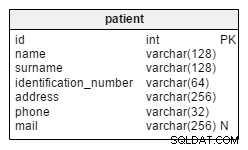
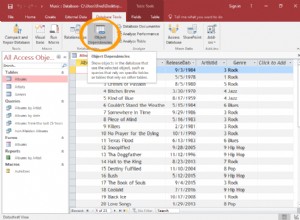
Esto obtendría lo contrario (es decir, omitir los duplicados):
SELECT c1.*
FROM CoreTracks c1
,(SELECT Title, ArtistID, MAX(FileSize) AS maxFileSize, MAX(BitRate) maxBitRate
FROM CoreTracks
GROUP BY Title, ArtistID) c2
WHERE c1.Title = c2.Title
AND c1.ArtistID = c2.ArtistID
AND (c1.FileSize = c2.maxFileSize OR c1.BitRate = c2.maxBitRate)
Y los duplicados:
SELECT c1.*
FROM CoreTracks c1
,(SELECT Title, ArtistID, MAX(FileSize) AS maxFileSize, MAX(BitRate) maxBitRate
FROM CoreTracks
GROUP BY Title, ArtistID) c2
WHERE c1.Title = c2.Title
AND c1.ArtistID = c2.ArtistID
AND (c1.FileSize != c2.maxFileSize AND c1.BitRate != c2.maxBitRate)