Al trabajar con nombres de personas y hacer búsquedas aproximadas sobre ellos, lo que funcionó para mí fue crear una segunda tabla de palabras. También cree una tercera tabla que sea una tabla de intersección para la relación muchos a muchos entre la tabla que contiene el texto y la tabla de palabras. Cuando se agrega una fila a la tabla de texto, se divide el texto en palabras y se rellena la tabla de intersección de manera adecuada, agregando nuevas palabras a la tabla de palabras cuando sea necesario. Una vez que esta estructura está en su lugar, puede realizar búsquedas un poco más rápido, porque solo necesita realizar su función damlev sobre la tabla de palabras únicas. Una simple unión le proporciona el texto que contiene las palabras coincidentes. 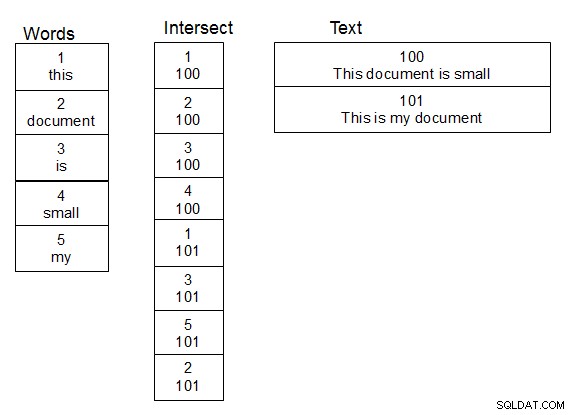
Una consulta de coincidencia de una sola palabra se vería así:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
y dos palabras se verían así (fuera de mi cabeza, por lo que puede que no sea exactamente correcto):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
Las ventajas aquí, a costa de algo de espacio en la base de datos, es que solo tiene que aplicar la función damlev, que consume mucho tiempo, a las palabras únicas, que probablemente solo se contarán en decenas de miles, independientemente del tamaño de su tabla de texto. Esto es importante, porque la UDF damlev no usará índices:escaneará toda la tabla en la que se aplica para calcular un valor para cada fila. Escanear solo las palabras únicas debería ser mucho más rápido. La otra ventaja es que el damlev se aplica a nivel de palabra, que parece ser lo que está pidiendo. Otra ventaja es que puede expandir la consulta para permitir la búsqueda de varias palabras y clasificar los resultados agrupando las filas de intersección coincidentes en TextId y clasificando según el recuento de coincidencias.