En los últimos años, el uso de la infraestructura de la plataforma ha pasado de la computación en las instalaciones a la computación en la nube. Esto se basa en la ausencia de costos de capital de costo en los que debe incurrir la empresa si se utiliza al implementar la infraestructura de TI. La computación en la nube proporciona flexibilidad en cada línea de recursos, es decir. en recursos humanos, energía, ahorro de tiempo.
La computación en la nube facilita a las organizaciones la planificación, ejecución y mantenimiento de plataformas de TI para respaldar los intereses comerciales.
Pero ambos tienen similitudes, teníamos que pensar en BCP (Business Continuity Plan) y Disaster Recovery Plan (DRP) al usar la nube. El almacenamiento de datos se vuelve crítico cuando hablamos de DRP, qué tan rápido hacemos la recuperación (objetivo de punto de recuperación) cuando ocurre un desastre. La arquitectura multinube juega un papel importante cuando queremos diseñar e implementar infraestructura en el entorno de la nube. En este blog, revisamos la implementación de múltiples nubes relacionada para almacenar datos en MySQL.
Configuración del entorno en la nube
Esta vez usamos Amazon Web Service (AWS), que es ampliamente utilizado por las empresas, y Google Cloud Platform (GCP) como el segundo proveedor de nube en una configuración de base de datos de varias nubes. Crear instancias (el término utilizado en la computación en la nube para las nuevas máquinas virtuales) en AWS es muy sencillo.
AWS utiliza el término Amazon EC2 (Elastic Compute Cloud) para su servicio de instancias informáticas. Puede iniciar sesión en AWS y luego seleccionar el servicio EC2.
Esta es la visualización de una instancia que se ha aprovisionado con EC2.
Por razones de seguridad, que es la mayor preocupación de los servicios en la nube, asegúrese de que solo habilitemos los puertos que se necesitan al implementar ClusterControl, como el puerto SSH (22), xtrabackup (9999) y la base de datos ( 3306) están protegidos pero son accesibles a través de los proveedores de la nube. Una forma de implementar dicha conectividad sería crear una VPN que conectaría instancias en AWS con instancias en GCP. Gracias a este diseño, podemos tratar todas las instancias como locales, aunque estén ubicadas en diferentes proveedores de nube. No describiremos exactamente el proceso de configuración de VPN, por lo tanto, tenga en cuenta que la implementación que presentamos no es adecuada para la producción en el mundo real. Es solo para ilustrar las posibilidades que vienen con ClusterControl y las configuraciones de múltiples nubes.

Después de completar la configuración de AWS EC2, continúe con la configuración de la instancia informática en GCP, en GCP, el servicio de cómputo se llama Compute Engine.
En este ejemplo, crearemos 1 instancia en la nube de GCP que ser utilizado como uno de los esclavos.
Cuando se complete, se mostrará en la consola de administración de la siguiente manera:
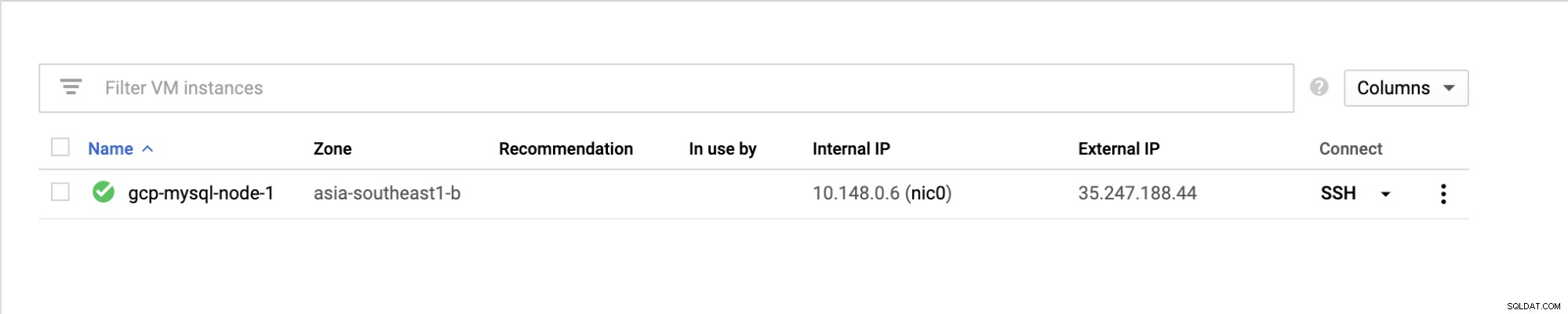
Asegúrese de asegurar y habilitar el puerto SSH (22), xtrabackup ( 9999) y base de datos (3306).
Después de implementar instancias tanto en AWS como en GCP, debemos continuar con la instalación de ClusterControl en una de las instancias en el proveedor de la nube, donde se ubicará el maestro. En esta configuración de ejemplo, utilizaremos una de las instancias de AWS como maestra.
Implementación de la replicación de MySQL en Amazon Web Service
Para instalar ClusterControl debe seguir las sencillas instrucciones que puede encontrar en el sitio web de Variousnines. Una vez que ClusterControl esté funcionando en el proveedor de la nube donde se ubicará nuestro maestro (en este ejemplo usaremos AWS para nuestro nodo maestro) podemos comenzar la implementación de MySQL Replication usando ClusterControl. Hay los siguientes pasos que debe seguir para instalar el clúster de replicación de MySQL:
Abra ClusterControl y luego seleccione MySQL Replication, verá que se deben completar tres formularios para el propósito de la instalación
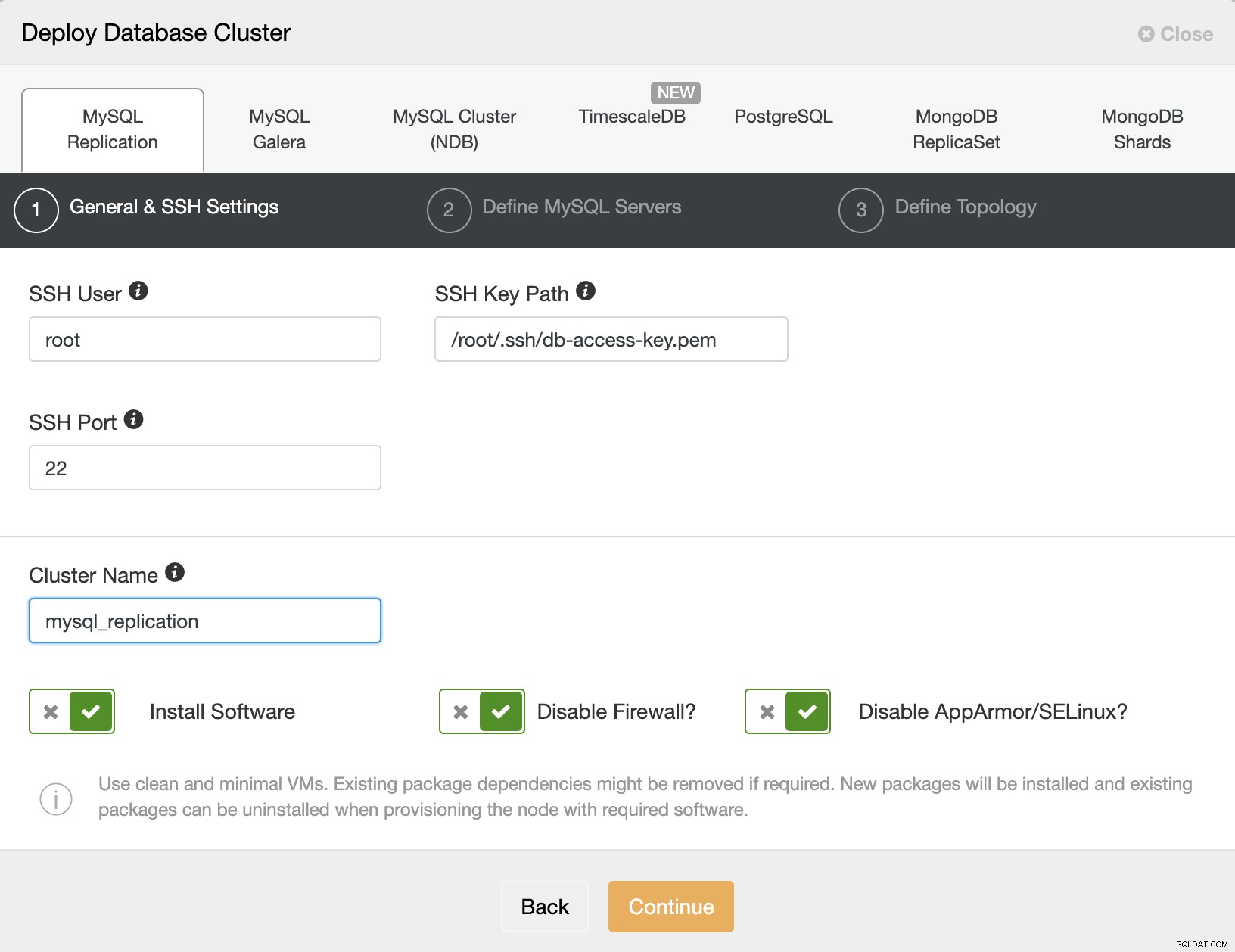
Configuración general y SSH
Ingrese el usuario SSH, la clave y la contraseña, el puerto SSH y el nombre del clúster
Luego seleccione 'Continuar'
Definir servidores MySQL
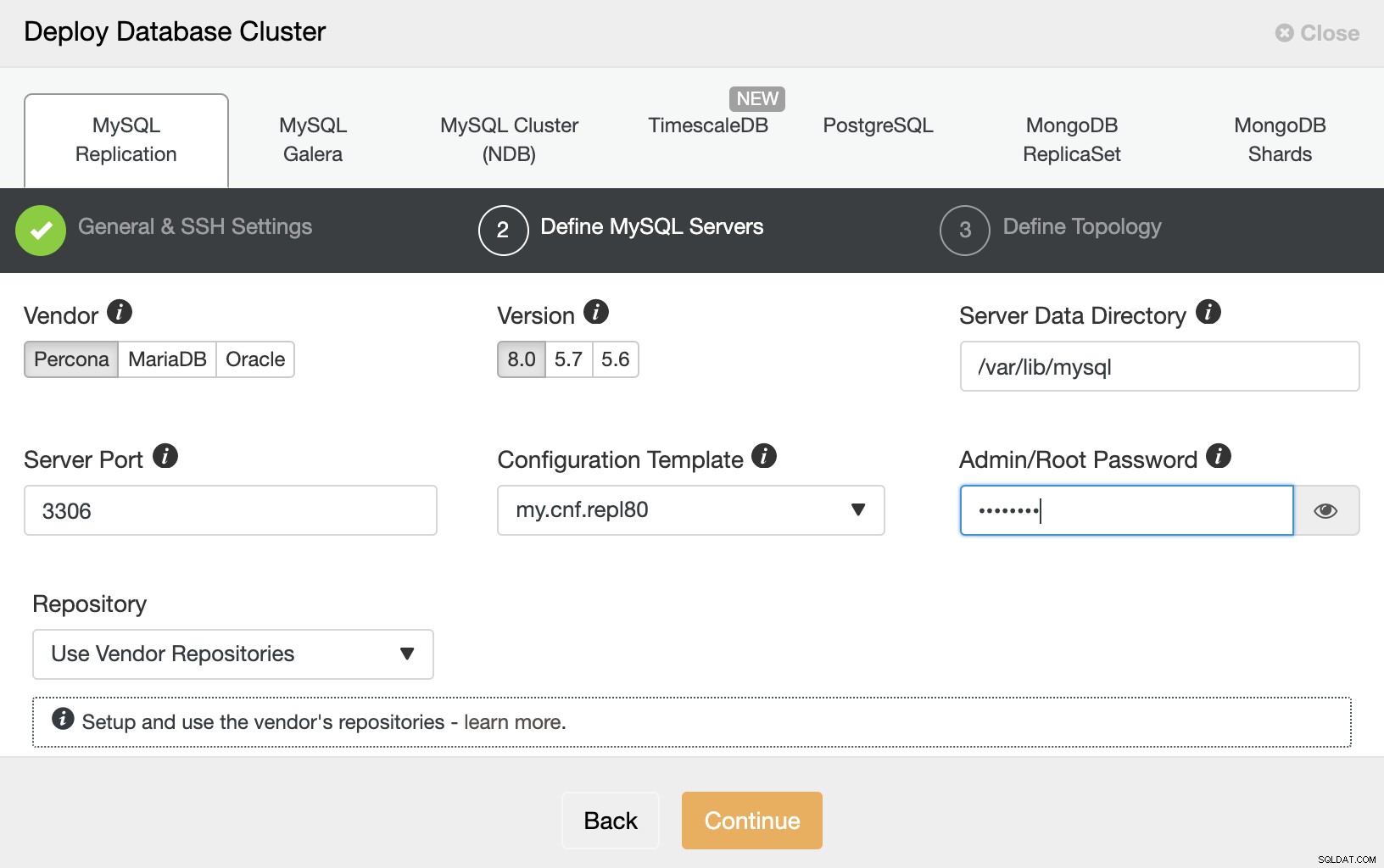
Seleccione el proveedor, el número de versión y la contraseña raíz de MySQL, luego haga clic en 'Continuar'
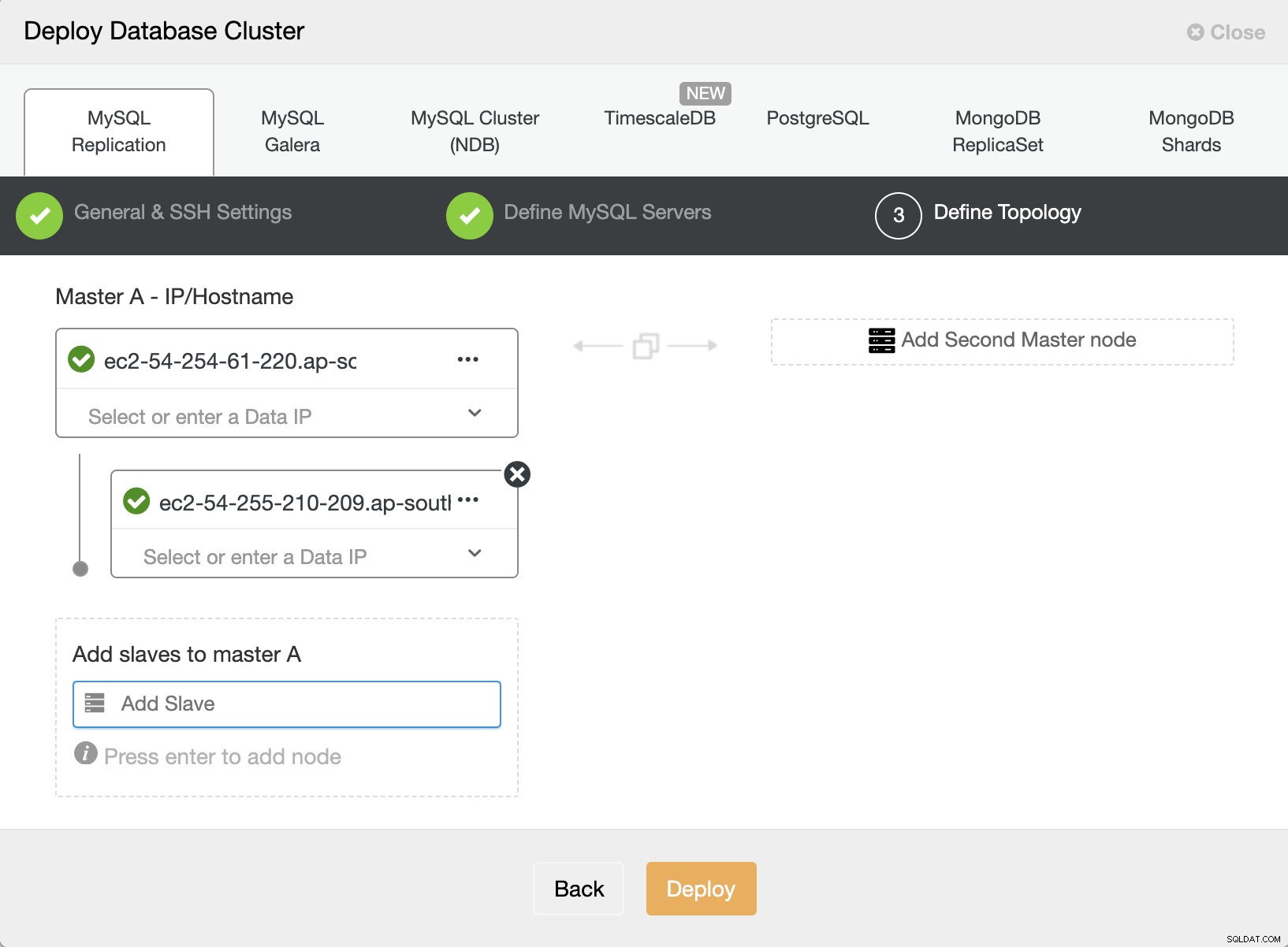
Definir topología
Como recordará, tenemos dos nodos creados en AWS. Podemos usar ambos aquí. Uno será nuestro amo, el otro debe ser agregado como esclavo. Entonces podemos continuar con 'Implementar'
Si lo desea, y si la conectividad entre nubes ya está implementada, también puede configurar la dirección IP de la instancia de GCP en 'Agregar esclavos al maestro A' y luego continuar con ' Desplegar'. De esta forma, ClusterControl desplegará el maestro y ambos esclavos al mismo tiempo.
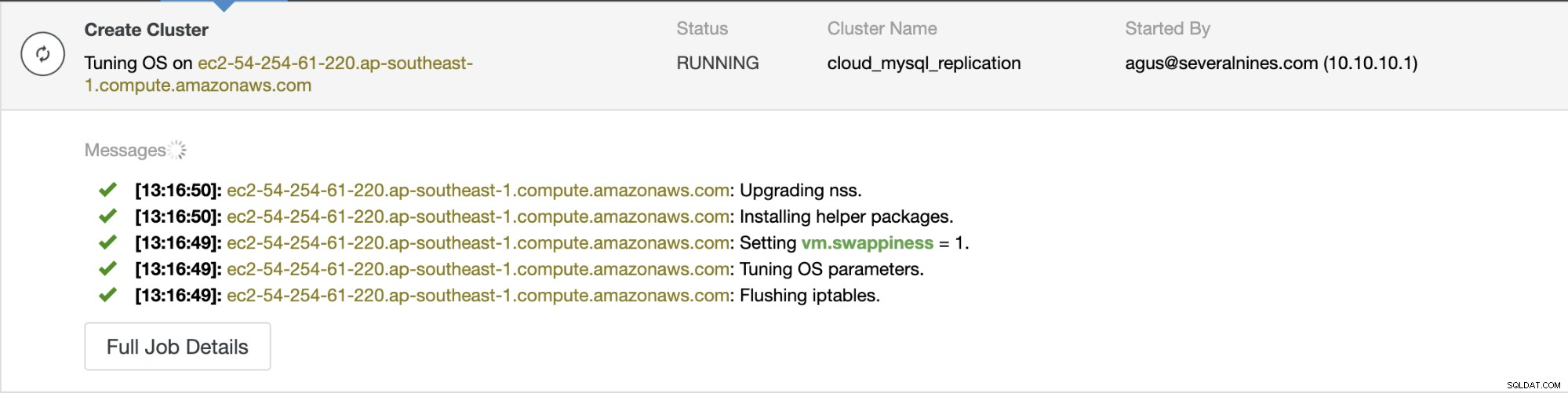
Una vez iniciada la implementación, puede monitorear el progreso en la pestaña Actividad. Puede ver el ejemplo de los mensajes de progreso a continuación. Ahora es el momento de esperar hasta que se complete el trabajo.
Una vez que se completa, puede ver el clúster recién creado llamado "Cloud Replicación de MySQL”.
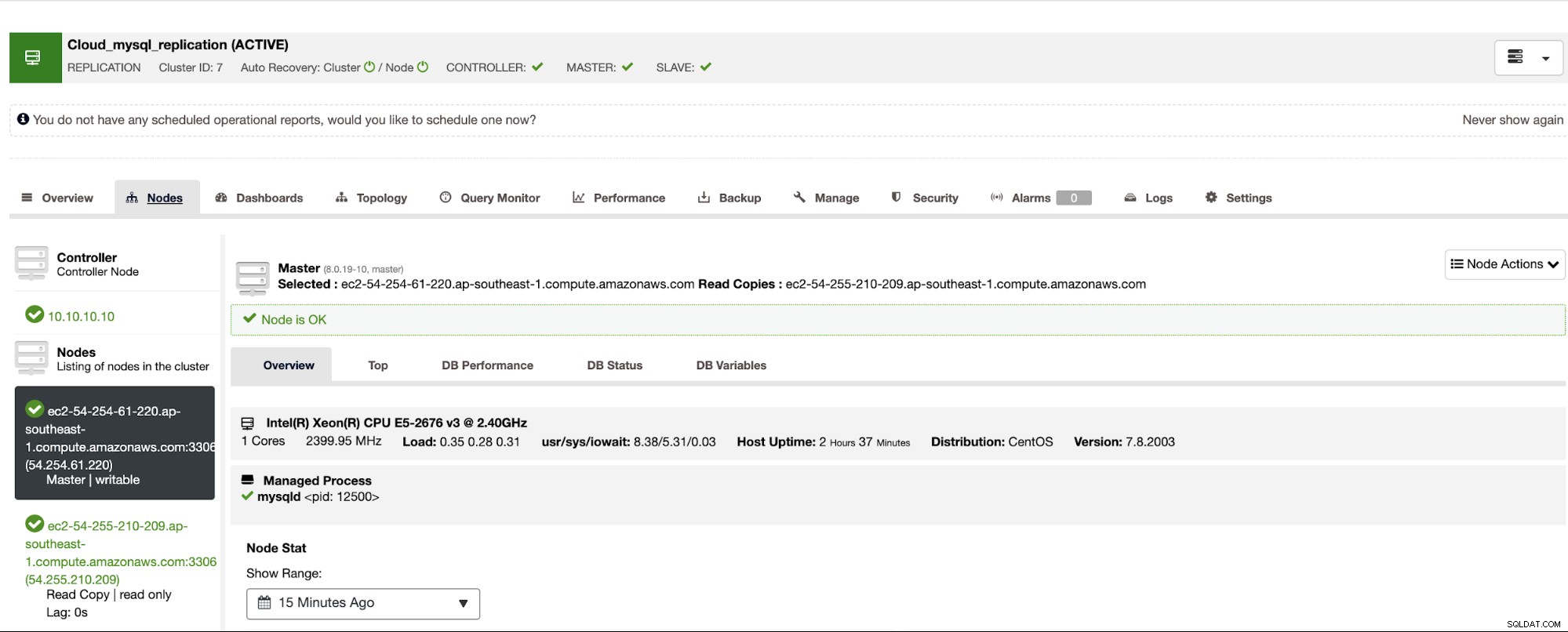
Si ya agregó el nodo GCP como segundo esclavo en el asistente de implementación, ya ha completado la configuración de maestro-esclavo entre las instancias de AWS y GCP.
Si no es así, puede agregar el esclavo GCP al clúster en ejecución. Asegúrese de que la conectividad esté lista antes de continuar.
Agregar un nuevo esclavo desde Google Cloud Platform
Después de que se haya creado la replicación de MySQL en AWS, puede continuar agregando su nodo en GCP como un nuevo esclavo. Puede lograrlo realizando los siguientes pasos::
- En la lista de clústeres, busque su nuevo clúster y luego haga clic en
 y seleccione 'Agregar esclavo de replicación'
Aparecerá el asistente
y seleccione 'Agregar esclavo de replicación'
Aparecerá el asistente -
- Agregar esclavo de replicación, como puede ver a continuación.
- Continúe eligiendo la IP de la instancia maestra (ubicada en AWS) e ingresando la dirección IP y el puerto de la instancia de GCP que desea usar como esclavo en el cuadro "Nombre de host/IP esclavo". Una vez que llene todo, puede continuar haciendo clic en 'Agregar esclavo de replicación'.

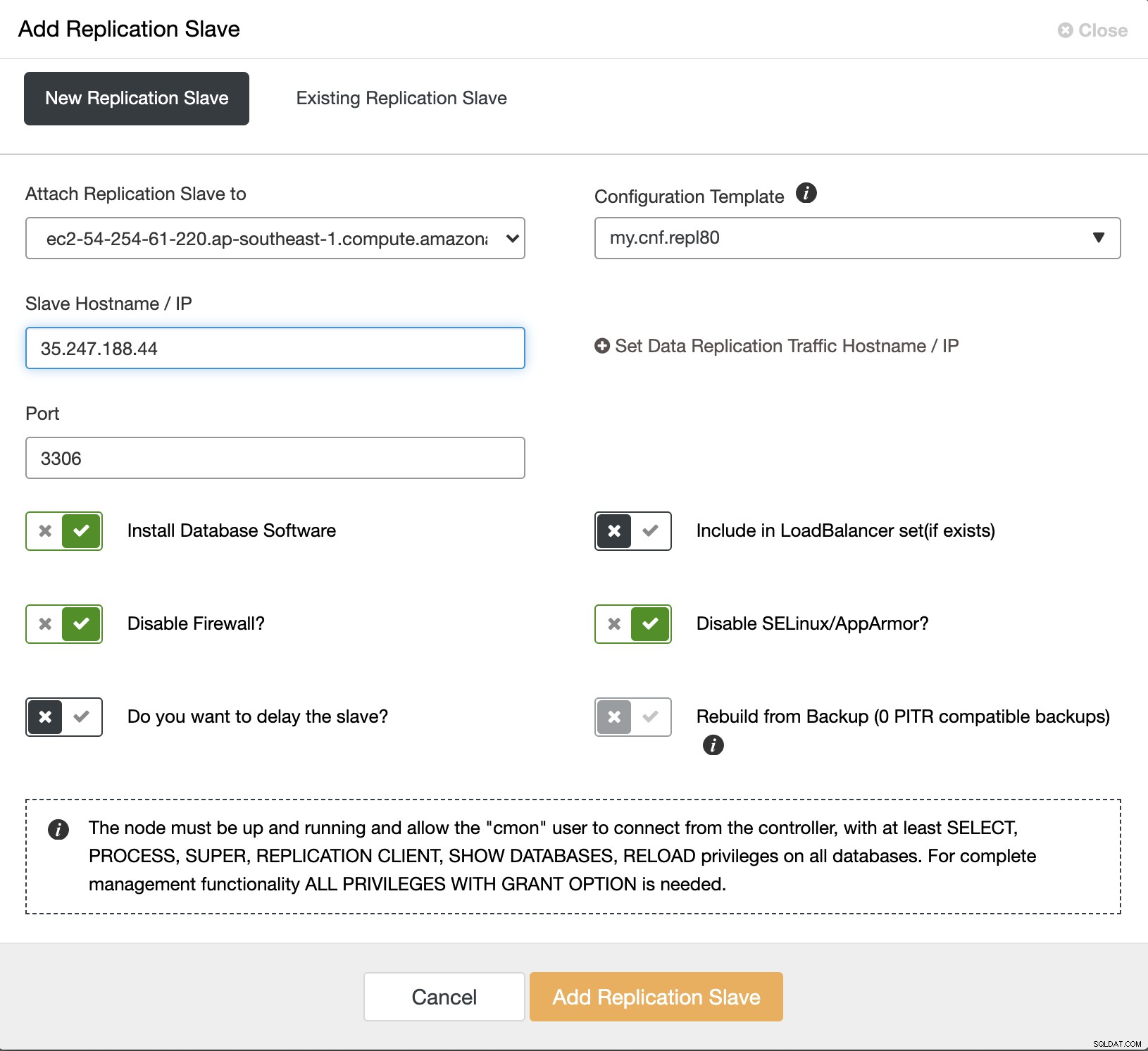
Como antes, puede monitorear el progreso en la pestaña de actividad. Ahora es el momento de esperar hasta que se complete el trabajo.
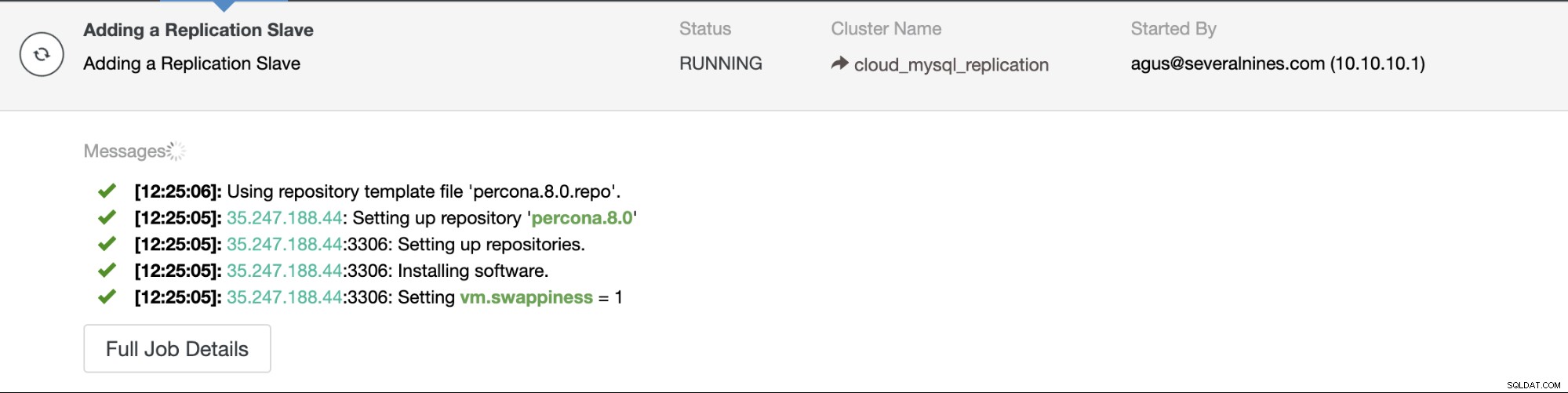
Una vez que se realiza la implementación, podemos verificar el clúster en la pestaña de topología.
Puede ver la topología de nuestro clúster maestro-esclavo a continuación.
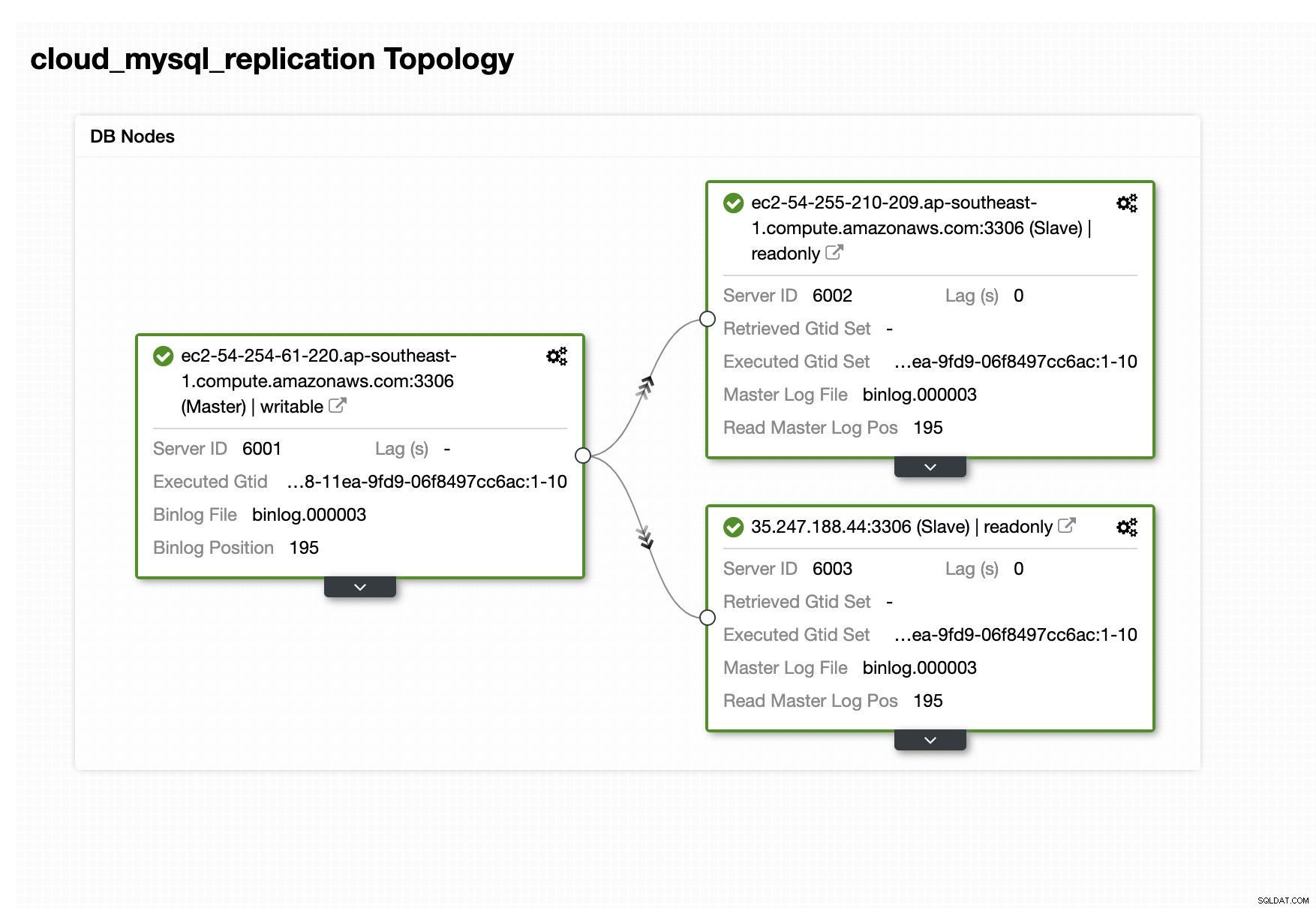
Como puede ver, tenemos un maestro y un esclavo en AWS y también tenemos un esclavo en GCP, lo que facilita que nuestra base de datos sobreviva a cualquier interrupción que ocurra en uno de nuestros proveedores de nube.
Conclusión
Para la alta disponibilidad de los servicios de base de datos, una implementación de varias nubes tiene un papel muy importante para que esto suceda. ClusterControl se creó para navegar por este proceso y facilitar al usuario la administración de las implementaciones de múltiples nubes.
Una de las cosas críticas a tener en cuenta al realizar la implementación de múltiples nubes son los aspectos de seguridad. Como mencionamos anteriormente, puede configurar una VPN de sitio a sitio entre los dos proveedores de la nube como la mejor práctica que se puede aplicar. También hay otras opciones como túneles SSH.