Como administradores de sistemas y desarrolladores, pasamos mucho tiempo en una terminal. Así que trajimos ClusterControl a la terminal con nuestra herramienta de interfaz de línea de comandos llamada s9s. s9s proporciona una interfaz sencilla para la API de ClusterControl RPC v2. Lo encontrará muy útil cuando trabaje con implementaciones a gran escala, ya que la CLI le permitirá diseñar funciones y flujos de trabajo más complejos.
Esta publicación de blog muestra cómo usar s9s para automatizar la administración de Galera Cluster para MySQL o MariaDB, así como una configuración simple de replicación maestro-esclavo.
Configuración
Puede encontrar instrucciones de instalación para su sistema operativo particular en la documentación. Lo que es importante tener en cuenta es que si usa las últimas herramientas s9s, de GitHub, hay un ligero cambio en la forma en que crea un usuario. El siguiente comando funcionará bien:
s9s user --create --generate-key --controller="https://localhost:9501" dbaEn general, se requieren dos pasos si desea configurar CLI localmente en el host de ClusterControl. Primero, debe crear un usuario y luego realizar algunos cambios en el archivo de configuración; todos los pasos se incluyen en la documentación.
Despliegue
Una vez que la CLI se haya configurado correctamente y tenga acceso SSH a los hosts de la base de datos de destino, puede iniciar el proceso de implementación. Al momento de escribir, puede usar la CLI para implementar clústeres de MySQL, MariaDB y PostgreSQL. Comencemos con un ejemplo de cómo implementar Percona XtraDB Cluster 5.7. Se requiere un solo comando para hacer eso.
s9s cluster --create --cluster-type=galera --nodes="10.0.0.226;10.0.0.227;10.0.0.228" --vendor=percona --provider-version=5.7 --db-admin-passwd="pass" --os-user=root --cluster-name="PXC_Cluster_57" --waitLa última opción "--wait" significa que el comando esperará hasta que se complete el trabajo, mostrando su progreso. Puede omitirlo si lo desea; en ese caso, el comando s9s regresará inmediatamente al shell después de registrar un nuevo trabajo en cmon. Esto está perfectamente bien ya que común es el proceso que maneja el trabajo en sí. Siempre puede verificar el progreso de un trabajo por separado, usando:
example@sqldat.com:~# s9s job --list -l
--------------------------------------------------------------------------------------
Create Galera Cluster
Installing MySQL on 10.0.0.226 [██▊ ]
26.09%
Created : 2017-10-05 11:23:00 ID : 1 Status : RUNNING
Started : 2017-10-05 11:23:02 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 1Echemos un vistazo a otro ejemplo. Esta vez crearemos un nuevo clúster, replicación MySQL:maestro simple - par esclavo. Nuevamente, un solo comando es suficiente:
example@sqldat.com:~# s9s cluster --create --nodes="10.0.0.229?master;10.0.0.230?slave" --vendor=percona --cluster-type=mysqlreplication --provider-version=5.7 --os-user=root --wait
Create MySQL Replication Cluster
/ Job 6 FINISHED [██████████] 100% Cluster createdAhora podemos verificar que ambos clústeres estén en funcionamiento:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Por supuesto, todo esto también es visible a través de la GUI:
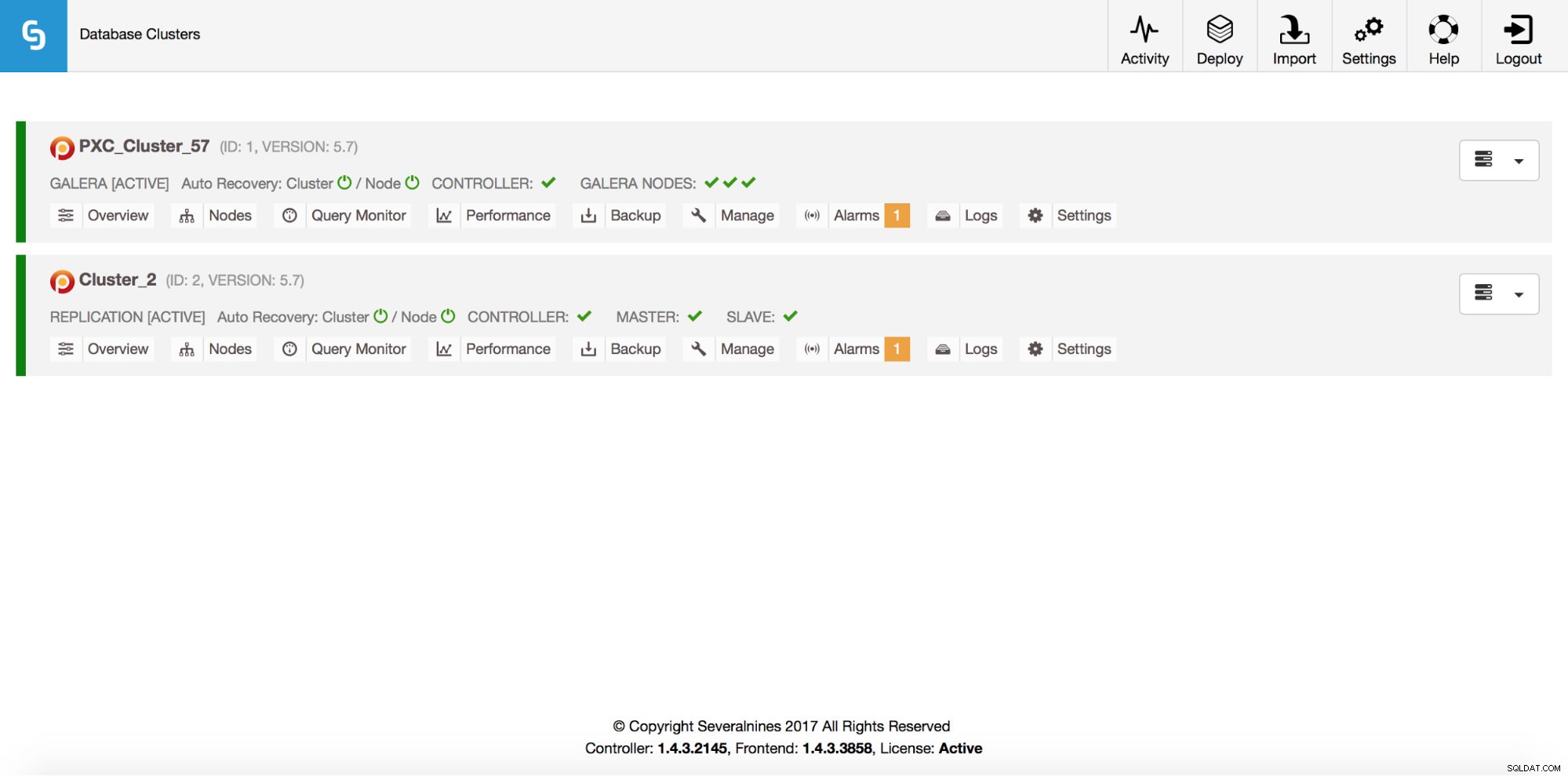
Ahora, agreguemos un balanceador de carga ProxySQL:
example@sqldat.com:~# s9s cluster --add-node --nodes="proxysql://10.0.0.226" --cluster-id=1
WARNING: admin/admin
WARNING: proxy-monitor/proxy-monitor
Job with ID 7 registered.Esta vez no usamos la opción '--wait', por lo que, si queremos verificar el progreso, tenemos que hacerlo por nuestra cuenta. Tenga en cuenta que estamos utilizando una ID de trabajo que devolvió el comando anterior, por lo que obtendremos información sobre este trabajo en particular únicamente:
example@sqldat.com:~# s9s job --list --long --job-id=7
--------------------------------------------------------------------------------------
Add ProxySQL to Cluster
Waiting for ProxySQL [██████▋ ]
65.00%
Created : 2017-10-06 14:09:11 ID : 7 Status : RUNNING
Started : 2017-10-06 14:09:12 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 7Escalamiento horizontal
Los nodos se pueden agregar a nuestro clúster de Galera a través de un solo comando:
s9s cluster --add-node --nodes 10.0.0.229 --cluster-id 1
Job with ID 8 registered.
example@sqldat.com:~# s9s job --list --job-id=8
ID CID STATE OWNER GROUP CREATED RDY TITLE
8 1 FAILED dba users 14:15:52 0% Add Node to Cluster
Total: 8Algo salió mal. Podemos verificar qué sucedió exactamente:
example@sqldat.com:~# s9s job --log --job-id=8
addNode: Verifying job parameters.
10.0.0.229:3306: Adding host to cluster.
10.0.0.229:3306: Testing SSH to host.
10.0.0.229:3306: Installing node.
10.0.0.229:3306: Setup new node (installSoftware = true).
10.0.0.229:3306: Detected a running mysqld server. It must be uninstalled first, or you can also add it to ClusterControl.Correcto, esa IP ya se usa para nuestro servidor de replicación. Deberíamos haber usado otra IP gratuita. Probemos eso:
example@sqldat.com:~# s9s cluster --add-node --nodes 10.0.0.231 --cluster-id 1
Job with ID 9 registered.
example@sqldat.com:~# s9s job --list --job-id=9
ID CID STATE OWNER GROUP CREATED RDY TITLE
9 1 FINISHED dba users 14:20:08 100% Add Node to Cluster
Total: 9Gestión
Digamos que queremos hacer una copia de seguridad de nuestro maestro de replicación. Podemos hacerlo desde la GUI, pero a veces es posible que necesitemos integrarlo con scripts externos. ClusterControl CLI encajaría perfectamente en tal caso. Veamos qué clústeres tenemos:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Luego, verifiquemos los hosts en nuestro clúster de replicación, con ID de clúster 2:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
coC- 1.4.3.2145 2 cluster_2 10.0.2.15 9500 Up and runningComo podemos ver, hay tres hosts que conoce ClusterControl:dos de ellos son hosts MySQL (10.0.0.229 y 10.0.0.230), el tercero es la propia instancia de ClusterControl. Imprimamos solo los hosts MySQL relevantes:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2 10.0.0.2*
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
Total: 3En la columna "STAT" puedes ver algunos caracteres allí. Para obtener más información, sugerimos consultar la página del manual de s9s-nodes (man s9s-nodes). Aquí solo resumiremos las partes más importantes. El primer carácter nos informa sobre el tipo de nodo:"s" significa que es un nodo MySQL normal, "c" - controlador ClusterControl. El segundo carácter describe el estado del nodo:"o" nos dice que está en línea. Tercer personaje - papel del nodo. Aquí, "M" describe un maestro y "S", un esclavo, mientras que "C" significa controlador. El cuarto carácter final nos dice si el nodo está en modo de mantenimiento. “-” significa que no hay mantenimiento programado. De lo contrario, veríamos "M" aquí. Entonces, a partir de estos datos, podemos ver que nuestro maestro es un host con IP:10.0.0.229. Hagamos una copia de seguridad y almacenémosla en el controlador.
example@sqldat.com:~# s9s backup --create --nodes=10.0.0.229 --cluster-id=2 --backup-method=xtrabackupfull --wait
Create Backup
| Job 12 FINISHED [██████████] 100% Command okEntonces podemos verificar si realmente se completó bien. Tenga en cuenta la opción "--backup-format" que le permite definir qué información debe imprimirse:
example@sqldat.com:~# s9s backup --list --full --backup-format="Started: %B Completed: %E Method: %M Stored on: %S Size: %s %F\n" --cluster-id=2
Started: 15:29:11 Completed: 15:29:19 Method: xtrabackupfull Stored on: 10.0.0.229 Size: 543382 backup-full-2017-10-06_152911.xbstream.gz
Total 1Monitoreo
Todas las bases de datos tienen que ser monitoreadas. ClusterControl utiliza asesores para observar algunas de las métricas tanto en MySQL como en el sistema operativo. Cuando se cumple una condición, se envía una notificación. ClusterControl proporciona también un amplio conjunto de gráficos, tanto en tiempo real como históricos para la planificación post-mortem o de capacidad. A veces, sería genial tener acceso a algunas de esas métricas sin tener que pasar por la GUI. ClusterControl CLI lo hace posible a través del comando s9s-node. Puede encontrar información sobre cómo hacerlo en la página del manual de s9s-node. Le mostraremos algunos ejemplos de lo que puede hacer con CLI.
En primer lugar, echemos un vistazo a la opción "--node-format" del comando "s9s node". Como puede ver, hay muchas opciones para imprimir contenido interesante.
example@sqldat.com:~# s9s node --list --node-format "%N %T %R %c cores %u%% CPU utilization %fmG of free memory, %tMB/s of net TX+RX, %M\n" "10.0.0.2*"
10.0.0.226 galera none 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Up and running
10.0.0.227 galera none 1 cores 13.033900% CPU utilization 0.543209G of free memory, 0.053596MB/s of net TX+RX, Up and running
10.0.0.228 galera none 1 cores 12.929100% CPU utilization 0.541988G of free memory, 0.052066MB/s of net TX+RX, Up and running
10.0.0.226 proxysql 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Process 'proxysql' is running.
10.0.0.231 galera none 1 cores 13.104700% CPU utilization 0.544048G of free memory, 0.045713MB/s of net TX+RX, Up and running
10.0.0.229 mysql master 1 cores 11.107300% CPU utilization 0.575871G of free memory, 0.035830MB/s of net TX+RX, Up and running
10.0.0.230 mysql slave 1 cores 9.861590% CPU utilization 0.580315G of free memory, 0.035451MB/s of net TX+RX, Up and runningCon lo que mostramos aquí, probablemente puedas imaginar algunos casos de automatización. Por ejemplo, puede observar la utilización de la CPU de los nodos y, si alcanza algún umbral, puede ejecutar otro trabajo s9s para activar un nuevo nodo en el clúster de Galera. También puede, por ejemplo, monitorear la utilización de la memoria y enviar alertas si supera algún umbral.
La CLI puede hacer más que eso. En primer lugar, es posible comprobar los gráficos desde la línea de comandos. Por supuesto, no son tan ricas en funciones como los gráficos en la GUI, pero a veces es suficiente ver un gráfico para encontrar un patrón inesperado y decidir si vale la pena investigarlo más a fondo.
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=load 10.0.0.231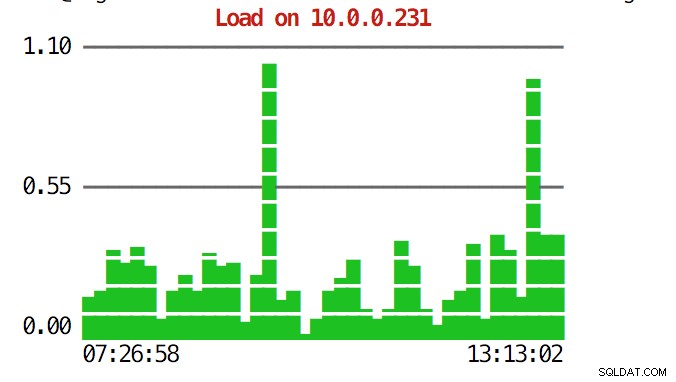
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=sqlqueries 10.0.0.231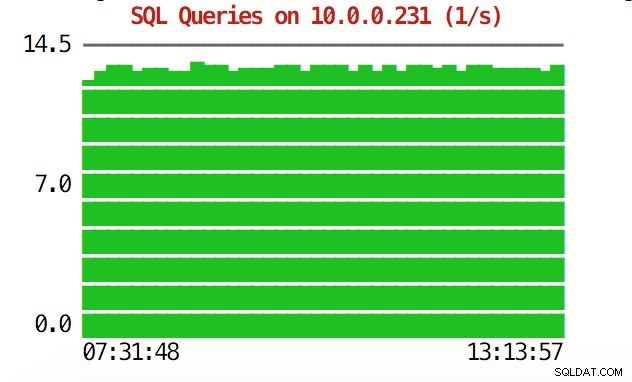
Durante situaciones de emergencia, es posible que desee verificar la utilización de recursos en todo el clúster. Puede crear una salida superior que combine datos de todos los nodos del clúster:
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqld
22994 root 10.0.2.15 20 30400 9312 S 0.93 1.23 s9s
9115 root 10.0.0.227 20 95368 7192 S 0.68 0.95 sshd
23768 root 10.0.0.228 20 95372 7160 S 0.67 0.94 sshd
15690 mysql 10.0.2.15 20 1102012 209056 S 0.67 27.58 mysqld
11471 root 10.0.0.226 20 95372 7392 S 0.17 0.98 sshd
22086 vagrant 10.0.2.15 20 95372 4960 S 0.17 0.65 sshd
7282 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:2
9003 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:1
1195 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:0
27240 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/1:1
9933 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:2
16181 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/u4:1
1744 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/1:1
28506 root 10.0.0.228 20 95372 7348 S 0.08 0.97 sshd
691 messagebus 10.0.0.228 20 42896 3872 S 0.08 0.51 dbus-daemon
11892 root 10.0.2.15 20 0 0 S 0.08 0.00 kworker/0:2
15609 root 10.0.2.15 20 403548 12908 S 0.08 1.70 apache2
256 root 10.0.2.15 20 0 0 S 0.08 0.00 jbd2/dm-0-8
840 root 10.0.2.15 20 316200 1308 S 0.08 0.17 VBoxService
14694 root 10.0.0.227 20 95368 7200 S 0.00 0.95 sshd
12724 n/a 10.0.0.227 20 4508 1780 S 0.00 0.23 mysqld_safe
10974 root 10.0.0.227 20 95368 7400 S 0.00 0.98 sshd
14712 root 10.0.0.227 20 95368 7384 S 0.00 0.97 sshd
16952 root 10.0.0.227 20 95368 7344 S 0.00 0.97 sshd
17025 root 10.0.0.227 20 95368 7100 S 0.00 0.94 sshd
27075 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/u4:1
27169 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/0:0
881 root 10.0.0.227 20 37976 760 S 0.00 0.10 rpc.mountd
100 root 10.0.0.227 0 0 0 S 0.00 0.00 deferwq
102 root 10.0.0.227 0 0 0 S 0.00 0.00 bioset
11876 root 10.0.0.227 20 9588 2572 S 0.00 0.34 bash
11852 root 10.0.0.227 20 95368 7352 S 0.00 0.97 sshd
104 root 10.0.0.227 0 0 0 S 0.00 0.00 kworker/1:1HCuando eche un vistazo a la parte superior, verá estadísticas de CPU y memoria agregadas en todo el clúster.
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,A continuación puede encontrar la lista de procesos de todos los nodos del clúster.
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqldEsto puede ser extremadamente útil si necesita averiguar qué está causando la carga y qué nodo es el más afectado.
Con suerte, la herramienta CLI le facilitará la integración de ClusterControl con scripts externos y herramientas de orquestación de infraestructura. Esperamos que disfrute usando esta herramienta y si tiene algún comentario sobre cómo mejorarla, no dude en hacérnoslo saber.



