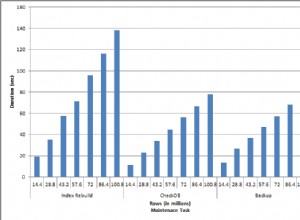
Si usa consultas exactas de la pregunta, entonces la primera variante, por supuesto, es más lenta porque debe contar todos los registros en la tabla que satisface los criterios.
Debe escribirse como
SELECT COUNT(*) INTO row_count FROM foo WHERE bar = 123 and rownum = 1;
o
select 1 into row_count from dual where exists (select 1 from foo where bar = 123);
porque verificar la existencia de registros es suficiente para su propósito.
Por supuesto, ambas variantes no garantizan que otra persona no cambie algo en foo entre dos declaraciones, pero no es un problema si esta verificación es parte de un escenario más complejo. Solo piense en la situación en la que alguien cambió el valor de foo.a después de seleccionar su valor en var mientras realiza algunas acciones que se refieren a var seleccionado valor. Por lo tanto, en escenarios complejos, es mejor manejar tales problemas de concurrencia en el nivel de lógica de la aplicación.
Para realizar operaciones atómicas, es mejor usar una declaración SQL única.
Cualquiera de las variantes anteriores requiere 2 cambios de contexto entre SQL y PL/SQL y 2 consultas, por lo que funciona más lento que cualquier variante descrita a continuación en los casos en que se encuentra una fila en una tabla.
Hay otras variantes para verificar la existencia de una fila sin excepción:
select max(a), count(1) into var, row_count
from foo
where bar = 123 and rownum < 3;
Si row_count =1, solo una fila cumple los criterios.
En algún momento, es suficiente verificar solo la existencia debido a la restricción única en el foo lo que garantiza que no hay bar duplicadas valores en foo . P.ej. bar es la clave principal.
En tales casos, es posible simplificar la consulta:
select max(a) into var from foo where bar = 123;
if(var is not null) then
...
end if;
o use el cursor para procesar valores:
for cValueA in (
select a from foo where bar = 123
) loop
...
end loop;
La siguiente variante es de enlace , proporcionado por @user272735 en su respuesta:
select
(select a from foo where bar = 123)
into var
from dual;
Según mi experiencia, cualquier variante sin bloques de excepción en la mayoría de los casos es más rápida que una variante con excepciones, pero si el número de ejecuciones de dicho bloque es bajo, entonces es mejor usar el bloque de excepción con manejo de no_data_found y too_many_rows excepciones para mejorar la legibilidad del código.
El punto correcto para elegir usar una excepción o no usarla es hacer una pregunta "¿Esta situación es normal para la aplicación?". Si no se encuentra la fila y es una situación esperada que se puede manejar (por ejemplo, agregar una nueva fila o tomar datos de otro lugar, etc.), es mejor evitar la excepción. Si es inesperado y no hay forma de solucionar una situación, entonces detecte la excepción para personalizar el mensaje de error, escríbalo en el registro de eventos y vuelva a generarlo, o simplemente no lo detecte en absoluto.
Para comparar el rendimiento, simplemente haga un caso de prueba simple en su sistema con ambas variantes llamadas muchas veces y compare. Cuestiones que deben tenerse en cuenta en primer lugar.
Actualizar
Reproduje un ejemplo de esta página
en el sitio de SQLFiddle con algunas correcciones (enlace
).
Los resultados prueban esa variante con la selección de dual funciona mejor:un poco de sobrecarga cuando la mayoría de las consultas tienen éxito y la menor degradación del rendimiento cuando aumenta el número de filas faltantes.
Sorprendentemente, la variante con count() y dos consultas mostraron el mejor resultado en caso de que todas las consultas fallaran.
| FNAME | LOOP_COUNT | ALL_FAILED | ALL_SUCCEED | variant name |
----------------------------------------------------------------
| f1 | 2000 | 2.09 | 0.28 | exception |
| f2 | 2000 | 0.31 | 0.38 | cursor |
| f3 | 2000 | 0.26 | 0.27 | max() |
| f4 | 2000 | 0.23 | 0.28 | dual |
| f5 | 2000 | 0.22 | 0.58 | count() |
-- FNAME - tested function name
-- LOOP_COUNT - number of loops in one test run
-- ALL_FAILED - time in seconds if all tested rows missed from table
-- ALL_SUCCEED - time in seconds if all tested rows found in table
-- variant name - short name of tested variant
A continuación se muestra un código de configuración para el entorno de prueba y el script de prueba.
create table t_test(a, b)
as
select level,level from dual connect by level<=1e5
/
insert into t_test(a, b) select null, level from dual connect by level < 100
/
create unique index x_text on t_test(a)
/
create table timings(
fname varchar2(10),
loop_count number,
exec_time number
)
/
create table params(pstart number, pend number)
/
-- loop bounds
insert into params(pstart, pend) values(1, 2000)
/
--
create or replace function f1(p in number) return number
as
res number;
begin
select b into res
from t_test t
where t.a=p and rownum = 1;
return res;
exception when no_data_found then
return null;
end;
/
--
create or replace function f2(p in number) return number
as
res number;
begin
for rec in (select b from t_test t where t.a=p and rownum = 1) loop
res:=rec.b;
end loop;
return res;
end;
/
--
create or replace function f3(p in number) return number
as
res number;
begin
select max(b) into res
from t_test t
where t.a=p and rownum = 1;
return res;
end;
/
--
create or replace function f4(p in number) return number
as
res number;
begin
select
(select b from t_test t where t.a=p and rownum = 1)
into res
from dual;
return res;
end;
/
--
create or replace function f5(p in number) return number
as
res number;
cnt number;
begin
select count(*) into cnt
from t_test t where t.a=p and rownum = 1;
if(cnt = 1) then
select b into res from t_test t where t.a=p;
end if;
return res;
end;
/
Guión de prueba:
declare
v integer;
v_start integer;
v_end integer;
vStartTime number;
begin
select pstart, pend into v_start, v_end from params;
vStartTime := dbms_utility.get_cpu_time;
for i in v_start .. v_end loop
v:=f1(i);
end loop;
insert into timings(fname, loop_count, exec_time)
values ('f1', v_end-v_start+1, (dbms_utility.get_cpu_time - vStartTime)/100) ;
end;
/
declare
v integer;
v_start integer;
v_end integer;
vStartTime number;
begin
select pstart, pend into v_start, v_end from params;
vStartTime := dbms_utility.get_cpu_time;
for i in v_start .. v_end loop
v:=f2(i);
end loop;
insert into timings(fname, loop_count, exec_time)
values ('f2', v_end-v_start+1, (dbms_utility.get_cpu_time - vStartTime)/100) ;
end;
/
declare
v integer;
v_start integer;
v_end integer;
vStartTime number;
begin
select pstart, pend into v_start, v_end from params;
vStartTime := dbms_utility.get_cpu_time;
for i in v_start .. v_end loop
v:=f3(i);
end loop;
insert into timings(fname, loop_count, exec_time)
values ('f3', v_end-v_start+1, (dbms_utility.get_cpu_time - vStartTime)/100) ;
end;
/
declare
v integer;
v_start integer;
v_end integer;
vStartTime number;
begin
select pstart, pend into v_start, v_end from params;
vStartTime := dbms_utility.get_cpu_time;
for i in v_start .. v_end loop
v:=f4(i);
end loop;
insert into timings(fname, loop_count, exec_time)
values ('f4', v_end-v_start+1, (dbms_utility.get_cpu_time - vStartTime)/100) ;
end;
/
declare
v integer;
v_start integer;
v_end integer;
vStartTime number;
begin
select pstart, pend into v_start, v_end from params;
--v_end := v_start + trunc((v_end-v_start)*2/3);
vStartTime := dbms_utility.get_cpu_time;
for i in v_start .. v_end loop
v:=f5(i);
end loop;
insert into timings(fname, loop_count, exec_time)
values ('f5', v_end-v_start+1, (dbms_utility.get_cpu_time - vStartTime)/100) ;
end;
/
select * from timings order by fname
/