Agregar un índice filtrado puede tener efectos secundarios sorprendentes en las consultas existentes, incluso cuando parece que el nuevo índice filtrado no tiene ninguna relación. Esta publicación analiza un ejemplo que afecta a las declaraciones DELETE que resultan en un rendimiento deficiente y un mayor riesgo de interbloqueo.
Entorno de prueba
La siguiente tabla se utilizará a lo largo de esta publicación:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); La siguiente instrucción crea 499 999 filas de datos de muestra:
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; Eso usa una tabla de números como fuente de enteros consecutivos del 1 al 499,999. En caso de que no tenga uno de esos en su entorno de prueba, el siguiente código se puede usar para crear de manera eficiente uno que contenga números enteros del 1 al 1,000,000:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); La base de las pruebas posteriores será eliminar filas de la tabla de prueba para una fecha de inicio en particular. Para que el proceso de identificación de filas para eliminar sea más eficiente, agregue este índice no agrupado:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); Los datos de muestra
Una vez que se completen esos pasos, la muestra se verá así:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
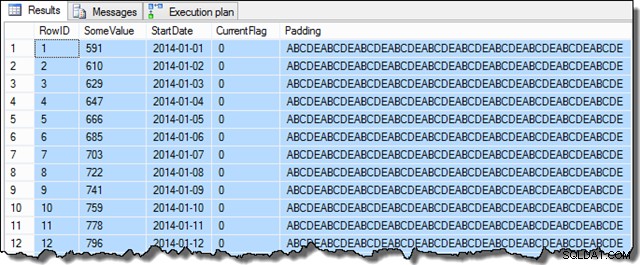
Los datos de la columna SomeValue pueden ser ligeramente diferentes debido a la generación pseudoaleatoria, pero esta diferencia no es importante. En general, los datos de muestra contienen 16 129 filas para cada una de las 31 fechas StartDate en enero de 2014:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
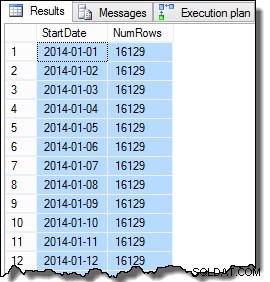
El último paso que debemos realizar para que los datos sean algo realistas es establecer la columna CurrentFlag en verdadero para el RowID más alto para cada StartDate. El siguiente script realiza esta tarea:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; El plan de ejecución de esta actualización presenta una combinación Segment-Top para ubicar de manera eficiente el RowID más alto por día:

Observe cómo el plan de ejecución se parece poco a la forma escrita de la consulta. Este es un gran ejemplo de cómo funciona el optimizador a partir de la especificación lógica de SQL, en lugar de implementar el SQL directamente. En caso de que se lo pregunte, se requiere el Eager Table Spool en ese plan para la Protección de Halloween.
Eliminación de un día de datos
Bien, con los preliminares completados, la tarea en cuestión es eliminar filas para una Fecha de inicio en particular. Este es el tipo de consulta que puede ejecutar de forma rutinaria en la fecha más antigua de una tabla, cuando los datos han llegado al final de su vida útil.
Tomando el 1 de enero de 2014 como ejemplo, la consulta de eliminación de prueba es simple:
DELETE dbo.Data WHERE StartDate = '20140101';
El plan de ejecución también es bastante simple, aunque vale la pena analizarlo con un poco de detalle:

Análisis del plan
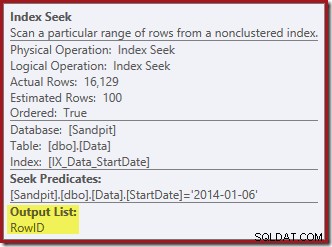
La Búsqueda de índice en el extremo derecho usa el índice no agrupado para buscar filas para el valor de Fecha de inicio especificado. Devuelve solo los valores de RowID que encuentra, como lo confirma la información sobre herramientas del operador:
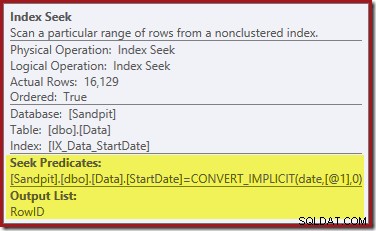
Si se pregunta cómo logra el índice StartDate devolver el RowID, recuerde que RowID es el índice agrupado único para la tabla, por lo que se incluye automáticamente en el índice no agrupado StartDate.
El siguiente operador en el plan es la eliminación de índice agrupado. Esto utiliza el valor RowID encontrado por Index Seek para ubicar filas para eliminar.
El operador final en el plan es una eliminación de índice. Esto elimina filas del índice no agrupado IX_Data_StartDate que están relacionados con el ID de fila eliminado por la eliminación del índice agrupado. Para ubicar estas filas en el índice no agrupado, el procesador de consultas necesita la fecha de inicio (la clave para el índice no agrupado).
Recuerde que la búsqueda de índice original no devolvió la fecha de inicio, solo el ID de fila. Entonces, ¿cómo obtiene el procesador de consultas la fecha de inicio para la eliminación del índice? En este caso particular, el optimizador podría haber notado que el valor StartDate es una constante y lo optimizó, pero esto no es lo que sucedió. La respuesta es que el operador de eliminación de índice agrupado lee el valor StartDate para la fila actual y lo agrega a la secuencia. Compare la Lista de salida de la Eliminación de índice agrupado que se muestra a continuación, con la de Búsqueda de índice justo arriba:
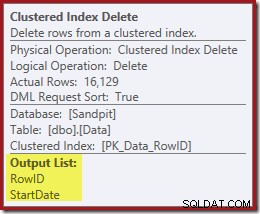
Puede parecer sorprendente ver un operador Eliminar leyendo datos, pero así es como funciona. El procesador de consultas sabe que tendrá que ubicar la fila en el índice agrupado para eliminarlo, por lo que también podría diferir la lectura de las columnas necesarias para mantener los índices no agrupados hasta ese momento, si puede.
Agregar un índice filtrado
Ahora imagine que alguien tiene una consulta crucial en esta tabla que está funcionando mal. El útil DBA realiza un análisis y agrega el siguiente índice filtrado:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; El nuevo índice filtrado tiene el efecto deseado en la consulta problemática y todos están contentos. Tenga en cuenta que el nuevo índice no hace referencia en absoluto a la columna StartDate, por lo que no esperamos que afecte en absoluto nuestra consulta de eliminación de días.
Eliminar un día con el índice filtrado en su lugar
Podemos probar esa expectativa eliminando datos por segunda vez:
DELETE dbo.Data WHERE StartDate = '20140102';
De repente, el plan de ejecución ha cambiado a un escaneo de índice agrupado paralelo:

Observe que no hay un operador de eliminación de índice separado para el nuevo índice filtrado. El optimizador ha optado por mantener este índice dentro del operador de eliminación de índice agrupado. Esto se destaca en SQL Sentry Plan Explorer como se muestra arriba ("+1 índices no agrupados") con detalles completos en la información sobre herramientas:
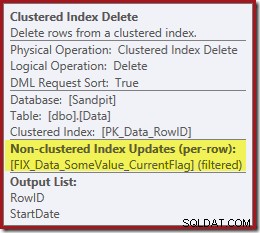
Si la tabla es grande (piense en un almacén de datos), este cambio a un escaneo paralelo podría ser muy significativo. ¿Qué sucedió con la búsqueda de índice agradable en StartDate y por qué un índice filtrado completamente sin relación cambió las cosas tan drásticamente?
Encontrar el problema
La primera pista proviene de observar las propiedades del análisis de índice agrupado:
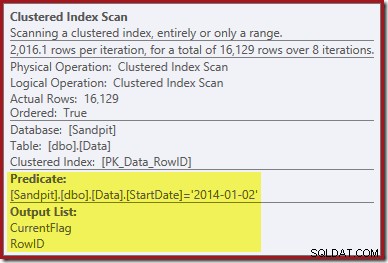
Además de encontrar valores de RowID para que los elimine el operador de eliminación de índice agrupado, este operador ahora lee los valores de CurrentFlag. La necesidad de esta columna no está clara, pero al menos comienza a explicar la decisión de escanear:la columna CurrentFlag no es parte de nuestro índice no agrupado StartDate.
Podemos confirmar esto reescribiendo la consulta de eliminación para forzar el uso del índice no agrupado StartDate:
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; El plan de ejecución está más cerca de su forma original, pero ahora incluye una búsqueda de claves:
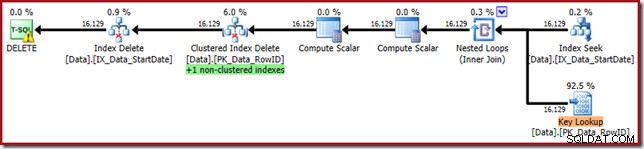
Las propiedades de búsqueda de claves confirman que este operador está recuperando valores de CurrentFlag:
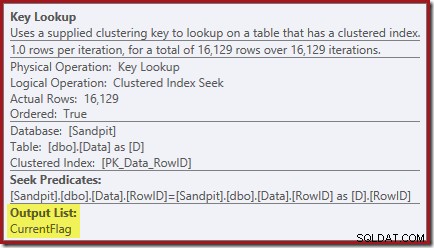
Es posible que también haya notado los triángulos de advertencia en los dos últimos planes. Estas son las advertencias de índice que faltan:
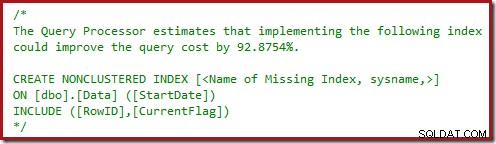
Esta es una confirmación adicional de que a SQL Server le gustaría ver la columna CurrentFlag incluida en el índice no agrupado. El motivo del cambio a un escaneo de índice agrupado paralelo ahora está claro:el procesador de consultas decide que escanear la tabla será más económico que realizar búsquedas clave.
Sí, pero ¿por qué?
Todo esto es muy raro. En el plan de ejecución original, SQL Server podía leer se necesitan datos de columna adicionales para mantener los índices no agrupados en el operador de eliminación de índice agrupado. El valor de la columna CurrentFlag es necesario para mantener el índice filtrado, entonces, ¿por qué SQL Server no lo maneja de la misma manera?
La respuesta corta es que puede, pero solo si el índice filtrado se mantiene en un operador de eliminación de índice separado. Podemos forzar esto para la consulta actual utilizando el indicador de seguimiento no documentado 8790. Sin este indicador, el optimizador elige si desea mantener cada índice en un operador separado o como parte de la operación de la tabla base.
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
El plan de ejecución vuelve a buscar el índice no agrupado StartDate:
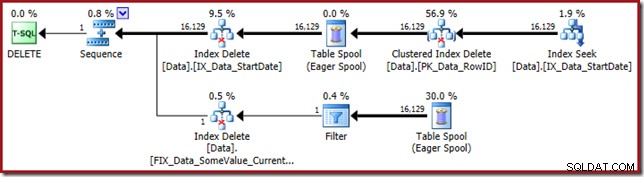
Index Seek devuelve solo valores RowID (no CurrentFlag):
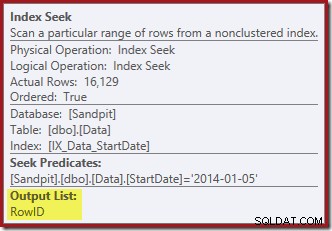
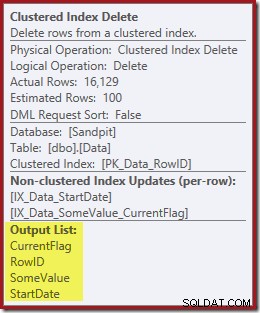
Y la eliminación de índice agrupado lecturas las columnas necesarias para mantener los índices no agrupados, incluido CurrentFlag:
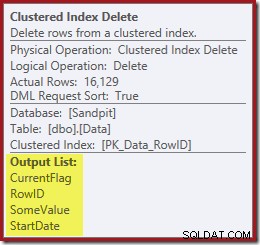
Estos datos se escriben ansiosamente en una cola de tabla, que es la reproducción de cada índice que necesita mantenimiento. Observe también el operador de filtro explícito antes del operador de eliminación de índice para el índice filtrado.
Otro patrón a tener en cuenta
Este problema no siempre da como resultado una exploración de tabla en lugar de una búsqueda de índice. Para ver un ejemplo de esto, agregue otro índice a la tabla de prueba:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); Tenga en cuenta que este índice no filtrada y no involucra la columna StartDate. Ahora intente una consulta de eliminación de días nuevamente:
DELETE dbo.Data WHERE StartDate = '20140104';
El optimizador ahora presenta este monstruo:
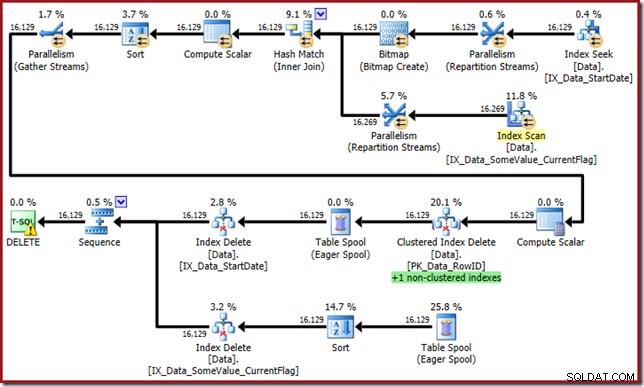
Este plan de consulta tiene un alto factor de sorpresa, pero la causa principal es la misma. Todavía se necesita la columna CurrentFlag, pero ahora el optimizador elige una estrategia de intersección de índices para obtenerla en lugar de una exploración de tabla. El uso de la marca de seguimiento fuerza un plan de mantenimiento por índice y la cordura se restaura una vez más (la única diferencia es una repetición de carrete adicional para mantener el nuevo índice):
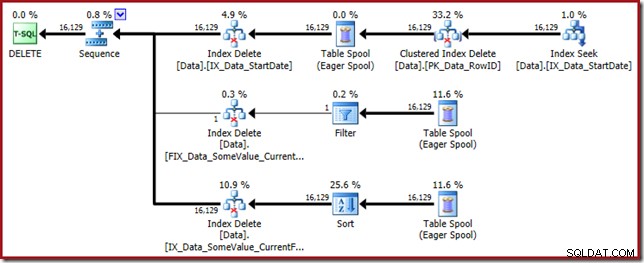
Solo los índices filtrados causan esto
Este problema solo ocurre si el optimizador elige mantener un índice filtrado en un operador de eliminación de índice agrupado. Los índices no filtrados no se ven afectados, como muestra el siguiente ejemplo. El primer paso es eliminar el índice filtrado:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
Ahora necesitamos escribir la consulta de una manera que convenza al optimizador de mantener todos los índices en la Eliminación de índice agrupado. Mi elección para esto es usar una variable y una sugerencia para reducir las expectativas de recuento de filas del optimizador:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); El plan de ejecución es:
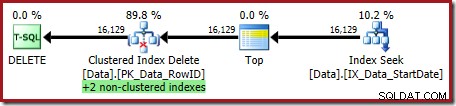
Ambos índices no agrupados se mantienen mediante la eliminación del índice agrupado:
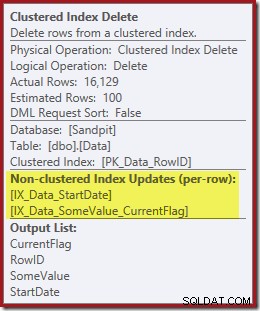
Index Seek devuelve solo el RowID:
El operador de eliminación recupera internamente las columnas necesarias para el mantenimiento del índice; estos detalles no están expuestos en la salida del plan de demostración (por lo que la lista de salida del operador de eliminación estaría vacía). Agregué una OUTPUT cláusula a la consulta para mostrar la eliminación del índice agrupado una vez más devolviendo datos que no recibió en su entrada:
Reflexiones finales
Esta es una limitación difícil de solucionar. Por un lado, generalmente no queremos usar marcas de rastreo no documentadas en los sistemas de producción.
La 'solución' natural es agregar las columnas necesarias para el mantenimiento del índice filtrado a todos. índices no agrupados que podrían usarse para ubicar filas para eliminar. Esta no es una propuesta muy atractiva, desde varios puntos de vista. Otra alternativa es simplemente no usar índices filtrados, pero eso tampoco es lo ideal.
Mi sensación es que el optimizador de consultas debería considerar una alternativa de mantenimiento por índice para los índices filtrados automáticamente, pero su razonamiento parece estar incompleto en esta área en este momento (y se basa en heurística simple en lugar de calcular correctamente el costo por índice/por fila). alternativas).
Para poner algunos números alrededor de esa afirmación, el plan de análisis de índice agrupado en paralelo elegido por el optimizador llegó a 5.5 unidades en mis pruebas. La misma consulta con la marca de rastreo estima un costo de 1.4 unidades. Con el tercer índice implementado, el plan de intersección de índice paralelo elegido por el optimizador tuvo un costo estimado de 4.9 , mientras que el plan de marca de rastreo llegó a 2.7 unidades (todas las pruebas en SQL Server 2014 RTM CU1 compilación 12.0.2342 bajo el modelo de estimación de cardinalidad 120 y con el indicador de rastreo 4199 habilitado).
Considero que esto es un comportamiento que debe mejorarse. Puede votar para estar de acuerdo o en desacuerdo conmigo en este elemento de Connect.