Esta publicación de blog presentará un ejemplo simple tipo "hola mundo" sobre cómo obtener datos almacenados en S3 indexados y atendidos por un servicio Apache Solr alojado en un clúster de descubrimiento y exploración de datos en CDP. Para los curiosos:DDE es una opción de implementación de clústeres optimizada para Solr prediseñada en CDP y lanzada recientemente en tech preview . Solo cubriremos los entornos de AWS y S3 en este blog. Las opciones de implementación de Azure y ADLS también están disponibles en la vista previa técnica, pero se tratarán en una futura publicación de blog.
Describiremos el escenario más simple para que sea fácil comenzar. Por supuesto, existen configuraciones de canalización de datos más avanzadas y esquemas más ricos posibles, pero este es un buen punto de partida para un principiante.
Suposiciones:
- Ya tiene una cuenta de CDP y tiene derechos de administrador o usuario avanzado para el entorno en el que planea poner en marcha este servicio.
Si no tiene una cuenta de CDP AWS, comuníquese con su representante de Cloudera favorito o regístrese para una prueba de CDP aquí. - Tiene entornos e identidades asignadas y configuradas. Más explícitamente, todo lo que necesita es tener la asignación del usuario de CDP a un rol de AWS que otorga acceso al depósito s3 específico del que desea leer (y escribir).
- Ya tiene configurada una contraseña de carga de trabajo (FreeIPA).
- Tiene un clúster DDE ejecutándose. También puede encontrar más información sobre el uso de plantillas en CDP Data Hub aquí.
- Tiene acceso CLI a ese clúster.
- El puerto SSH está abierto en AWS en cuanto a su dirección IP. Puede obtener la dirección IP pública de uno de los nodos de Solr dentro de los detalles del clúster de Datahub. Aprenda aquí cómo SSH a un clúster de AWS.
- Tiene un archivo de registro en un depósito de S3 al que puede acceder su usuario (
/sample.log en este ejemplo). Si no tiene uno, aquí hay un enlace al que usamos.
Flujo de trabajo
Las siguientes secciones lo guiarán a través de los pasos para obtener datos indexados usando la herramienta Crunch Indexer Tool que viene de fábrica con DDE.

Cree una colección para mantener su índice
En HUE hay un diseñador de índices; sin embargo, mientras DDE esté en Tech Preview, estará algo en reconstrucción y no se recomienda en este momento. Pero inténtalo después de que DDE pase a GA y cuéntanos lo que piensas.
Por ahora, puede crear su esquema y configuraciones de Solr usando la herramienta CLI 'solrctl'. Cree una configuración llamada 'my-own-logs-config' y una colección llamada 'my-own-logs'. Esto requiere que tenga acceso CLI.
1. SSH a cualquiera de los nodos de trabajo en su clúster.
2. kinit como usuario con permiso para crear la configuración de la colección:
kinit
3. Asegúrese de que la variable de entorno SOLR_ZK_ENSEMBLE esté configurada en /etc/solr/conf/solr-env.sh. Guarde su valor, ya que será necesario en pasos posteriores.
Presiona Enter y escribe tu contraseña de carga de trabajo (FreeIPA).
Por ejemplo:
cat /etc/solr/conf/solr-env.sh
Salida esperada:
export SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Esto se configura automáticamente en hosts con un rol de Servidor Solr o Gateway en Cloudera Manager.
4. Para generar archivos de configuración para la colección, ejecute el siguiente comando:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate es una de las plantillas predeterminadas enviadas con Solr en CDP pero, al ser una plantilla, es inmutable. A los efectos de este flujo de trabajo, debe copiarlo y, por lo tanto, crear uno nuevo que sea mutable (esto es lo que hace la opción immutable=false). Esto le proporciona una configuración flexible y sin esquemas. Crear un esquema bien diseñado es algo en lo que vale la pena invertir tiempo de diseño, pero no es necesario para un uso exploratorio. Por esta razón, está más allá del alcance de esta publicación de blog. Sin embargo, en un entorno de producción real, recomendamos encarecidamente el uso de esquemas bien diseñados, ¡y estaremos encantados de proporcionar ayuda experta si es necesario!
5. Crea una nueva colección usando el siguiente comando:
solrctl collection --create my-own-logs -s 1 -c my-own-logs-config
Esto crea la colección "my-own-logs" basada en la configuración de la colección "my-own-logs-config" en un fragmento.
6. Para validar que se ha creado la colección, puede navegar a la interfaz de usuario de administración de Solr. La colección de "my-own-logs" estará disponible a través del menú desplegable en la barra de navegación de la izquierda.

Indexar sus datos
Aquí describimos mediante un ejemplo simple cómo configurar y ejecutar la herramienta Crunch Indexer integrada para indexar datos rápidamente en S3 y servir a través de Solr en DDE. Dado que la protección del clúster puede utilizar CM Auto TLS, Knox, Kerberos y Ranger, el "envío de Spark" puede depender de aspectos que no se cubren en esta publicación.
La indexación de datos de S3 es igual que la indexación de HDFS.
Realice estos pasos en el nodo trabajador de Yarn (denominado "Yarnworker" en la interfaz de usuario web de Management Console).
1. Utilice SSH para el nodo trabajador de Yarn dedicado del clúster DDE como usuario administrador de Solr.
Para averiguar la dirección IP del nodo trabajador de Yarn, haga clic en Hardware en la página de detalles del clúster, luego desplácese hasta el nodo "Yarnworker".

2. Vaya a su directorio de recursos (o cree uno si aún no lo tiene:
cd
Utilice la carpeta de inicio del usuario administrador como directorio de recursos (
3. Kinite su usuario:
kinit
Presiona Enter y escribe tu contraseña de carga de trabajo (FreeIPA).
4. Ejecute el siguiente comando curl, reemplazando
curl --negotiate -u: "https://<SOLR_HOST>:<SOLR_PORT>/solr/admin?op=GETDELEGATIONTOKEN" --insecure > tokenFile.txt
5. Cree un archivo de configuración de Morphline para la herramienta Crunch Indexer Tool, read-log-morphline.conf en este ejemplo. Reemplazar
SOLR_LOCATOR : {
# Name of solr collection
collection : my-own-logs
#zk ensemble
zkHost : <SOLR_ZK_ENSEMBLE>
}
morphlines : [
{
id : loadLogs
importCommands : ["org.kitesdk.**", "org.apache.solr.**"]
commands : [
{
readMultiLine {
regex : "(^.+Exception: .+)|(^\\s+at .+)|(^\\s+\\.\\.\\. \\d+ more)|(^\\s*Caused by:.+)"
what : previous
charset : UTF-8
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
{
loadSolr {
solrLocator : ${SOLR_LOCATOR}
}
}
]
}
] Esta Morphline lee los seguimientos de la pila del archivo de registro dado, luego escribe un registro de entrada de depuración y lo carga en el Solr especificado.
6. Cree un archivo log4j.properties para la configuración del registro:
log4j.rootLogger=INFO, A1 # A1 is set to be a ConsoleAppender. log4j.appender.A1=org.apache.log4j.ConsoleAppender # A1 uses PatternLayout. log4j.appender.A1.layout=org.apache.log4j.PatternLayout log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Verifique si el archivo que desea leer existe en S3 (si no tiene uno, aquí hay un enlace al que usamos para este ejemplo simple:
aws s3 ls s3://<S3_BUCKET>/sample.log
8. Ejecute el comando spark-submit:
Reemplace los marcadores de posición en
export myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunch export myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunch export myDriverJar=$(find $myDriverJarDir -maxdepth 1 -name 'search-crunch-*.jar' ! -name '*-job.jar' ! -name '*-sources.jar') export myDependencyJarFiles=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ',' | head -c -1) export myDependencyJarPaths=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ':' | head -c -1) export myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ " export myResourcesDir="<RESOURCE_DIR>" export HADOOP_CONF_DIR="/etc/hadoop/conf" spark-submit \ --master yarn \ --deploy-mode cluster \ --jars $myDependencyJarFiles \ --executor-memory 1024M \ --conf "spark.executor.extraJavaOptions=$myJVMOptions" \ --driver-java-options "$myJVMOptions" \ --class org.apache.solr.crunch.CrunchIndexerTool \ --files $(ls $myResourcesDir/log4j.properties),$(ls $myResourcesDir/read-log-morphline.conf),tokenFile.txt \ $myDriverJar \ -Dhadoop.tmp.dir=/tmp \ -DtokenFile=tokenFile.txt \ --morphline-file read-log-morphline.conf \ --morphline-id loadLogs \ --pipeline-type spark \ --chatty \ --log4j log4j.properties \ s3a://<S3_BUCKET>/sample.log
Si encuentra un mensaje similar, puede ignorarlo:
WARN metadata.Hive: Failed to register all functions. org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.transport.TTransportException
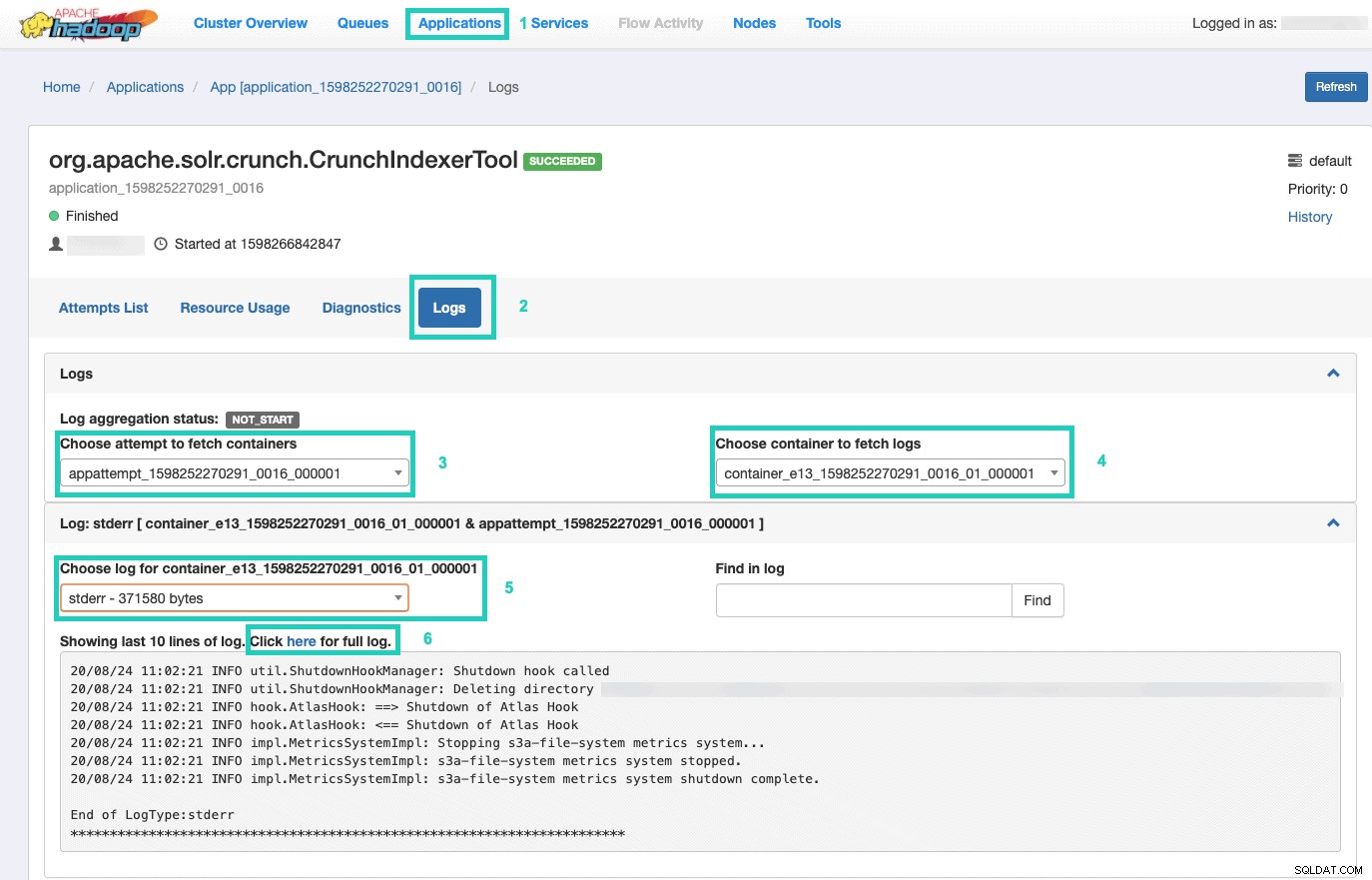
9. Para monitorear la ejecución del comando, vaya al Administrador de recursos.

Una vez allí, seleccione las Aplicaciones pestaña > Haga clic en el ID de la aplicación. del intento de aplicación que desea monitorear > Seleccione Registros> Elija intento de obtener contenedores> Elija contenedor para obtener registros> Elija registro para contenedor> Seleccione el stderr registro> Haga clic en Haga clic aquí para ver el registro completo .
Servir su Índice
Tiene muchas opciones sobre cómo servir los datos indexados que se pueden buscar a los usuarios finales. Puede crear su propia aplicación enriquecida basada en las API enriquecidas de Solr (muy común). Puede conectar su herramienta de terceros favorita, como Qlik, Tableau, etc. a través de sus conexiones Solr certificadas. Puede utilizar el sencillo panel de control de solr de Hue para crear prototipos de aplicaciones.
Para hacer esto último:
1. Ve a Tono.

2. En la vista del tablero, navegue hasta el archivo de índice de su elección (por ejemplo, el que acaba de crear).
3. Comience a arrastrar y soltar varios elementos del tablero y seleccione los campos del índice para completar los datos del objeto visual en cuestión.
Puede encontrar un video tutorial del panel de control rápido del pasado aquí, para inspirarse.
Dejaremos una inmersión más profunda para una futura publicación de blog.
Resumen
Esperamos que haya aprendido mucho de esta publicación de blog sobre cómo obtener datos en S3 indexados por Solr en un DDE utilizando la herramienta Crunch Indexer. Por supuesto, hay muchas otras formas (Spark en la experiencia de ingeniería de datos, Nifi en la experiencia de flujo de datos, Kafka en la experiencia de gestión de transmisiones, etc.), pero se tratarán en futuras publicaciones de blog. Esperamos que tenga mucho éxito en su viaje continuo en la creación de poderosas aplicaciones de información que involucren texto y otros datos no estructurados. Si decide probar DDE en CDP, ¡cuéntenos cómo le fue!



