En este artículo, voy a explicar cómo mover una tabla del grupo de archivos principal al grupo de archivos secundario. Primero, comprendamos qué son los archivos de datos, los grupos de archivos y los tipos de grupos de archivos.
Archivos de base de datos y grupos de archivos
Cuando SQL Server está instalado en cualquier servidor, crea un archivo de datos principal y un archivo de registro para almacenar datos. El archivo de datos principal almacena datos y objetos de base de datos como tablas, índices, procedimientos almacenados, etc. Los archivos de registro almacenan la información necesaria para recuperar transacciones. Los archivos de datos se pueden agrupar en grupos de archivos.
SQL Server tiene tres tipos de archivos
- Archivo principal :se crea cuando se instala el servidor SQL y contiene la información y los metadatos de la base de datos. Los datos de usuario, los objetos se pueden almacenar en los archivos de datos primarios. El archivo principal tiene la extensión .mdf.
- Archivo secundario :Los archivos secundarios son definidos por el usuario. Almacenan datos de Usuario, Objetos creados por un usuario. Tienen la extensión .ndf.
- Archivo de registro de transacciones s:Los archivos T-Logs registran todas las transacciones realizadas para recuperar la base de datos. La extensión del archivo de registro en .ldf.
Como mencioné anteriormente, los archivos de datos se pueden agrupar en un grupo de archivos. Mientras se instala SQL Server, crea el grupo de archivos principal que tiene un archivo de datos principal. Los grupos de archivos secundarios están definidos por el usuario. Tienen archivos de datos secundarios. Cuando creamos una nueva base de datos, podemos crear archivos de datos y grupos de archivos secundarios. Agregar archivos de datos secundarios ayuda a mejorar el rendimiento. Se puede crear en diferentes unidades de disco o en particiones de disco separadas, lo que reduce la espera de E/S y la latencia de lectura y escritura.
Se recomienda mantener tablas e índices en grupos de archivos separados. Además, mantener tablas grandes en archivos separados mejora el rendimiento.
Hay tres tipos de grupos de archivos:
- Grupo de archivos de fila :El grupo de archivos de fila, también conocido como grupo de archivos principal, contiene un archivo de datos principal. El objeto SQL, los datos y las tablas del sistema se asignan al grupo de archivos principal.
- Grupo de archivos optimizado para memoria :el grupo de archivos optimizado para memoria contiene tablas y datos optimizados para memoria. Para habilitar OLTP en memoria, debemos crear un grupo de archivos optimizado para memoria.
- Transmisión de archivos :El grupo de archivos de flujo de archivos contiene datos de flujo de archivos como imágenes, documentos, archivos ejecutables, etc. El grupo de archivos principal no puede contener datos de flujo de archivos, necesitamos crear un grupo de archivos FileStream. Contiene los datos de FileStream.
Configuración de demostración
En esta demostración, creé "DemoDatabase" en la instancia de SQL Server 2017. En la base de datos se crearon las pestañas "Registros" y "Datos del paciente". La clave principal "PK_CIDX_Records_ID" se creó en la tabla "Registros" y el índice agrupado "CIDX_PatientData_ID" se creó en la tabla "PatientData". En esta demostración, moveré las tablas "Registros" y "Datos del paciente" del grupo de archivos principal al grupo de archivos secundario.
Para esto, necesitamos hacer lo siguiente:
- Cree un grupo de archivos secundario.
- Agregue archivos de datos al grupo de archivos secundario.
- Mueva la tabla al grupo de archivos secundario moviendo el índice agrupado con la restricción de clave principal.
- Mueva las tablas al grupo de archivos secundario moviendo el índice agrupado sin la clave principal.
Crear grupo de archivos secundario
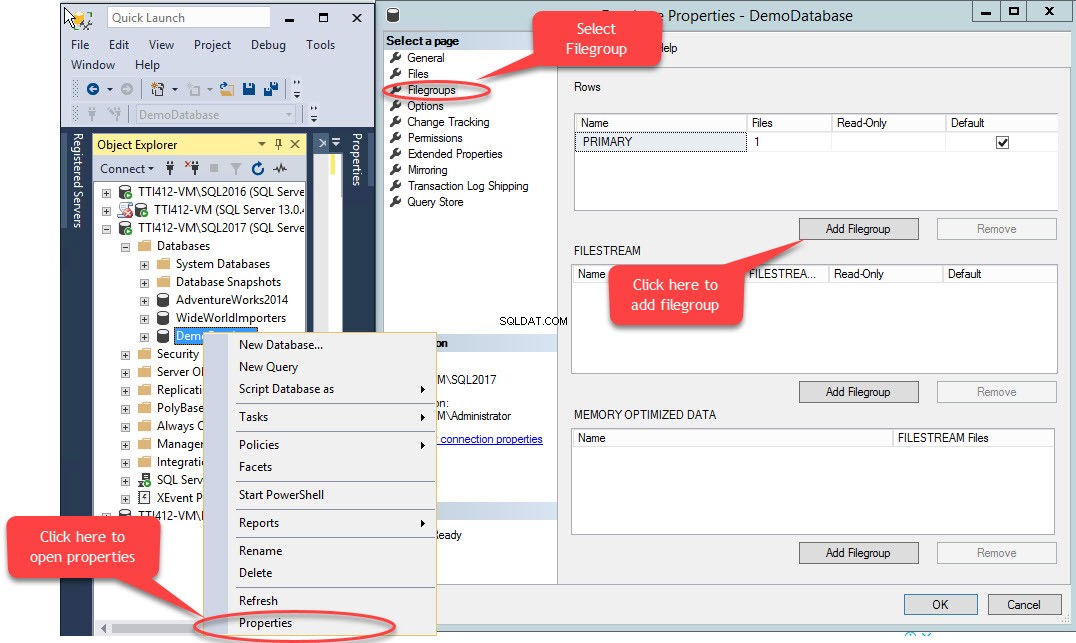
Se puede crear un grupo de archivos secundario usando T-SQL O usando el asistente para agregar archivos de SQL Server Management Studio. Para agregar un grupo de archivos mediante SSMS, abra SSMS y seleccione una base de datos donde se debe crear un grupo de archivos. Haga clic con el botón derecho en la base de datos y seleccione "Propiedades ”>> seleccione “Grupos de archivos ” y haga clic en “Agregar grupo de archivos ” como se muestra en la siguiente imagen:
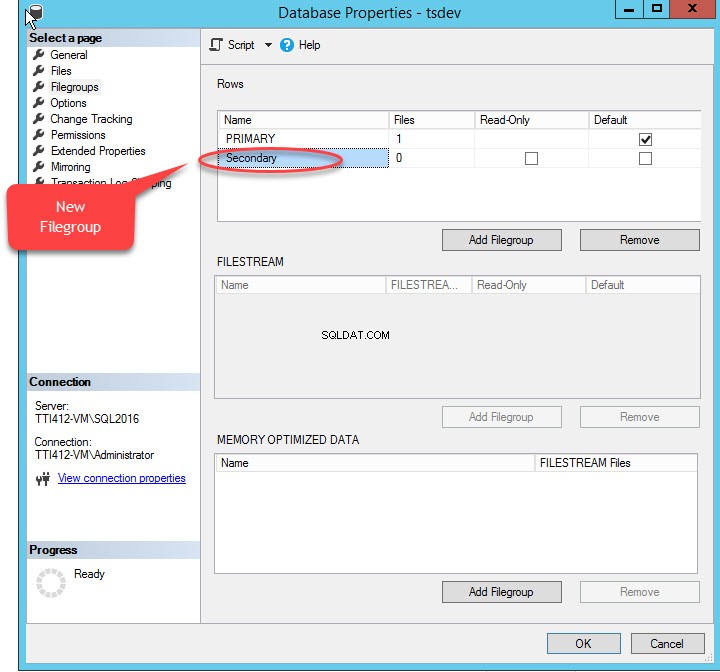
Cuando hacemos clic en “Agregar grupo de archivos ", se agregará una fila en "Filas " red. En las "Filas ”, proporcione el nombre del grupo de archivos apropiado en el campo “Nombre " columna. El grupo de archivos no es de solo lectura ni predeterminado; por lo tanto, mantenga el Solo lectura y Predeterminado casillas de verificación desactivadas para el nuevo grupo de archivos. Ver la siguiente imagen:
Haga clic en Aceptar para cerrar el cuadro de diálogo.
Para crear un grupo de archivos usando el script T-SQL, ejecute el siguiente script.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Adición de archivos al grupo de archivos
Para agregar archivos en un grupo de archivos, abra las propiedades de la base de datos, seleccione "archivos" y haga clic en "Agregar". Como se muestra en la siguiente imagen:
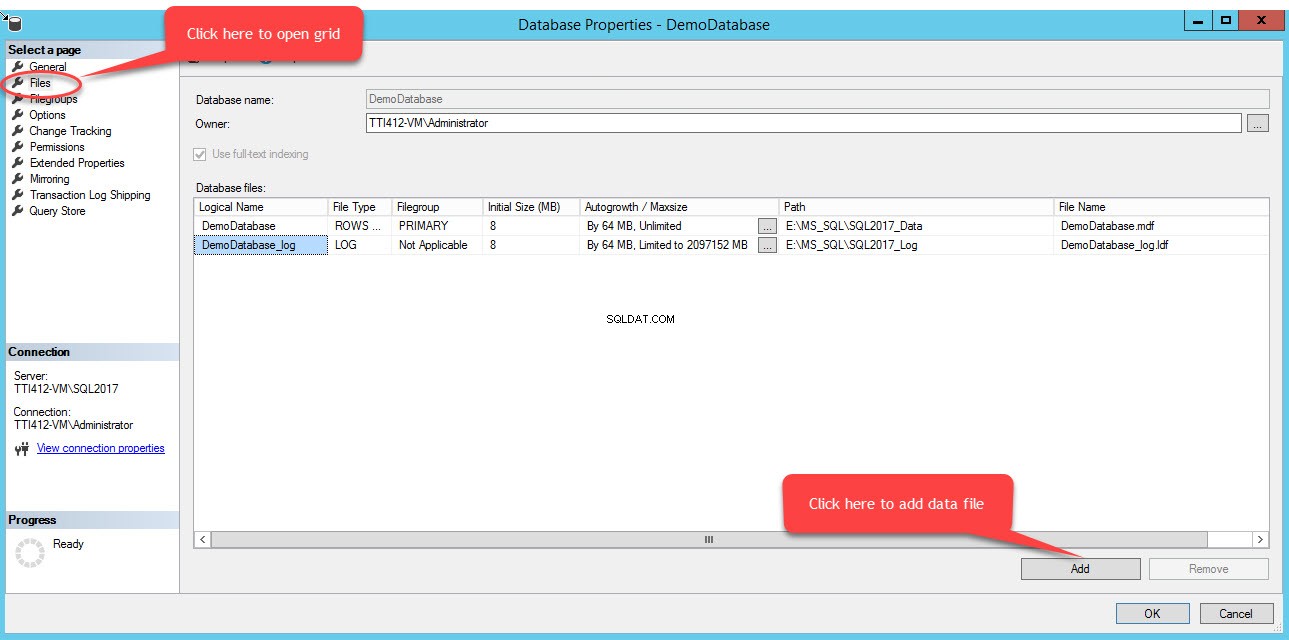
Se agregará una fila vacía en los Archivos de base de datos vista en cuadrícula. En la vista de cuadrícula, proporcione el nombre lógico adecuado en Nombre lógico columna, seleccione Datos de filas desde el tipo de archivo cuadro desplegable, seleccione secundario del grupo de archivos cuadro desplegable, establezca el tamaño inicial del archivo en Tamaño inicial columnas, establezca el parámetro de crecimiento automático y tamaño máximo en Autogrowth/Maxsize columna, proporcione la ubicación física del archivo de datos secundario en la Ruta columna y proporcione el nombre de archivo apropiado en Nombre de archivo columna. Ver la siguiente imagen:
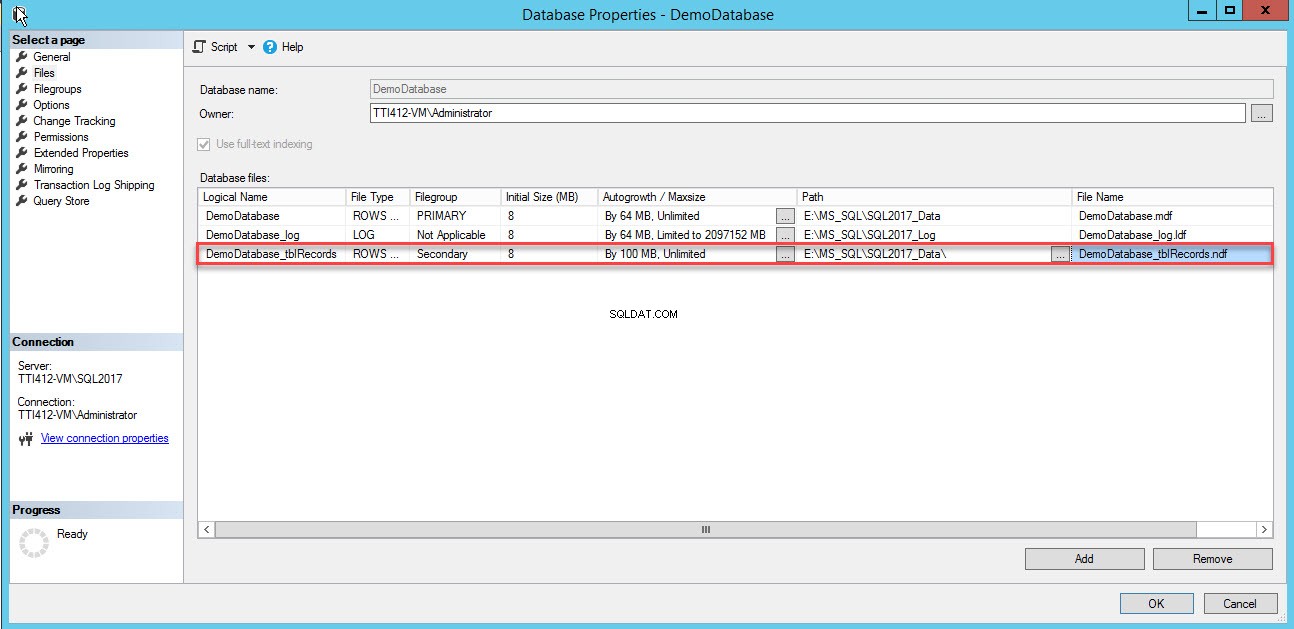
Utilice el siguiente script T-SQL para crear un archivo de datos secundario.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
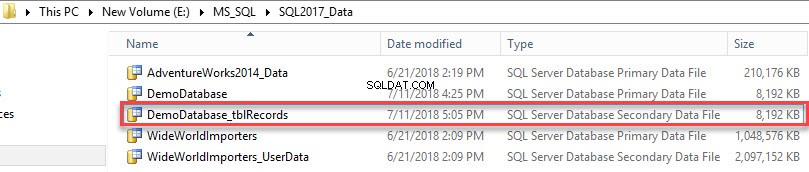
Se ha creado el archivo de datos secundario. Ver la siguiente imagen:
Para ver una lista de grupos de archivos creados en la base de datos, ejecute la siguiente consulta.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
A continuación se muestra un resultado de la consulta.

Transferir una tabla existente del grupo de archivos principal al grupo de archivos secundario
Podemos mover una tabla existente a otro grupo de archivos moviendo el índice agrupado a otro grupo de archivos. Como sabemos, un nodo hoja del índice agrupado tiene datos reales; por lo tanto, mover el índice agrupado puede mover toda la tabla a otro grupo de archivos. Mover el índice tiene una limitación:si el índice es una clave principal o una restricción única, no puede mover el índice mediante SQL Server Management Studio. Para mover esos índices, necesitamos usar el crear índice declaración y con DROP_Existing=ON opción.
Índice agrupado móvil con restricción de clave principal.
La clave principal impone valores únicos, por lo tanto, crea el índice agrupado único. La columna clave es PRN. Para crearlo en el grupo de archivos secundario, configure DROP_EXISTING=ON y el grupo de archivos debe ser secundario. Ejecute el siguiente script.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
Una vez que el comando se ejecutó correctamente, verifique que se haya creado el índice en el grupo de archivos secundario. Para ello, haga clic con el botón derecho en Almacenamiento opción en las Propiedades del índice caja de diálogo. Para abrir las propiedades del índice, expanda la DemoDatabase base de datos>> expandir Tablas>> expandir Índices . Haga clic derecho en PK_CIDX_Records_ID , como se muestra en la siguiente imagen:
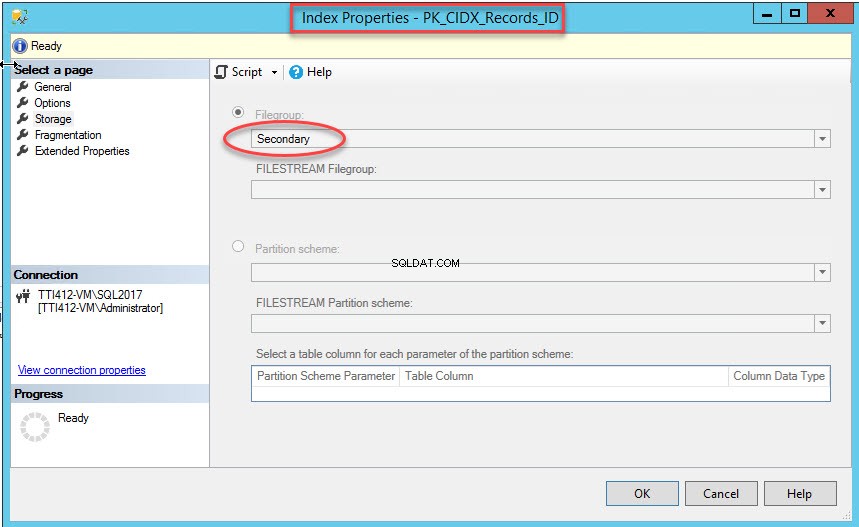
Como mencioné, una vez que el índice agrupado se mueve a un grupo de archivos secundario, la tabla se moverá al grupo de archivos secundario. Para verificarlo, haz clic con el botón derecho en Almacenamiento. opción en las Propiedades de la tabla caja de diálogo. Para abrir las propiedades del índice, expanda la DemoDatabase base de datos>> expandir Tabla s>> haga clic con el botón derecho en Registros, y seleccione almacenamiento, como se muestra en la siguiente imagen:
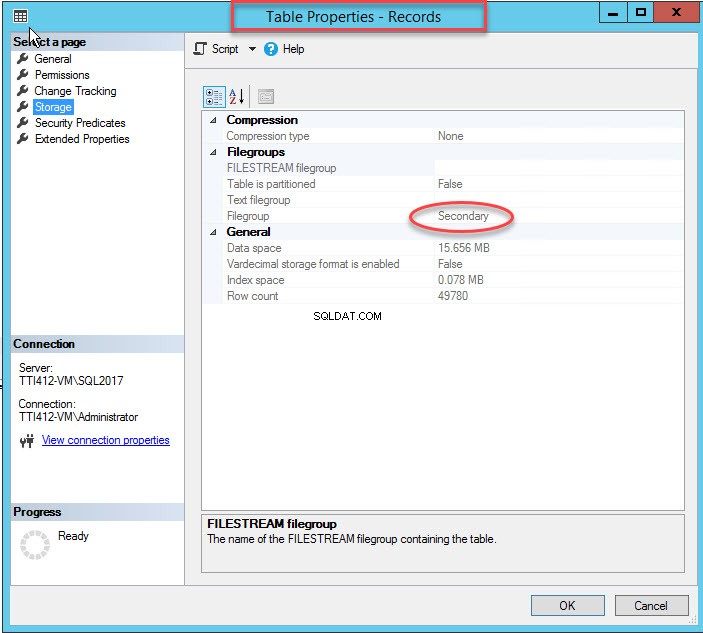
Mover índice agrupado sin clave principal
Podemos mover el índice agrupado sin clave principal usando SQL Server Management Studio. Para hacer eso, expanda la DemoDatabase base de datos>> expandir Tablas>> expandir Índice s>> haga clic con el botón derecho en CIDX_PatientData_ID indexe y seleccione Propiedades, como se muestra en la siguiente imagen:
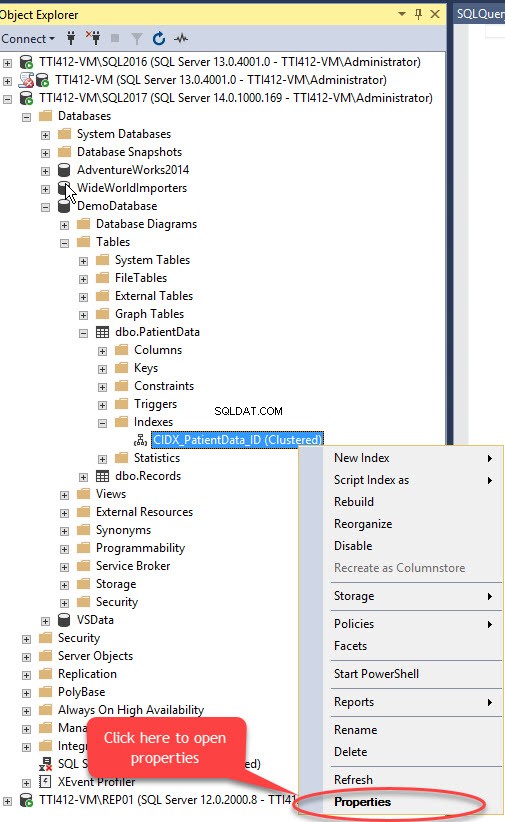
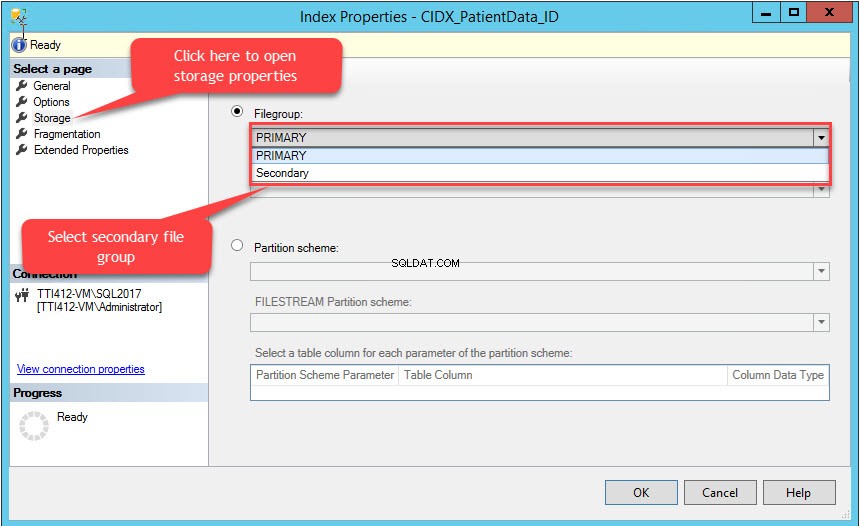
Las propiedades del índice se abre el cuadro de diálogo. En el cuadro de diálogo, seleccione Almacenamiento, y en la ventana Almacenamiento, haga clic en Grupo de archivos cuadro desplegable, seleccione Secundario grupo de archivos y haga clic en Aceptar, como se muestra en la siguiente imagen:
El cambio del grupo de archivos del índice volverá a crear el índice completo. Una vez que se vuelve a crear el índice, abra Propiedades de la tabla y seleccione un almacenamiento.
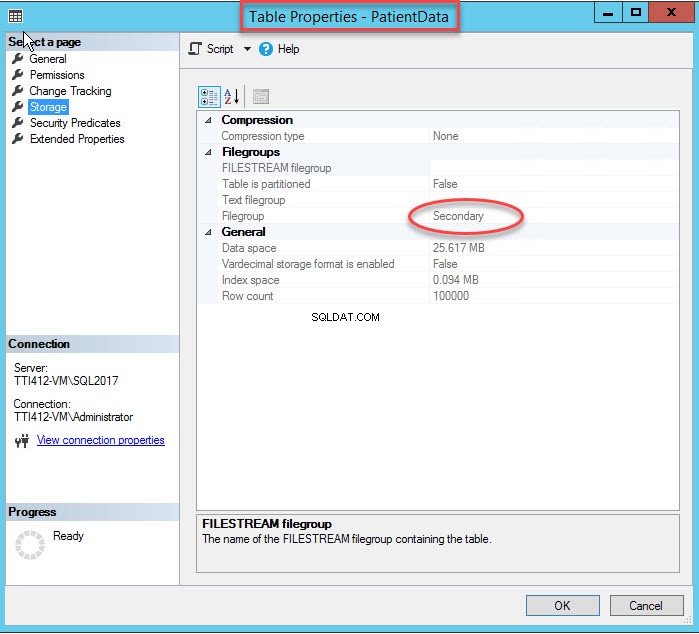
Como puede ver en la imagen de arriba, junto con mover el CIDX_PatientData_ID índice agrupado al grupo de archivos secundario, PatientData la tabla también se mueve al Secundario grupo de archivos.
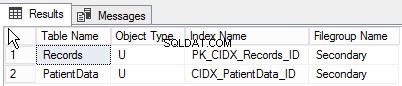
Al ejecutar la siguiente consulta, puede encontrar la lista de objetos creados en diferentes grupos de archivos:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go A continuación se muestra el resultado de la consulta:
Resumen
En este artículo, he explicado
-
- Conceptos básicos de archivos de datos y grupos de archivos.
- Cómo crear un grupo de archivos secundario y agregarle un archivo de datos secundario.
- Mueva la tabla al grupo de archivos secundario moviendo:
- Clave principal.
- Índice agrupado.