Introducción
Un carrete índice ansioso lee todas las filas de su operador secundario en una tabla de trabajo indexada, antes de comenzar a devolver filas a su operador principal. En algunos aspectos, un spool de índice ansioso es la mejor sugerencia de índice faltante , pero no se informa como tal.
Evaluación de costos
Insertar filas en una mesa de trabajo indexada es relativamente económico, pero no gratuito. El optimizador debe considerar que el trabajo implicado ahorra más de lo que cuesta. Para que eso funcione a favor del carrete, se debe estimar que el plan consume filas del carrete más de una vez. De lo contrario, también podría omitir el spool y solo hacer la operación subyacente esa vez.
- Para acceder más de una vez, el carrete debe aparecer en el lado interno de un operador de unión de bucles anidados.
- Cada iteración del ciclo debe buscar un valor de clave de carrete de índice particular proporcionado por el lado externo del ciclo.
Eso significa que la combinación debe ser aplicar , no una unión de bucles anidados . Para conocer la diferencia entre los dos, consulte mi artículo Aplicar versus Unión de bucles anidados.
Características notables
Mientras que un carrete de índice ansioso solo puede aparecer en el lado interno de un bucle anidado aplicar , no es un "carrete de rendimiento". Un spool de índice ansioso no se puede deshabilitar con el indicador de seguimiento 8690 o el NO_PERFORMANCE_SPOOL sugerencia de consulta.
Las filas insertadas en la cola de impresión del índice normalmente no se clasifican previamente en orden de clave de índice, lo que puede dar lugar a divisiones de páginas de índice. El indicador de rastreo no documentado 9260 se puede usar para generar una Ordenación operador antes de la bobina de índice para evitar esto. La desventaja es que el costo adicional de clasificación puede disuadir al optimizador de elegir la opción de cola.
SQL Server no admite inserciones paralelas en un índice de árbol b. Esto significa que todo lo que se encuentra debajo de un spool de índice ansioso paralelo se ejecuta en un solo subproceso. Los operadores debajo del carrete todavía están (engañosamente) marcados con el ícono de paralelismo. Se elige un hilo para escribir al carrete. Los otros subprocesos esperan en EXECSYNC mientras eso se completa. Una vez que se completa la cola, se puede leer de por hilos paralelos.
Los spools de índice no le dicen al optimizador que admiten la salida ordenada por las claves de índice del spool. Si se requiere una salida ordenada del spool, es posible que vea un Ordenar innecesario. operador. De todos modos, los carretes de índice ansiosos a menudo deben reemplazarse por un índice permanente, por lo que esta es una preocupación menor la mayor parte del tiempo.
Hay cinco reglas de optimización que pueden generar un Eager Index Spool opción (conocida internamente como un índice sobre la marcha ). Examinaremos tres de estos en detalle para comprender de dónde provienen los carretes de índice ansiosos.
SelToIndexOnTheFly
Este es el más común. Coincide con una o más selecciones relacionales (también conocidas como filtros o predicados) justo encima de un operador de acceso a datos. El SelToIndexOnTheFly regla reemplaza los predicados con un predicado de búsqueda en un spool de índice ansioso.
Demostración
Un AdventureWorks ejemplo de base de datos de muestra se muestra a continuación:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%';
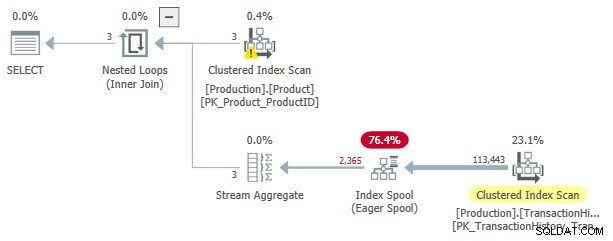
Este plan de ejecución tiene un coste estimado de 3,0881 unidades. Algunos puntos de interés:
- La unión interna de bucles anidados el operador es un aplicar , con
ProductIDySafetyStockLeveldelProducttabla como referencias externas . - En la primera iteración de la aplicación, el Eager Index Spool se completa completamente desde el Análisis de índice agrupado del
TransactionHistorymesa. - La mesa de trabajo de la cola tiene un índice agrupado con clave en
(ProductID, Quantity). - Filas que coinciden con los predicados
TH.ProductID = P.ProductIDyTH.Quantity < P.SafetyStockLevelson respondidas por el spool utilizando su índice. Esto es cierto para cada iteración de la aplicación, incluida la primera. - El
TransactionHistoryla tabla solo se escanea una vez.
Entrada ordenada a la cola
Es posible hacer cumplir la entrada ordenada en el spool de índice ansioso, pero esto afecta el costo estimado, como se indicó en la introducción. Para el ejemplo anterior, habilitar el indicador de seguimiento no documentado produce un plan sin un spool:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'A%'
OPTION (QUERYTRACEON 9260);
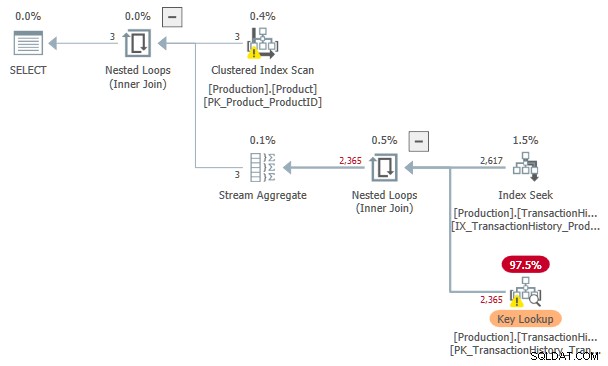
El costo estimado de esta búsqueda de índice y Búsqueda de claves el plan es 3.11631 unidades. Esto es más que el costo del plan con un spool de índice solo, pero menos que el plan con un spool de índice y entrada ordenada.
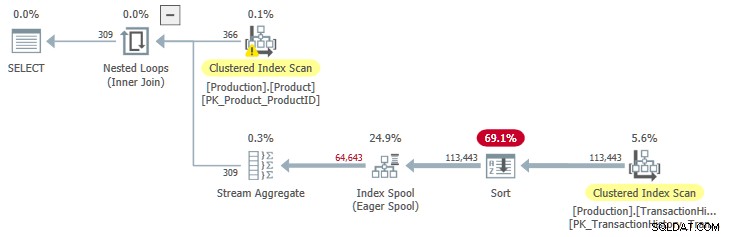
Para ver un plan con entrada ordenada en el spool, necesitamos aumentar el número esperado de iteraciones de bucle. Esto le da al carrete la oportunidad de pagar el costo adicional de la Clasificación . Una forma de expandir la cantidad de filas esperadas del Product tabla es hacer el Name predicado menos restrictivo:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
TH.Quantity
FROM Production.Product AS P
CROSS APPLY
(
SELECT
MAX(TH.Quantity)
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
GROUP BY ()
) AS TH (Quantity)
WHERE
P.[Name] LIKE N'[A-P]%'
OPTION (QUERYTRACEON 9260); Esto nos da un plan de ejecución con entrada ordenada al spool:
JoinToIndexOnTheFly
Esta regla transforma una unión interna a una aplicar , con un carrete de índice ansioso en el lado interior. Al menos uno de los predicados de unión debe ser una desigualdad para que esta regla coincida.
Esta es una regla mucho más especializada que SelToIndexOnTheFly , pero la idea es muy parecida. En este caso, la selección (predicado) que se transforma en una búsqueda de spool de índice se asocia con la combinación. La transformación de unir a aplicar permite que el predicado de combinación se mueva desde la combinación misma al lado interior de la aplicación.
Demostración
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN);
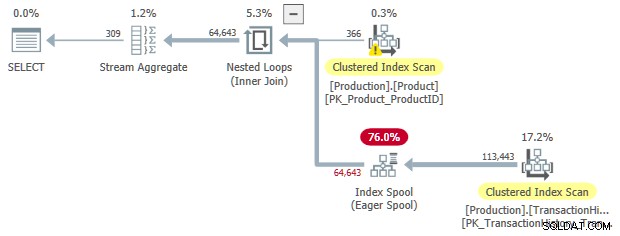
Como antes, podemos solicitar una entrada ordenada al spool:
SELECT
P.ProductID,
P.[Name],
P.SafetyStockLevel,
Quantity = MAX(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
AND TH.Quantity < P.SafetyStockLevel
WHERE
P.[Name] LIKE N'[A-P]%'
GROUP BY
P.ProductID,
P.[Name],
P.SafetyStockLevel
OPTION (LOOP JOIN, QUERYTRACEON 9260);
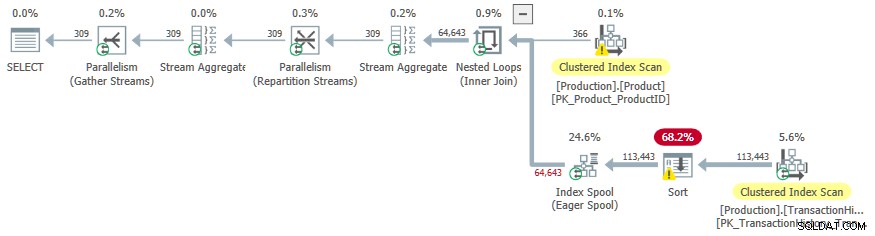
Esta vez, el costo adicional de la clasificación animó al optimizador a elegir un plan paralelo.
Un efecto secundario no deseado es el Ordenar el operador se derrama en tempdb . La concesión de memoria total disponible para ordenar es suficiente, pero se divide uniformemente entre subprocesos paralelos (como de costumbre). Como se indicó en la introducción, SQL Server no admite inserciones paralelas en un índice de árbol b, por lo que los operadores debajo del spool de índice ansioso se ejecutan en un solo subproceso. Este subproceso único solo obtiene una fracción de la concesión de memoria, por lo que Ordenar se derrama a tempdb .
Este efecto secundario es quizás una de las razones por las que el indicador de seguimiento no está documentado ni es compatible.
SelSTVFToIdxOnFly
Esta regla hace lo mismo que SelToIndexOnTheFly , pero para una función con valores de tabla de transmisión (sTVF) fuente de fila. Estos sTVF se utilizan ampliamente internamente para implementar DMV y DMF, entre otras cosas. Aparecen en los planes de ejecución modernos como Función de valores de tabla operadores (originalmente como exploraciones de tablas remotas ).
En el pasado, muchos de estos sTVF no podían aceptar parámetros correlacionados de una aplicación. Podrían aceptar literales, variables y parámetros de módulos, pero no aplicar referencias exteriores. Todavía hay advertencias sobre esto en la documentación, pero ahora están algo desactualizadas.
De todos modos, el punto es que a veces no es posible que SQL Server pase un aplicar referencia externa como parámetro a un sTVF. En esa situación, puede tener sentido materializar parte del resultado de sTVF en un spool de índice ansioso. La regla actual proporciona esa capacidad.
Demostración
El siguiente ejemplo de código muestra una consulta del DMV que se convirtió con éxito de una combinación a una aplicar . Referencias externas se pasan como parámetros al segundo DMV:
-- Transformed to an apply
-- Outer reference passed as a parameter
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id = DES.session_id
OPTION (FORCE ORDER);
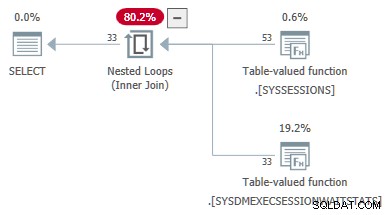
Las propiedades del plan del TVF de estadísticas de espera muestran los parámetros de entrada. El valor del segundo parámetro se proporciona como una referencia externa de las sesiones DMV:
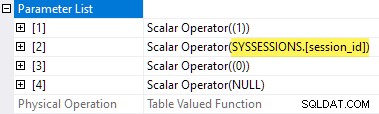
Es una pena que sys.dm_exec_session_wait_stats es una vista, no una función, porque eso nos impide escribir un aplicar directamente.
La reescritura a continuación es suficiente para vencer la conversión interna:
-- Rewrite to avoid TVF parameter trickery
SELECT
DES.session_id,
DES.login_time,
DESWS.waiting_tasks_count
FROM sys.dm_exec_sessions AS DES
JOIN sys.dm_exec_session_wait_stats AS DESWS
ON DESWS.session_id >= DES.session_id
AND DESWS.session_id <= DES.session_id
OPTION (FORCE ORDER);
Con el session_id los predicados ahora no se consumen como parámetros, el SelSTVFToIdxOnFly la regla es libre de convertirlos en un spool de índice ansioso:
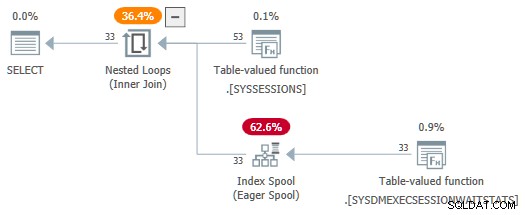
No quiero dejarlo con la impresión de que se necesitan reescrituras complicadas para obtener un spool de índice entusiasta sobre una fuente del DMV; solo hace que la demostración sea más fácil. Si encuentra una consulta con uniones del DMV que produce un plan con un spool ansioso, al menos sabe cómo llegó allí.
No puede crear índices en los DMV, por lo que es posible que deba usar un hash o una combinación de fusión si el plan de ejecución no funciona lo suficientemente bien.
CTE recursivos
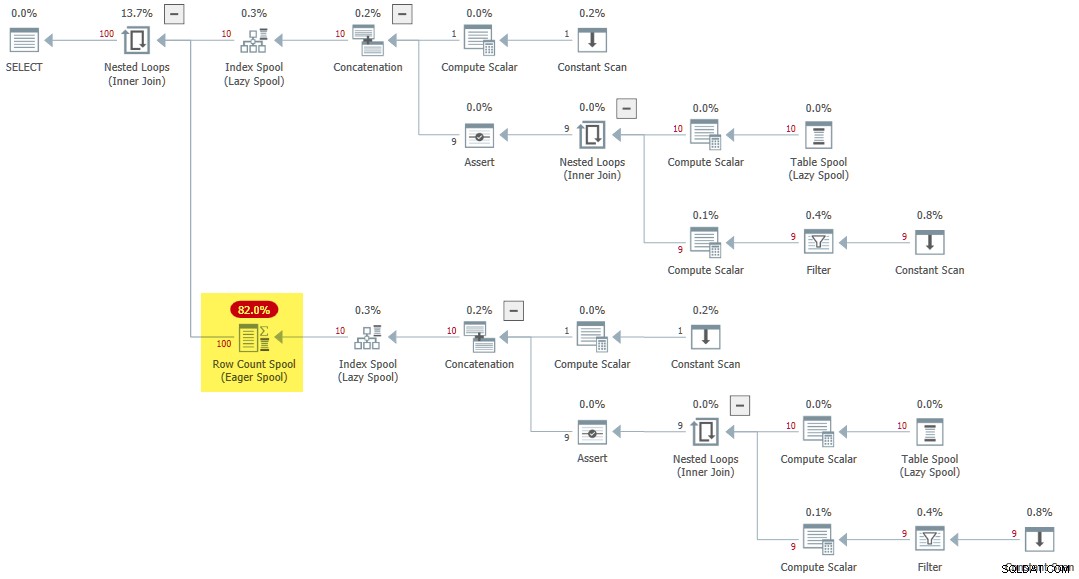
Las dos reglas restantes son SelIterToIdxOnFly y JoinIterToIdxOnFly . Son contrapartes directas de SelToIndexOnTheFly y JoinToIndexOnTheFly para fuentes de datos CTE recursivas. Estos son extremadamente raros en mi experiencia, por lo que no voy a proporcionarles demostraciones. (Solo para que el Iter parte del nombre de la regla tiene sentido:proviene del hecho de que SQL Server implementa la recursividad de cola como iteración anidada).
Cuando se hace referencia a una CTE recursiva varias veces dentro de una aplicación, se aplica una regla diferente (SpoolOnIterator ) puede almacenar en caché el resultado de la CTE:
WITH R AS
(
SELECT 1 AS n
UNION ALL
SELECT R.n + 1
FROM R
WHERE R.n < 10
)
SELECT
R1.n
FROM R AS R1
CROSS JOIN R AS R2; El plan de ejecución presenta un raro Eager Row Count Spool :
Pensamientos finales
Los spools de índice ansiosos son a menudo una señal de que falta un índice permanente útil en el esquema de la base de datos. Este no es siempre el caso, como muestran los ejemplos de funciones con valores de tabla de transmisión.



