Históricamente, la tarea más difícil al trabajar con PostgreSQL ha sido lidiar con las actualizaciones. La forma de actualización más intuitiva que se le ocurre es generar una réplica en una nueva versión y realizar una conmutación por error de la aplicación en ella. Con PostgreSQL, esto simplemente no era posible de forma nativa. Para realizar las actualizaciones, necesitaba pensar en otras formas de actualización, como usar pg_upgrade, volcar y restaurar, o usar algunas herramientas de terceros como Slony o Bucardo, todas ellas con sus propias advertencias.
¿Por qué fue esto? Por la forma en que PostgreSQL implementa la replicación.
La replicación de transmisión incorporada de PostgreSQL es lo que se llama física:replicará los cambios en un nivel de byte por byte, creando una copia idéntica de la base de datos en otro servidor. Este método tiene muchas limitaciones cuando se piensa en una actualización, ya que simplemente no puede crear una réplica en una versión de servidor diferente o incluso en una arquitectura diferente.
Entonces, aquí es donde PostgreSQL 10 cambia las reglas del juego. Con estas nuevas versiones 10 y 11, PostgreSQL implementa la replicación lógica integrada que, a diferencia de la replicación física, puede replicar entre diferentes versiones principales de PostgreSQL. Esto, por supuesto, abre una nueva puerta para mejorar las estrategias.
En este blog, veamos cómo podemos actualizar nuestro PostgreSQL 10 a PostgreSQL 11 sin tiempo de inactividad mediante la replicación lógica. En primer lugar, veamos una introducción a la replicación lógica.
¿Qué es la replicación lógica?
La replicación lógica es un método para replicar objetos de datos y sus cambios, en función de su identidad de replicación (generalmente una clave principal). Se basa en un modo de publicación y suscripción, donde uno o más suscriptores se suscriben a una o más publicaciones en un nodo de publicación.
Una publicación es un conjunto de cambios generados a partir de una tabla o un grupo de tablas (también denominado conjunto de replicación). El nodo donde se define una publicación se denomina editor. Una suscripción es el lado descendente de la replicación lógica. El nodo donde se define una suscripción se denomina suscriptor y define la conexión a otra base de datos y conjunto de publicaciones (una o más) a las que desea suscribirse. Los suscriptores extraen datos de las publicaciones a las que se suscriben.
La replicación lógica se construye con una arquitectura similar a la replicación de transmisión física. Se implementa mediante los procesos "walsender" y "apply". El proceso de walsender inicia la decodificación lógica de WAL y carga el complemento de decodificación lógica estándar. El complemento transforma los cambios leídos de WAL al protocolo de replicación lógica y filtra los datos de acuerdo con la especificación de publicación. Luego, los datos se transfieren de forma continua utilizando el protocolo de replicación de transmisión al trabajador de aplicación, que asigna los datos a las tablas locales y aplica los cambios individuales a medida que se reciben, en un orden transaccional correcto.
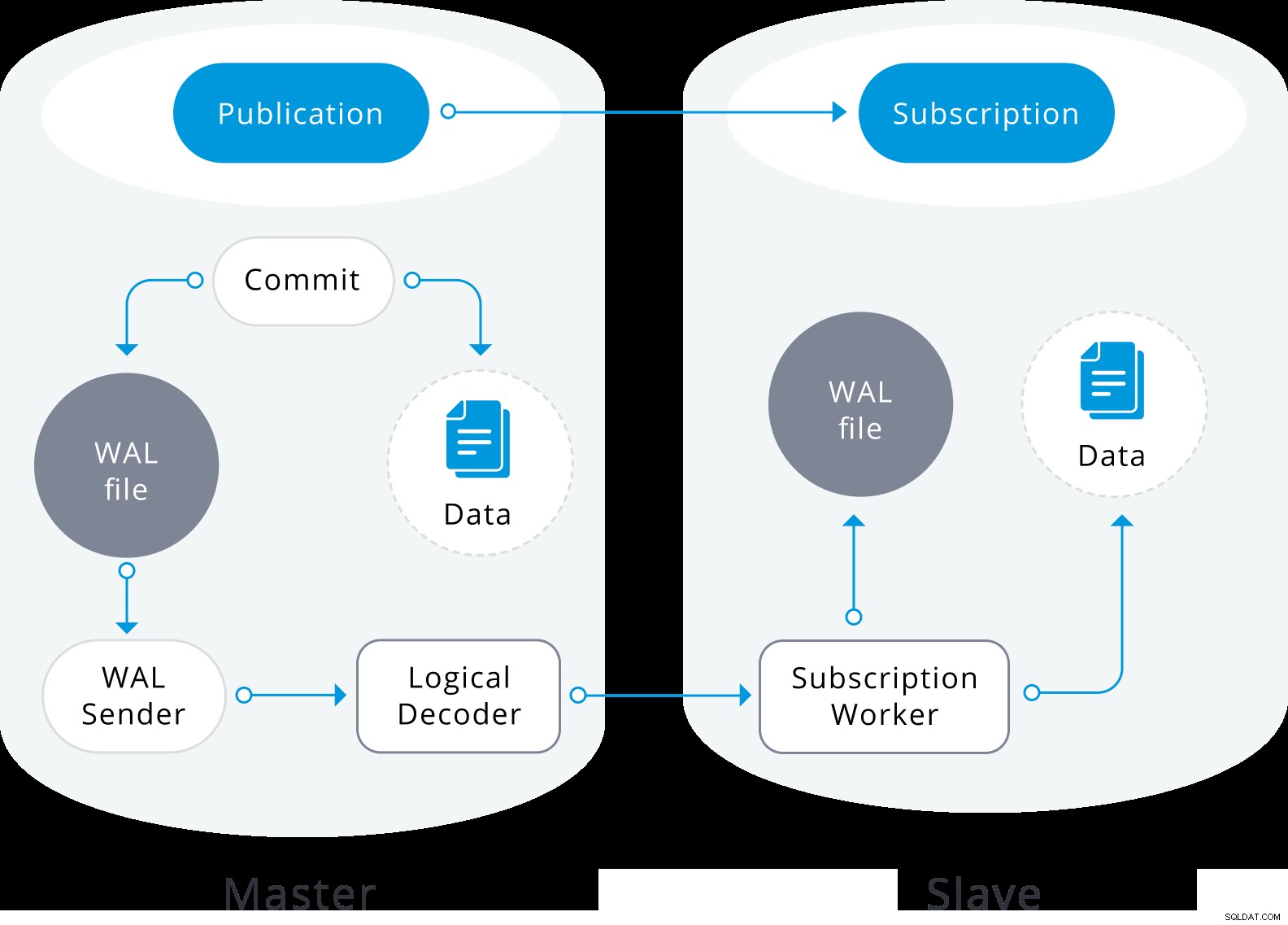 Diagrama de replicación lógica
Diagrama de replicación lógica La replicación lógica comienza tomando una instantánea de los datos en la base de datos del editor y copiándola al suscriptor. Los datos iniciales en las tablas suscritas existentes se capturan y se copian en una instancia paralela de un tipo especial de proceso de aplicación. Este proceso creará su propia ranura de replicación temporal y copiará los datos existentes. Una vez que se copian los datos existentes, el trabajador ingresa al modo de sincronización, lo que garantiza que la tabla se actualice a un estado sincronizado con el proceso de aplicación principal mediante la transmisión de cualquier cambio que haya ocurrido durante la copia de datos inicial mediante la replicación lógica estándar. Una vez que se realiza la sincronización, el control de la replicación de la tabla se devuelve al proceso de aplicación principal donde la replicación continúa con normalidad. Los cambios en el editor se envían al suscriptor a medida que ocurren en tiempo real.
Puede encontrar más información sobre la replicación lógica en los siguientes blogs:
- Una descripción general de la replicación lógica en PostgreSQL
- Replicación de transmisión de PostgreSQL frente a replicación lógica
Cómo actualizar PostgreSQL 10 a PostgreSQL 11 mediante la replicación lógica
Entonces, ahora que sabemos de qué se trata esta nueva función, podemos pensar en cómo podemos usarla para resolver el problema de actualización.
Vamos a configurar la replicación lógica entre dos versiones principales diferentes de PostgreSQL (10 y 11) y, por supuesto, después de que esto funcione, solo se trata de realizar una conmutación por error de la aplicación en la base de datos con la versión más nueva.
Vamos a realizar los siguientes pasos para poner en funcionamiento la replicación lógica:
- Configurar el nodo de publicación
- Configurar el nodo de suscriptor
- Crear el usuario suscriptor
- Crear una publicación
- Cree la estructura de la tabla en el suscriptor
- Crear la suscripción
- Comprobar el estado de la replicación
Así que comencemos.
Del lado del editor, vamos a configurar los siguientes parámetros en el archivo postgresql.conf:
- listen_addresses:en qué direcciones IP escuchar. Usaremos '*' para todos.
- wal_level:determina cuánta información se escribe en el WAL. Vamos a establecerlo en lógico.
- max_replication_slots:especifica el número máximo de ranuras de replicación que puede admitir el servidor. Debe establecerse al menos en la cantidad de suscripciones que se espera que se conecten, más alguna reserva para la sincronización de tablas.
- max_wal_senders:especifica la cantidad máxima de conexiones simultáneas desde servidores en espera o clientes de copia de seguridad base de transmisión. Debe establecerse al menos igual que max_replication_slots más la cantidad de réplicas físicas que están conectadas al mismo tiempo.
Tenga en cuenta que algunos de estos parámetros requirieron un reinicio del servicio PostgreSQL para aplicar.
El archivo pg_hba.conf también debe ajustarse para permitir la replicación. Necesitamos permitir que el usuario de replicación se conecte a la base de datos.
Basándonos en esto, configuremos nuestro editor (en este caso, nuestro servidor PostgreSQL 10) de la siguiente manera:
- postgresql.conf:
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
Debemos cambiar el usuario (en nuestro representante de ejemplo), que se usará para la replicación, y la dirección IP 192.168.100.144/32 por la IP que corresponde a nuestro PostgreSQL 11.
En el lado del suscriptor, también requiere que se configure max_replication_slots. En este caso, debe establecerse al menos en la cantidad de suscripciones que se agregarán al suscriptor.
Los otros parámetros que también deben configurarse aquí son:
- max_logical_replication_workers:especifica la cantidad máxima de trabajadores de replicación lógica. Esto incluye trabajadores de aplicación y trabajadores de sincronización de tablas. Los trabajadores de replicación lógica se toman del grupo definido por max_worker_processes. Debe establecerse al menos en el número de suscripciones, nuevamente más alguna reserva para la sincronización de la tabla.
- max_worker_processes:establece la cantidad máxima de procesos en segundo plano que el sistema puede admitir. Es posible que deba ajustarse para adaptarse a los trabajadores de replicación, al menos max_logical_replication_workers + 1. Este parámetro requiere un reinicio de PostgreSQL.
Entonces, debemos configurar nuestro suscriptor (en este caso nuestro servidor PostgreSQL 11) de la siguiente manera:
- postgresql.conf:
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
Como este PostgreSQL 11 será nuestro nuevo maestro pronto, deberíamos considerar agregar los parámetros wal_level y archive_mode en este paso, para evitar un nuevo reinicio del servicio más tarde.
wal_level = logical
archive_mode = onEstos parámetros serán útiles si queremos agregar un nuevo esclavo de replicación o para usar copias de seguridad de PITR.
En el editor, debemos crear el usuario con el que se conectará nuestro suscriptor:
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLEEl rol utilizado para la conexión de replicación debe tener el atributo REPLICACIÓN. El acceso para el rol debe configurarse en pg_hba.conf y debe tener el atributo LOGIN.
Para poder copiar los datos iniciales, el rol utilizado para la conexión de replicación debe tener el privilegio SELECT en una tabla publicada.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTCrearemos la publicación pub1 en el nodo publicador, para todas las tablas:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONEl usuario que creará una publicación debe tener el privilegio CREAR en la base de datos, pero para crear una publicación que publique todas las tablas automáticamente, el usuario debe ser un superusuario.
Para confirmar la publicación creada vamos a utilizar el catálogo pg_publication. Este catálogo contiene información sobre todas las publicaciones creadas en la base de datos.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | tDescripciones de columna:
- pubname:Nombre de la publicación.
- pubowner:Propietario de la publicación.
- puballtables:si es verdadero, esta publicación incluye automáticamente todas las tablas en la base de datos, incluidas las que se crearán en el futuro.
- pubinsert:si es verdadero, las operaciones INSERT se replican para las tablas de la publicación.
- pubupdate:si es verdadero, las operaciones de ACTUALIZACIÓN se replican para las tablas de la publicación.
- pubdelete:si es verdadero, las operaciones DELETE se replican para las tablas de la publicación.
Como el esquema no está replicado, debemos realizar una copia de seguridad en PostgreSQL 10 y restaurarla en nuestro PostgreSQL 11. La copia de seguridad solo se realizará para el esquema, ya que la información se replicará en la transferencia inicial.
En PostgreSQL 10:
$ pg_dumpall -s > schema.sqlEn PostgreSQL 11:
$ psql -d postgres -f schema.sqlUna vez que tenemos nuestro esquema en PostgreSQL 11, creamos la suscripción, reemplazando los valores de host, dbname, usuario y contraseña con los que corresponden a nuestro entorno.
PostgreSQL 11:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONLo anterior iniciará el proceso de replicación, que sincroniza el contenido de la tabla inicial de las tablas en la publicación y luego comienza a replicar los cambios incrementales en esas tablas.
El usuario que crea una suscripción debe ser un superusuario. El proceso de solicitud de suscripción se ejecutará en la base de datos local con los privilegios de un superusuario.
Para verificar la suscripción creada podemos usar el catálogo pg_stat_subscription. Esta vista contendrá una fila por suscripción para el trabajador principal (con PID nulo si el trabajador no se está ejecutando) y filas adicionales para los trabajadores que manejan la copia de datos inicial de las tablas suscritas.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00Descripciones de columna:
- subid:OID de la suscripción.
- subname:Nombre de la suscripción.
- pid:Id. de proceso del proceso de trabajo de suscripción.
- relid:OID de la relación que está sincronizando el trabajador; nulo para el trabajador de aplicación principal.
- received_lsn:última ubicación de registro de escritura anticipada recibida, el valor inicial de este campo es 0.
- last_msg_send_time:hora de envío del último mensaje recibido del remitente WAL de origen.
- last_msg_receipt_time:hora de recepción del último mensaje recibido del remitente WAL de origen.
- latest_end_lsn:última ubicación de registro de escritura anticipada informada al remitente WAL de origen.
- latest_end_time:hora de la última ubicación de registro de escritura anticipada informada al remitente WAL de origen.
Para verificar el estado de replicación en el maestro podemos usar pg_stat_replication:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncDescripciones de columna:
- pid:ID de proceso de un proceso emisor WAL.
- usesysid:OID del usuario que inició sesión en este proceso de remitente WAL.
- usename:nombre del usuario que inició sesión en este proceso de remitente WAL.
- application_name:Nombre de la aplicación que está conectada a este remitente WAL.
- client_addr:dirección IP del cliente conectado a este remitente WAL. Si este campo es nulo, indica que el cliente está conectado a través de un socket Unix en la máquina del servidor.
- client_hostname:nombre de host del cliente conectado, según lo informado por una búsqueda inversa de DNS de client_addr. Este campo solo será no nulo para conexiones IP, y solo cuando log_hostname esté habilitado.
- client_port:número de puerto TCP que el cliente está usando para comunicarse con este remitente WAL, o -1 si se usa un socket Unix.
- backend_start:hora en que se inició este proceso.
- backend_xmin:el horizonte xmin de este standby informado por hot_standby_feedback.
- estado:estado actual del remitente WAL. Los valores posibles son:inicio, puesta al día, transmisión, copia de seguridad y detención.
- sent_lsn:última ubicación de registro de escritura anticipada enviada en esta conexión.
- write_lsn:última ubicación de registro de escritura anticipada escrita en el disco por este servidor en espera.
- flush_lsn:última ubicación de registro de escritura anticipada vaciada en el disco por este servidor en espera.
- replay_lsn:última ubicación de registro de escritura anticipada reproducida en la base de datos en este servidor en espera.
- write_lag:tiempo transcurrido entre el vaciado local de WAL reciente y la recepción de la notificación de que este servidor en espera lo ha escrito (pero aún no lo ha vaciado ni aplicado).
- flush_lag:tiempo transcurrido entre el vaciado local de WAL reciente y la recepción de la notificación de que este servidor en espera lo ha escrito y vaciado (pero aún no lo ha aplicado).
- replay_lag:tiempo transcurrido entre el vaciado local de WAL reciente y la recepción de la notificación de que este servidor en espera lo ha escrito, vaciado y aplicado.
- sync_priority:Prioridad de este servidor en espera para ser elegido como el servidor en espera síncrono en una replicación síncrona basada en prioridad.
- sync_state:estado sincrónico de este servidor en espera. Los valores posibles son asíncrono, potencial, sincronizado, quórum.
Para verificar cuando finaliza la transferencia inicial, podemos ver el registro de PostgreSQL en el suscriptor:
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedO comprobando la variable srsubstate en el catálogo pg_subscription_rel. Este catálogo contiene el estado de cada relación replicada en cada suscripción.
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90Descripciones de columna:
- srsubid:Referencia a suscripción.
- srrelid:Referencia a la relación.
- srsubstate:código de estado:i =inicializar, d =los datos se están copiando, s =sincronizados, r =listo (replicación normal).
- srsublsn:finaliza el LSN para los estados s y r.
Podemos insertar algunos registros de prueba en nuestro PostgreSQL 10 y validar que los tenemos en nuestro PostgreSQL 11:
PostgreSQL 10:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)En este punto, tenemos todo listo para apuntar nuestra aplicación a nuestro PostgreSQL 11.
Para esto, antes que nada, necesitamos confirmar que no tenemos retraso en la replicación.
En el maestro:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0Y ahora, solo necesitamos cambiar nuestro punto final de nuestra aplicación o balanceador de carga (si tenemos uno) al nuevo servidor PostgreSQL 11.
Si tenemos un balanceador de carga como HAProxy, podemos configurarlo usando el PostgreSQL 10 como activo y el PostgreSQL 11 como respaldo, de esta forma:
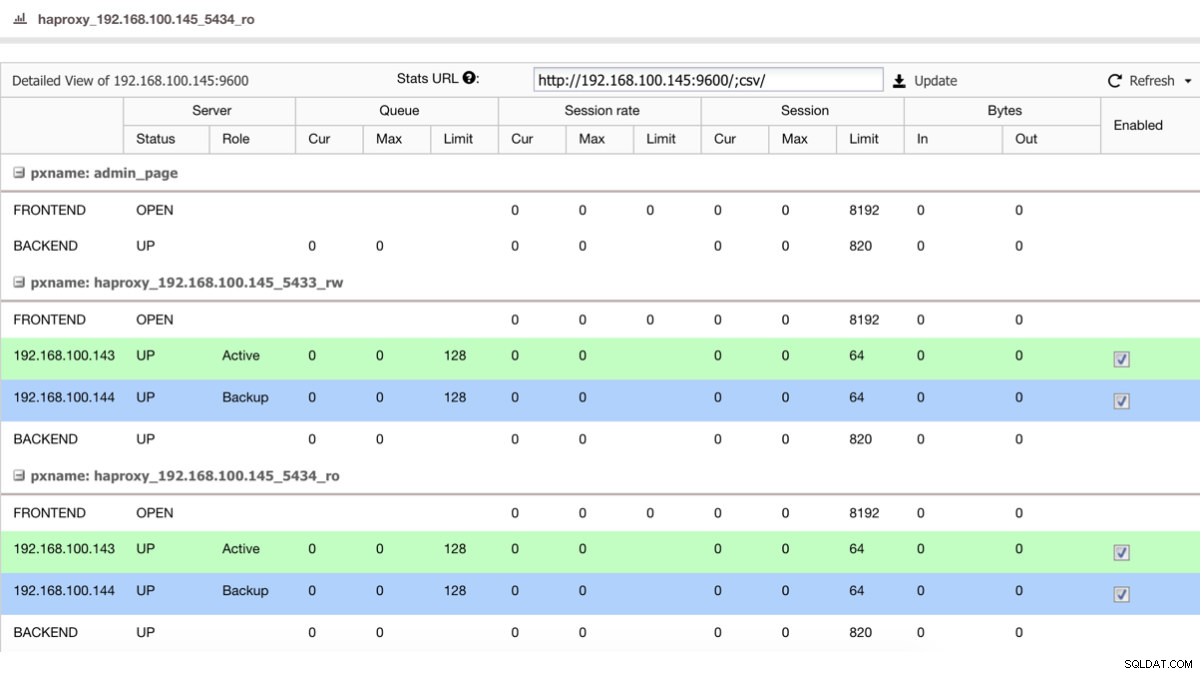 Vista de estado de HAProxy
Vista de estado de HAProxy Entonces, si simplemente apaga el maestro en PostgreSQL 10, el servidor de respaldo, en este caso en PostgreSQL 11, comienza a recibir el tráfico de manera transparente para el usuario/aplicación.
Al final de la migración, podemos eliminar la suscripción en nuestro nuevo maestro en PostgreSQL 11:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONY verifica que se elimine correctamente:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Limitaciones
Antes de utilizar la replicación lógica, tenga en cuenta las siguientes limitaciones:
- El esquema de la base de datos y los comandos DDL no se replican. El esquema inicial se puede copiar usando pg_dump --schema-only.
- Los datos de la secuencia no se replican. Los datos en columnas seriales o de identidad respaldadas por secuencias se replicarán como parte de la tabla, pero la secuencia en sí seguirá mostrando el valor de inicio en el suscriptor.
- Se admite la replicación de los comandos TRUNCATE, pero se debe tener cuidado al truncar grupos de tablas conectadas por claves foráneas. Al replicar una acción de truncado, el suscriptor truncará el mismo grupo de tablas que se truncó en el publicador, ya sea especificado explícitamente o recopilado implícitamente a través de CASCADE, menos las tablas que no forman parte de la suscripción. Esto funcionará correctamente si todas las tablas afectadas forman parte de la misma suscripción. Pero si algunas tablas que se van a truncar en el suscriptor tienen enlaces de clave externa a tablas que no forman parte de la misma (o ninguna) suscripción, la aplicación de la acción de truncado en el suscriptor fallará.
- Los objetos grandes no se replican. No hay solución para eso, aparte de almacenar datos en tablas normales.
- La replicación solo es posible de tablas base a tablas base. Es decir, las tablas en la publicación y en el lado de la suscripción deben ser tablas normales, no vistas, vistas materializadas, tablas raíz de partición o tablas foráneas. En el caso de las particiones, puede replicar una jerarquía de partición uno a uno, pero actualmente no puede replicar a una configuración con particiones diferentes.
Conclusión
Mantener actualizado su servidor PostgreSQL realizando actualizaciones periódicas ha sido una tarea necesaria pero difícil hasta la versión 10 de PostgreSQL.
En este blog hicimos una breve introducción a la replicación lógica, una función de PostgreSQL introducida de forma nativa en la versión 10, y le mostramos cómo puede ayudarlo a lograr este desafío con una estrategia de tiempo de inactividad cero.