Actualmente, las bases de datos que abarcan múltiples nubes son bastante comunes. Prometen alta disponibilidad y posibilidad de implementar fácilmente procedimientos de recuperación ante desastres. También son un método para evitar el bloqueo del proveedor:si diseña su entorno de base de datos para que pueda operar en múltiples proveedores de nube, lo más probable es que no esté atado a las funciones e implementaciones específicas de un proveedor en particular. Esto le facilita agregar otro proveedor de infraestructura a su entorno, ya sea otra nube o una configuración local. Esta flexibilidad es muy importante dado que existe una competencia feroz entre los proveedores de la nube y la migración de uno a otro podría ser bastante factible si estuviera respaldada por la reducción de gastos.
Ampliar su infraestructura en múltiples centros de datos (del mismo proveedor o no, en realidad no importa) trae serios problemas que resolver. ¿Cómo se puede diseñar toda la infraestructura de manera que los datos estén seguros? ¿Cómo lidiar con los desafíos que debe enfrentar mientras trabaja en un entorno de múltiples nubes? En este blog echaremos un vistazo a uno, pero posiblemente el más serio:el potencial de un cerebro dividido. ¿Qué significa? Profundicemos un poco en lo que es el cerebro dividido.
¿Qué es el “cerebro dividido”?
Split-brain es una condición en la que un entorno que consta de varios nodos sufre la partición de la red y se ha dividido en varios segmentos que no tienen contacto entre sí. El caso más simple se verá así:
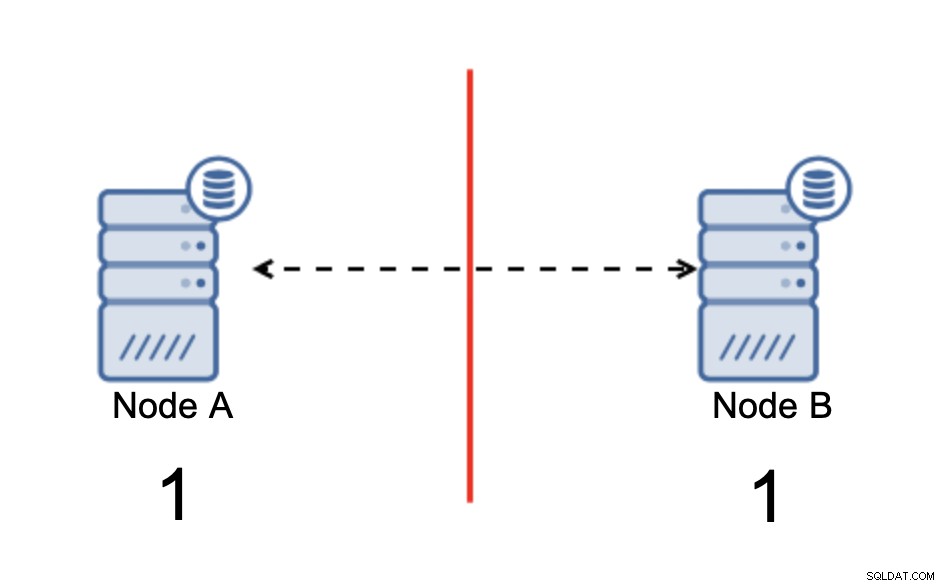
Tenemos dos nodos, A y B, conectados a través de una red mediante bi -Replicación asíncrona direccional. Luego, la conexión de red se corta entre esos nodos. Como resultado, ambos nodos no pueden conectarse entre sí y cualquier cambio ejecutado en el nodo A no puede transmitirse al nodo B y viceversa. Ambos nodos, A y B, están activos y aceptan conexiones, simplemente no pueden intercambiar datos. Esto puede generar problemas graves, ya que la aplicación puede realizar cambios en ambos nodos esperando ver el estado completo de la base de datos cuando, de hecho, opera solo en un estado de datos parcialmente conocido. Como resultado, la aplicación puede tomar acciones incorrectas, se pueden presentar resultados incorrectos al usuario, etc. Creemos que está claro que el cerebro dividido es una condición potencialmente muy peligrosa y una de las prioridades sería tratarla hasta cierto punto. ¿Qué se puede hacer al respecto?
Cómo evitar el cerebro dividido
En resumen, depende. El problema principal a tratar es el hecho de que los nodos están en funcionamiento pero no tienen conectividad entre ellos, por lo que desconocen el estado del otro nodo. En general, la replicación asíncrona de MySQL no tiene ningún tipo de mecanismo que resuelva internamente el problema del cerebro dividido. Puede intentar implementar algunas soluciones que lo ayuden a evitar el cerebro dividido, pero tienen limitaciones o aún no resuelven el problema por completo.
Cuando nos alejamos de la replicación asincrónica, las cosas se ven de manera diferente. MySQL Group Replication y MySQL Galera Cluster son tecnologías que se benefician del conocimiento del clúster Build-it. Ambas soluciones mantienen la comunicación entre los nodos y aseguran que el clúster esté al tanto del estado de los nodos. Implementan un mecanismo de quórum que determina si los clústeres pueden estar operativos o no.
Hablemos de esas dos soluciones (replicación asíncrona y clústeres basados en quórum) con más detalle.
Clustering basado en quórum
No vamos a discutir las diferencias de implementación entre MySQL Galera Cluster y MySQL Group Replication, nos centraremos en la idea básica detrás del enfoque basado en quórum y cómo está diseñado para resolver el problema de la cerebro dividido en su grupo.
La conclusión es que:el clúster, para operar, requiere que la mayoría de sus nodos estén disponibles. Con este requisito podemos estar seguros de que la minoría nunca podrá afectar realmente al resto del clúster porque la minoría no debería poder realizar ninguna acción. Esto también significa que, para poder manejar una falla de un nodo, un clúster debe tener al menos tres nodos. Si solo tiene dos nodos:
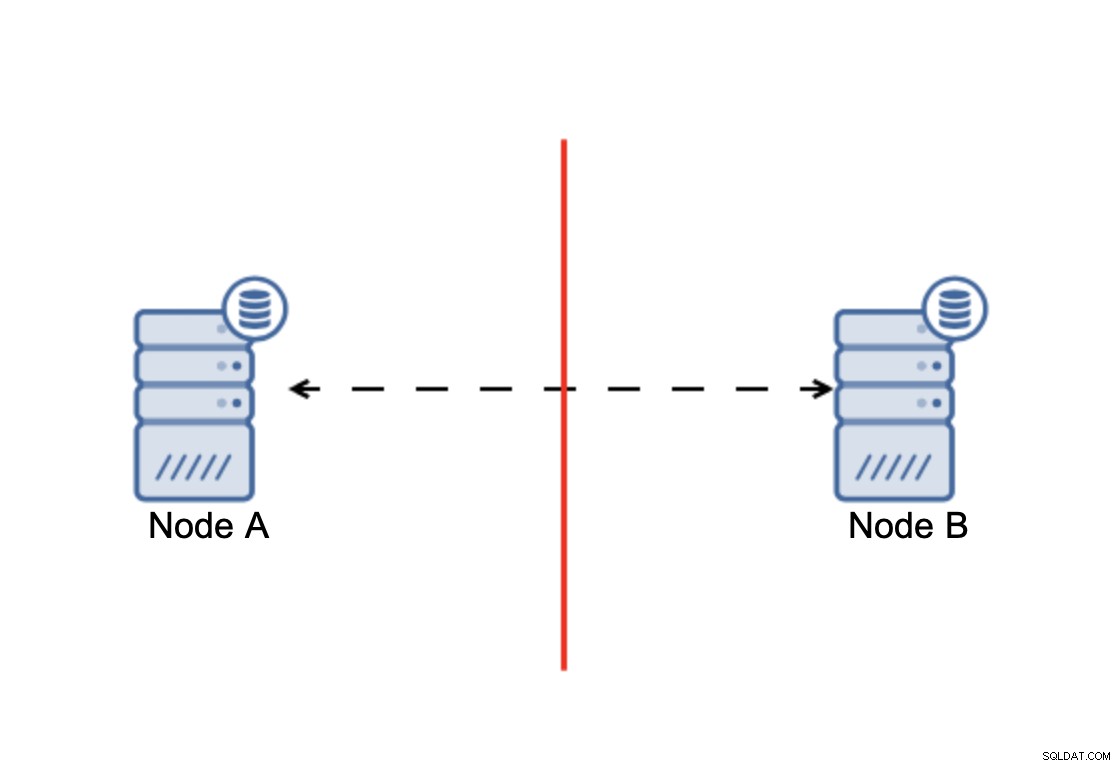
Cuando hay una división de red, termina con dos partes de la clúster, cada uno compuesto por exactamente el 50 % del total de nodos del clúster. Ninguna de estas partes tiene mayoría. Sin embargo, si tiene tres nodos, las cosas son diferentes:
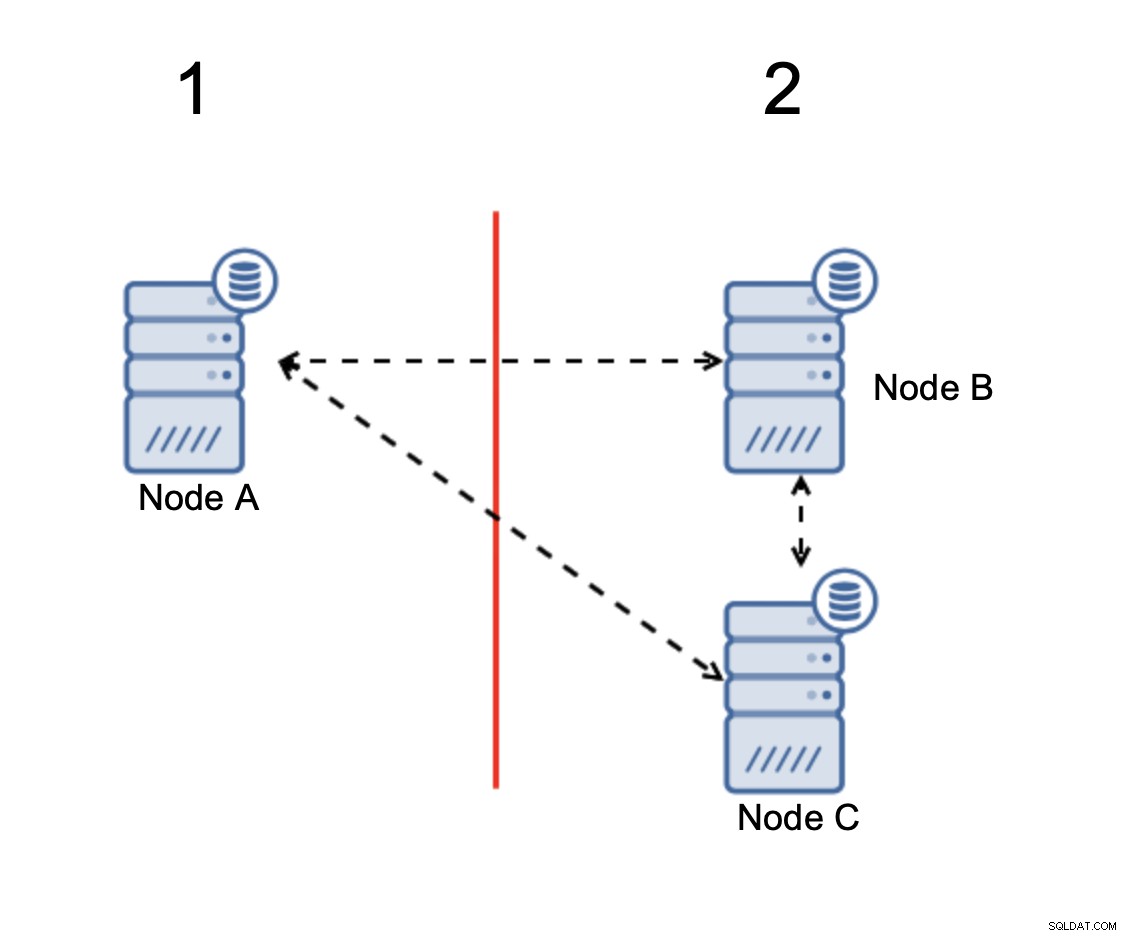
Los nodos B y C tienen la mayoría:esa parte consta de dos nodos fuera de tres para que pueda seguir funcionando. Por otro lado, el nodo A representa solo el 33% de los nodos en el clúster, por lo que no tiene una mayoría y dejará de manejar el tráfico para evitar el cerebro dividido.
Con tal implementación, es muy poco probable que suceda el cerebro dividido (tendría que introducirse a través de algunos estados de red extraños e inesperados, condiciones de carrera o simplemente errores en el código de agrupación. Si bien no es imposible encontrar En tales condiciones, usar una de las soluciones basadas en quórum es la mejor opción para evitar el cerebro dividido que existe en este momento.
Replicación asíncrona
Si bien no es la opción ideal cuando se trata de un cerebro dividido, la replicación asincrónica sigue siendo una opción viable. Hay varias cosas que debe considerar antes de implementar una base de datos de múltiples nubes con replicación asíncrona.
Primero, conmutación por error. La replicación asincrónica viene con un escritor:solo el maestro debe poder escribirse y otros nodos solo deben servir tráfico de solo lectura. El desafío es cómo lidiar con la falla del maestro.
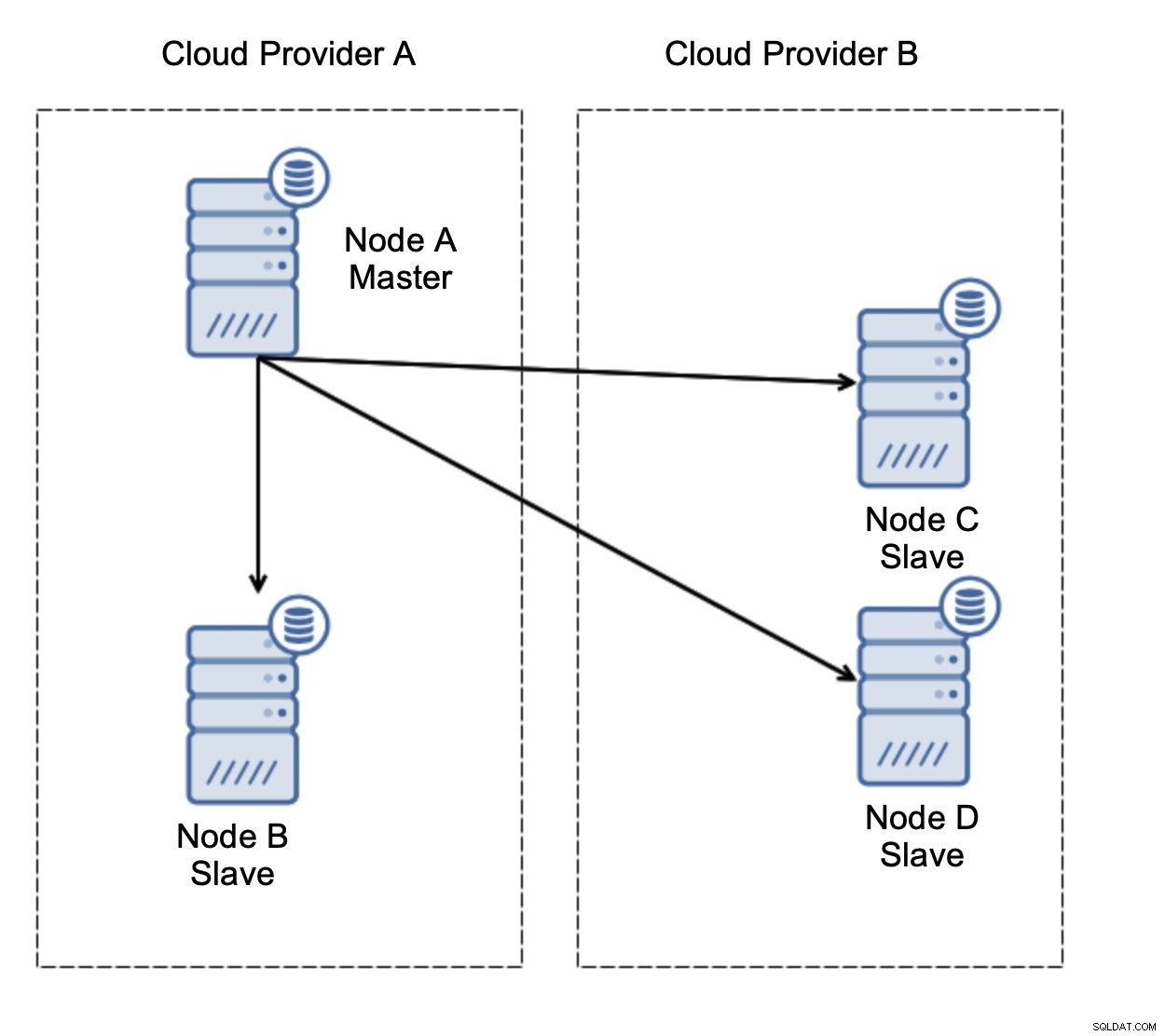
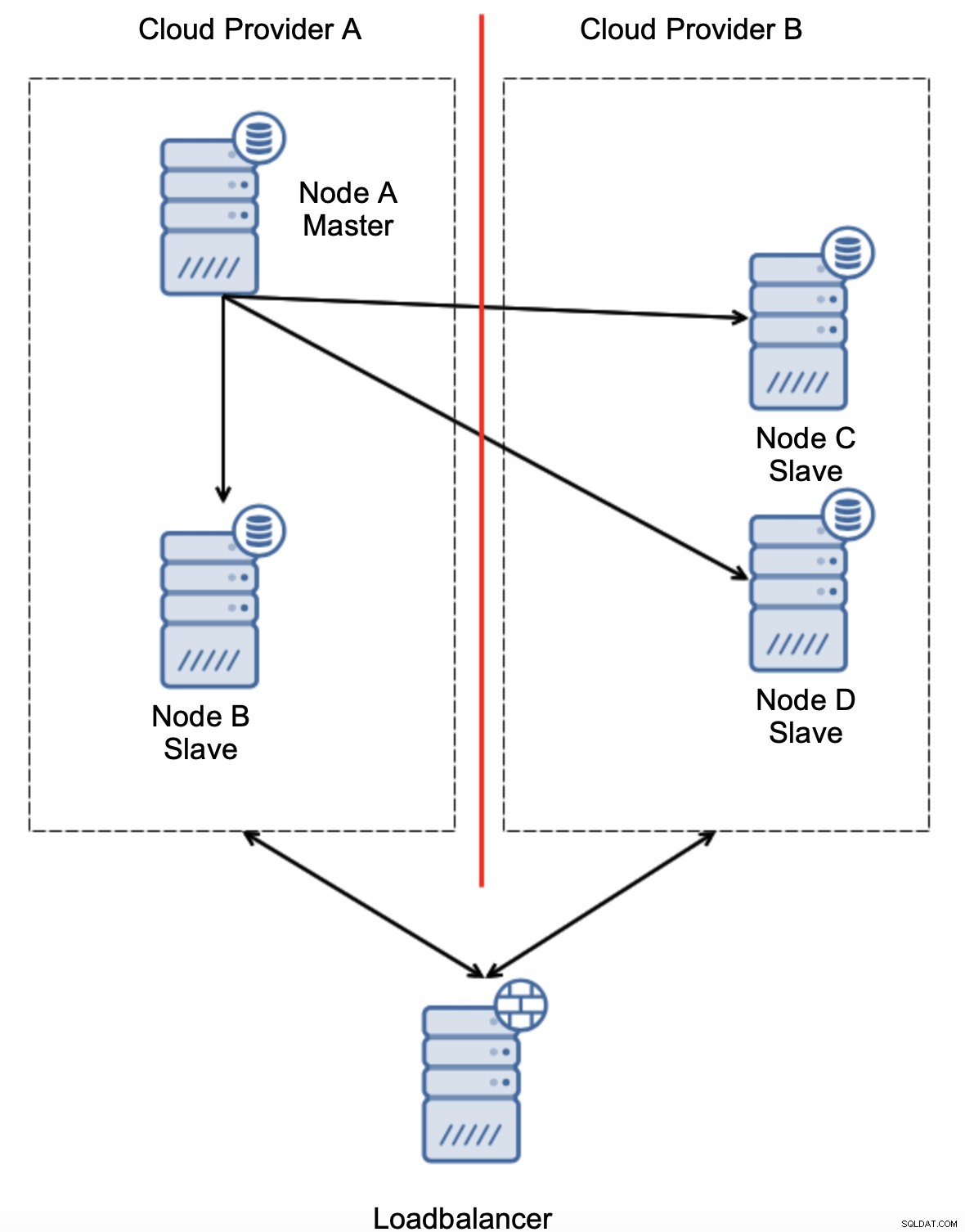
Consideremos la configuración como en el diagrama anterior. Tenemos dos proveedores de nube, dos nodos en cada uno. El proveedor A aloja también al maestro. ¿Qué debería pasar si el maestro falla? Se debe promover uno de los esclavos para garantizar que la base de datos continúe operativa. Idealmente, debería ser un proceso automatizado para reducir el tiempo necesario para llevar la base de datos al estado operativo. Sin embargo, ¿qué pasaría si hubiera una partición de la red? ¿Cómo se espera que verifiquemos el estado del clúster?
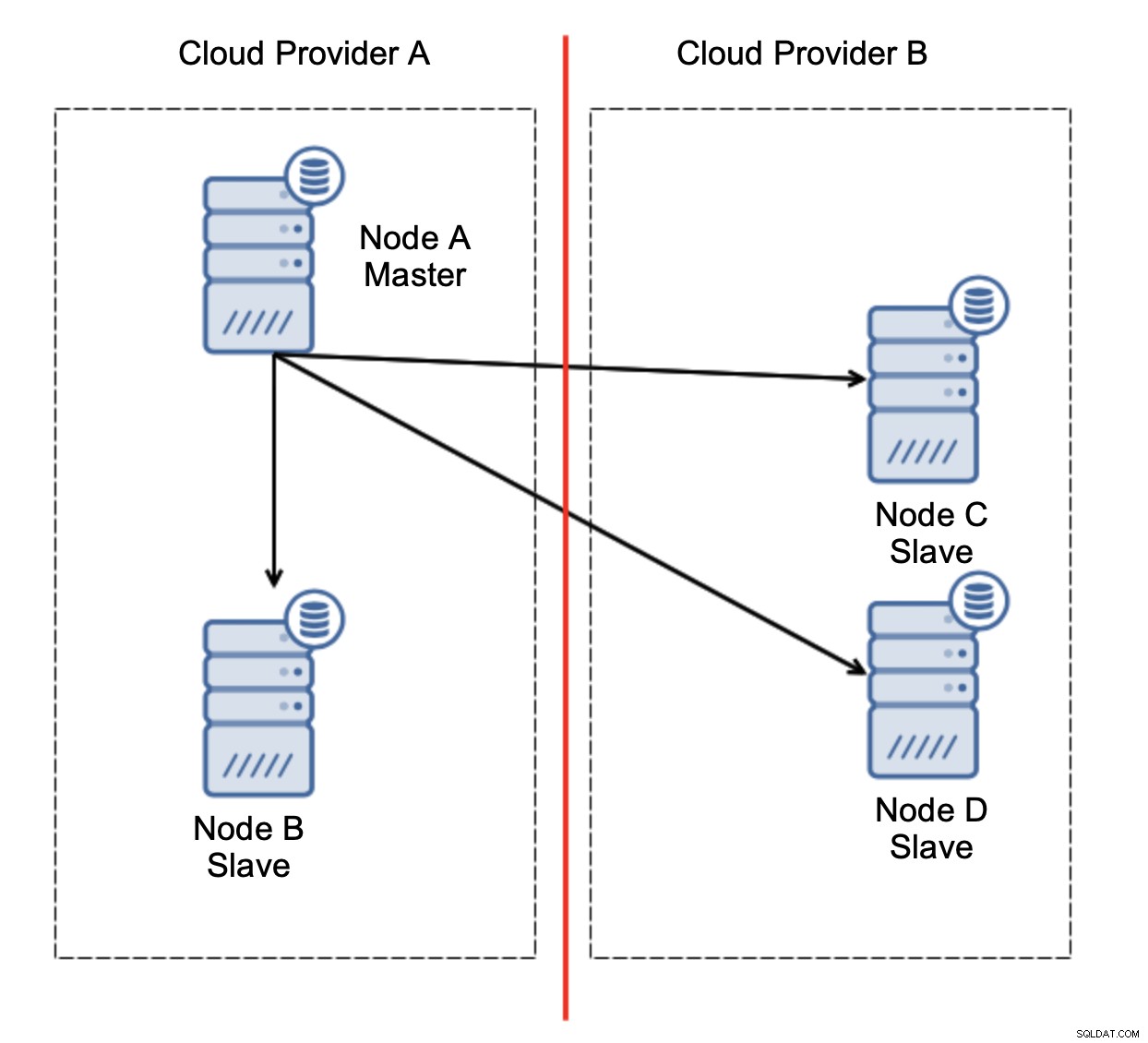
Este es el desafío. Se pierde la conectividad de red entre dos proveedores de nube. Desde el punto de vista de los nodos C y D, tanto el nodo B como el maestro, el nodo A están fuera de línea. ¿Debería promoverse el nodo C o D para convertirse en maestro? Pero el antiguo maestro todavía está activo:no se bloqueó, simplemente no se puede acceder a él a través de la red. Si promocionamos uno de los nodos ubicados en el proveedor B, terminaremos con dos maestros escribibles, dos conjuntos de datos y cerebro dividido:
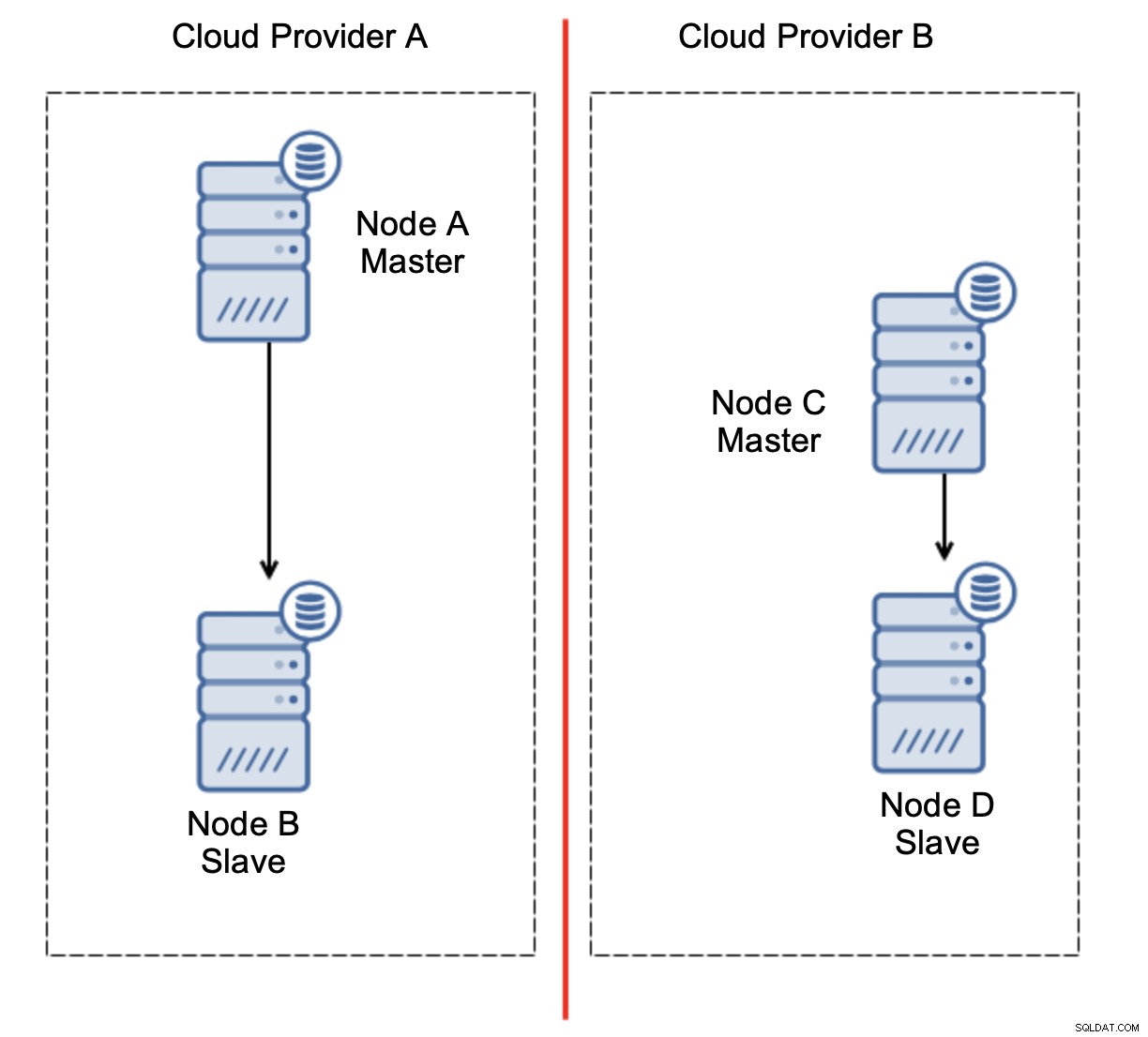
Esto definitivamente no es algo que queremos. Hay un par de opciones aquí. Primero, podemos definir reglas de conmutación por error de manera que la conmutación por error pueda ocurrir solo en uno de los segmentos de la red, donde se encuentra el maestro. En nuestro caso, significaría que solo el nodo B podría promoverse automáticamente para convertirse en maestro. De esa manera, podemos asegurarnos de que la conmutación por error automatizada ocurrirá si el nodo A está inactivo, pero no se tomará ninguna acción si hay una partición de la red. Algunas de las herramientas que pueden ayudarlo a manejar las conmutaciones por error automatizadas (como ClusterControl) admiten listas blancas y negras, lo que permite a los usuarios definir qué nodos pueden considerarse candidatos para la conmutación por error y cuáles nunca deben usarse como maestros.
Otra opción sería implementar algún tipo de solución de "conciencia de topología". Por ejemplo, se podría intentar verificar el estado del maestro usando servicios externos como balanceadores de carga.
Si la automatización de conmutación por error pudiera verificar el estado de la topología tal como lo ve el balanceador de carga, podría ser que el balanceador de carga, ubicado en una tercera ubicación, pueda llegar a ambos centros de datos y dejar en claro que los nodos en el proveedor de la nube A no están inactivos, simplemente no se puede acceder a ellos desde el proveedor de la nube B. Tal se implementa una capa adicional de comprobaciones en ClusterControl.
Finalmente, sea cual sea la herramienta que utilice para implementar la conmutación por error automatizada, también puede diseñarse para que tenga en cuenta el quórum. Luego, con tres nodos en tres ubicaciones, puede saber fácilmente qué parte de la infraestructura debe mantenerse activa y cuál no.
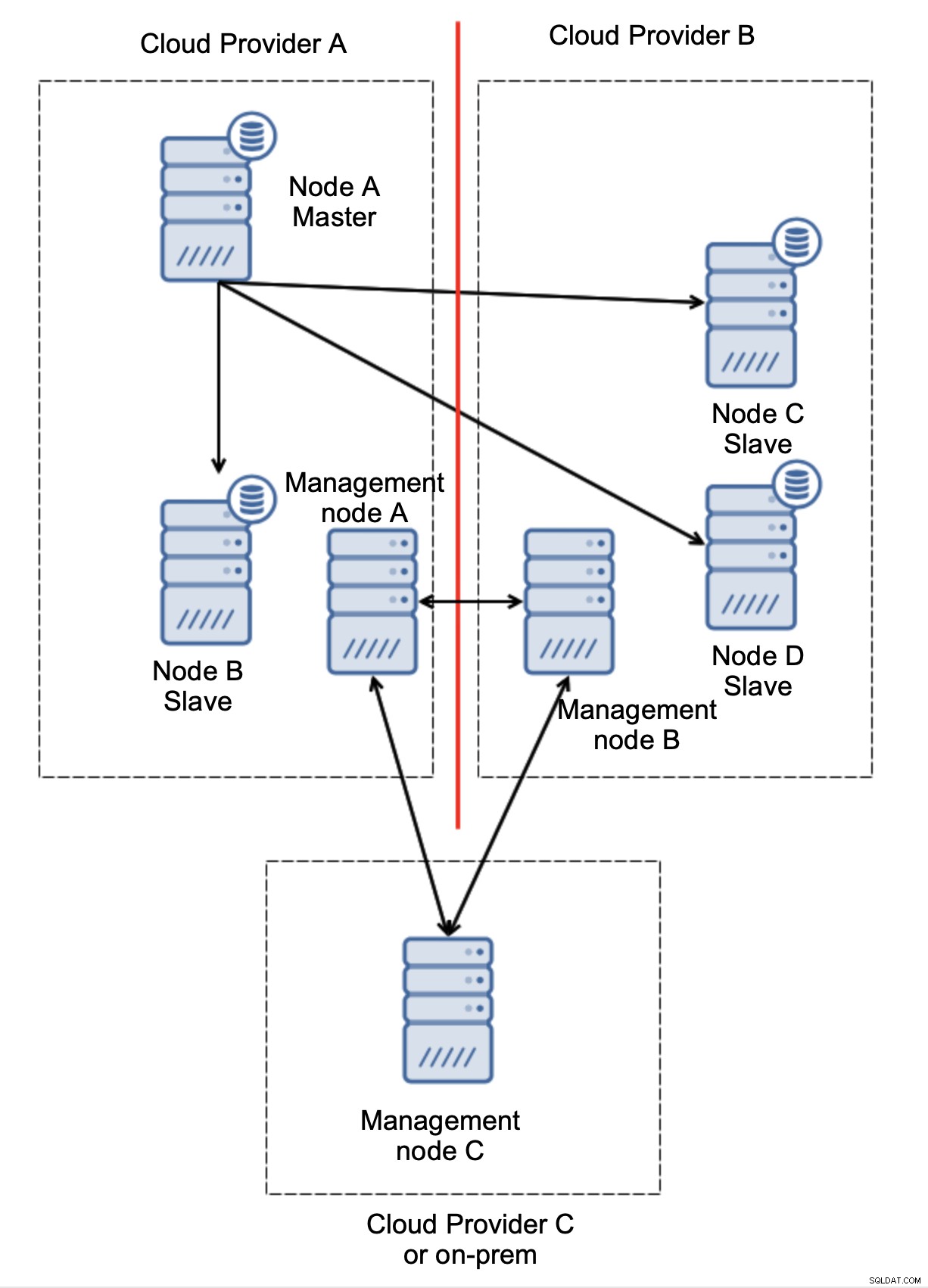
Aquí, podemos ver claramente que el problema está relacionado solo con la conectividad entre los proveedores A y B. El nodo de administración C actuará como retransmisión y, como resultado, no se debe iniciar una conmutación por error. Por otro lado, si un centro de datos está completamente cortado:

También está bastante claro lo que sucedió. El nodo de gestión A informará que no puede llegar a la mayoría del clúster, mientras que los nodos de gestión B y C formarán la mayoría. Es posible aprovechar esto y, por ejemplo, escribir secuencias de comandos que gestionarán la topología según el estado del nodo de gestión. Eso podría significar que los scripts ejecutados en el proveedor de la nube A detectarían que el nodo de administración A no forma la mayoría y detendrían todos los nodos de la base de datos para garantizar que no se produzcan escrituras en el proveedor de la nube particionada.
ClusterControl, cuando se implementa en modo de alta disponibilidad, se puede tratar como los nodos de administración que usamos en nuestros ejemplos. Tres nodos de ClusterControl, además del protocolo RAFT, pueden ayudarlo a determinar si un segmento de red determinado está particionado o no.
Conclusión
Esperamos que esta publicación de blog le brinde una idea sobre los escenarios de cerebro dividido que pueden ocurrir para las implementaciones de MySQL que se extienden a través de múltiples plataformas en la nube.