Cada versión de PostgreSQL viene con algunas mejoras importantes en las funciones, pero lo que es igualmente interesante es que cada versión también mejora sus funciones anteriores.
Dado que PostgreSQL 13 está programado para lanzarse pronto, es hora de comprobar qué características y mejoras nos trae la comunidad. Una de esas mejoras sin ruido es la "Mejora de replicación lógica para particiones".
Comprendamos esta mejora de funciones con un ejemplo en ejecución.
Terminología
Dos términos que son importantes para comprender esta función son:
- Tablas de partición
- Replicación lógica
Tablas de partición
Una forma de dividir una mesa grande en múltiples piezas físicas para lograr beneficios como:
- Rendimiento de consultas mejorado
- Actualizaciones más rápidas
- Cargas y eliminaciones masivas más rápidas
- Organización de datos poco utilizados en unidades de disco lentas
Algunas de estas ventajas se logran mediante la eliminación de particiones (es decir, el planificador de consultas que usa la definición de partición para decidir si escanear una partición o no) y el hecho de que una partición es bastante más fácil de colocar en una memoria finita en comparación con una mesa enorme.
Una tabla se particiona sobre la base de:
- Lista
- Hash
- Rango

Replicación lógica
Como su nombre lo indica, este es un método de replicación en el que los datos se replican de forma incremental en función de su identidad (por ejemplo, clave). No es similar a los métodos de replicación física o WAL donde los datos se envían byte a byte.
Según un patrón de publicador-suscriptor, la fuente de los datos debe definir un publicador, mientras que el objetivo debe registrarse como suscriptor. Los casos de uso interesantes para esto son:
- Replicación selectiva (solo una parte de la base de datos)
- Escrituras simultáneas en dos instancias de la base de datos donde se replican los datos
- Replicación entre diferentes sistemas operativos (por ejemplo, Linux y Windows)
- Seguridad detallada en la replicación de datos
- Activa la ejecución cuando los datos llegan al lado del receptor
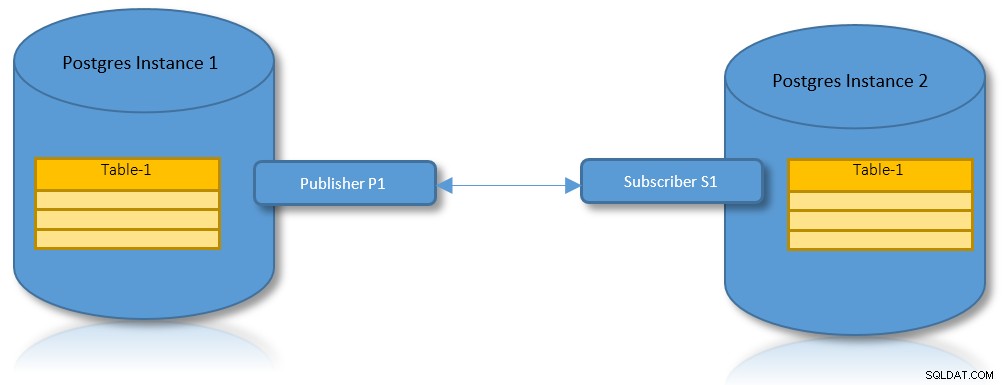
Replicación lógica para particiones
Con los beneficios de la replicación lógica y el particionamiento, es un caso de uso práctico tener un escenario en el que una tabla particionada debe replicarse en dos instancias de PostgreSQL.
Los siguientes son los pasos para establecer y resaltar la mejora que se está realizando en PostgreSQL 13 en este contexto.
Configuración
Considere una configuración de dos nodos para ejecutar dos instancias diferentes que contengan una tabla particionada:
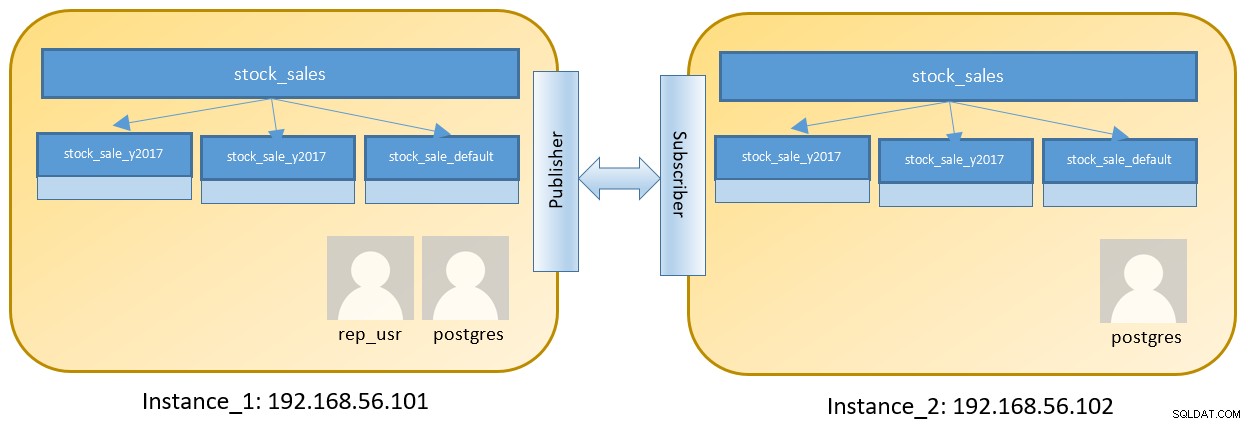
Los pasos en Instance_1 son los siguientes después de iniciar sesión en 192.168.56.101 como usuario de postgres :
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile startLa configuración de 'wal_level' se establece específicamente en 'lógico' para indicar que se usará la replicación lógica para replicar los datos de esta instancia. El archivo de configuración 'pg_hba.conf' también se ha modificado para permitir conexiones desde 192.168.56.102.
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;Aunque el rol de postgres se crea de forma predeterminada en la base de datos Instance_1, también se debe crear un usuario independiente que tenga acceso limitado, lo que restringe el alcance solo para una tabla determinada.
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;Se requiere una configuración casi similar en Instance_2
$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startDebe tenerse en cuenta que dado que Instance_2 no será una fuente de datos para ningún otro nodo, la configuración de wal_level y el archivo pg_hba.conf no necesitan ninguna configuración adicional. No hace falta decir que pg_hba.conf puede necesitar una actualización según las necesidades de producción.
La replicación lógica no es compatible con DDL, también debemos crear una estructura de tabla en Instance_2. Cree una tabla particionada usando la creación de partición anterior para crear la misma estructura de tabla en Instance_2 también.
Configuración de replicación lógica
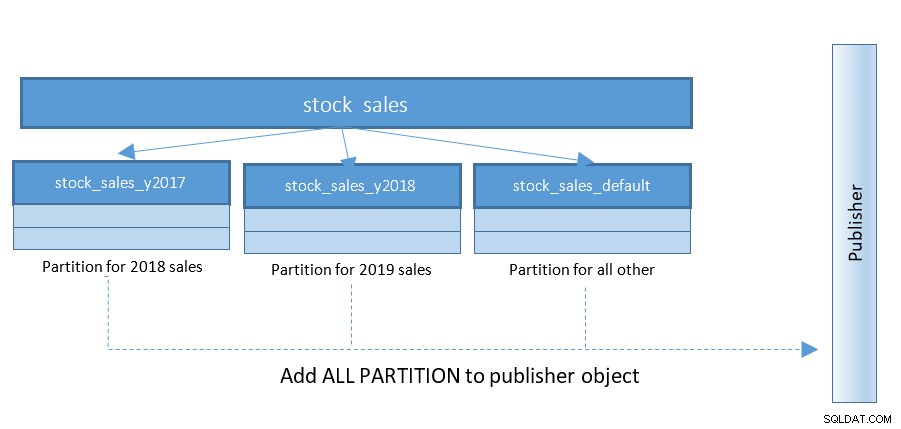
La configuración de la replicación lógica se vuelve mucho más fácil con PostgreSQL 13. Hasta PostgreSQL 12, la estructura era la siguiente:
Con PostgreSQL 13, la publicación de particiones se vuelve mucho más fácil. Consulte el siguiente diagrama y compárelo con el diagrama anterior:
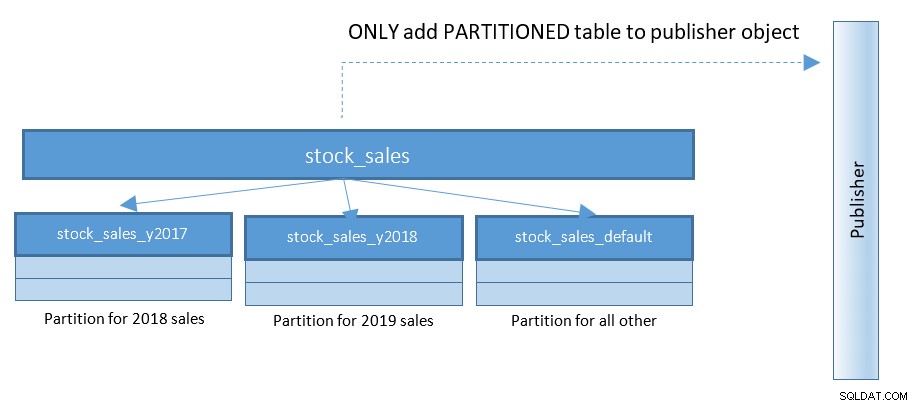
Con configuraciones con cientos y miles de tablas particionadas, este pequeño cambio simplifica cosas en gran medida.
En PostgreSQL 13, las instrucciones para crear dicha publicación serán:
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);El parámetro de configuración publishing_via_partition_root es nuevo en PostgreSQL 13, lo que permite que el nodo destinatario tenga una jerarquía de hoja ligeramente diferente. La mera creación de publicaciones en tablas particionadas en PostgreSQL 12 devolverá declaraciones de error como las siguientes:
ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.Ignorando las limitaciones de PostgreSQL 12 y procediendo con esta función en PostgreSQL 13, tenemos que establecer un suscriptor en Instance_2 con las siguientes declaraciones:
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;Comprobando si realmente funciona
Ya casi hemos terminado con toda la configuración, pero hagamos un par de pruebas para ver si todo funciona.
En Instancia_1, inserte varias filas asegurándose de que se generen en varias particiones:
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);Verifique los datos en Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721Ahora vamos a comprobar si la replicación lógica funciona incluso si los nodos hoja no son los mismos en el lado del destinatario.
Agregue otra partición en Instancia_1 e inserte el registro:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );Verifique los datos en Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174Otras funciones de partición en PostgreSQL 13
También hay otras mejoras en PostgreSQL 13 que están relacionadas con la partición, a saber:
- Mejoras en Unión entre tablas particionadas
- Las tablas particionadas ahora son compatibles con los activadores de nivel de fila ANTES
Conclusión
Definitivamente revisaré las dos próximas características antes mencionadas en mi próximo conjunto de blogs. Hasta entonces, materia de reflexión:con el poder combinado de la partición y la replicación lógica, ¿PostgreSQL navega más cerca de una configuración maestro-maestro?