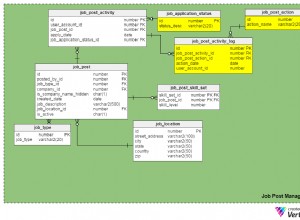
Actualización:esta funcionalidad se fusionó en pandas master y se lanzará en 0.15 (probablemente a fines de septiembre), ¡gracias a @artemyk! Consulte https://github.com/pydata/pandas/pull/8062
Entonces, a partir de 0.15, puede especificar el chunksize argumento y por ej. simplemente haz:
df.to_sql('table', engine, chunksize=20000)