFAULT . Por ejemplo:
SELECT MyColumn
FROM FirstTable a
INNER JOIN SecondTable b
ON a.MyID COLLATE SQL_Latin1_General_CP1_CI_AS =
b.YourID COLLATE SQL_Latin1_General_CP1_CI_AS
En la consulta anterior, a.MyID y b.YourID serían columnas con un tipo de datos basado en texto. Usando COLLATE obligará a la consulta a ignorar la intercalación predeterminada en la base de datos y, en su lugar, usar la intercalación proporcionada, en este caso SQL_Latin1_General_CP1_CI_AS .
Básicamente, lo que sucede aquí es que cada base de datos tiene su propia intercalación que "proporciona reglas de clasificación, mayúsculas y minúsculas y propiedades de sensibilidad de acento para sus datos" (de https://technet.microsoft.com/en-us/library/ms143726.aspx ) y se aplica a columnas con tipos de datos textuales , p.ej. VARCHAR , CHAR , NVARCHAR , etc. Cuando dos bases de datos tienen intercalaciones diferentes, no puede comparar columnas de texto con un operador como igual (=) sin abordar el conflicto entre las dos intercalaciones dispares.