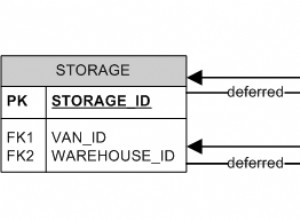
Contenedor de datos extranjeros
Por lo general, las uniones o cualquier tabla derivada de subconsultas o CTE no están disponibles en el servidor externo y deben ejecutarse localmente. Es decir, todas las filas restantes después del simple WHERE La cláusula en su ejemplo debe recuperarse y procesarse localmente como observó.
Si todo lo demás falla, puede ejecutar la subconsulta SELECT id FROM lookup_table WHERE x = 5 y concatenar los resultados en la cadena de consulta.
Más convenientemente, puede automatizar esto con SQL dinámico y EXECUTE en una función PL/pgSQL. Me gusta:
CREATE OR REPLACE FUNCTION my_func(_c1 int, _l_id int)
RETURNS TABLE(id int, c1 int, c2 int, c3 int) AS
$func$
BEGIN
RETURN QUERY EXECUTE
'SELECT id,c1,c2,c3 FROM big_table
WHERE c1 = $1
AND id = ANY ($2)'
USING _c1
, ARRAY(SELECT l.id FROM lookup_table l WHERE l.x = _l_id);
END
$func$ LANGUAGE plpgsql;
Relacionado:
- Nombre de tabla como parámetro de función de PostgreSQL
O prueba esta búsqueda en SO.
O puede usar el meta-comando \gexec en psql. Ver:
- Filtrar los nombres de las columnas de la tabla existente para la instrucción SQL DDL
O esto podría funcionar: (El comentario dice que no funciona .)
SELECT id,c1,c2,c3
FROM big_table
WHERE c1 = 2
AND id = ANY (ARRAY(SELECT id FROM lookup_table WHERE x = 5));
Probando localmente, obtengo un plan de consulta como este:
Index Scan using big_table_idx on big_table (cost= ...)
Index Cond: (id = ANY ($0))
Filter: (c1 = 2)
InitPlan 1 (returns $0)
-> Seq Scan on lookup_table (cost= ...)
Filter: (x = 5) Énfasis en negrita mío.
El parámetro $0 en el plan inspira esperanza. La matriz generada podría ser algo que Postgres pueda transmitir para usarse de forma remota. No veo un plan similar con ninguno de sus otros intentos o algunos más que probé yo mismo. ¿Puedes probar con tu fdw?
Pregunta relacionada con postgres_fdw :
- postgres_fdw:¿es posible enviar datos a un servidor externo para unirse?
Técnica general en SQL
Esa es una historia diferente. Solo usa un CTE. Pero no espero que eso ayude con el FDW.
WITH cte AS (SELECT id FROM lookup_table WHERE x = 5)
SELECT id,c1,c2,c3
FROM big_table b
JOIN cte USING (id)
WHERE b.c1 = 2;
Puede anular esa decisión especificando MATERIALIZED para forzar el cálculo separado de la consulta WITH
Entonces:
WITH cte AS MATERIALIZED (SELECT id FROM lookup_table WHERE x = 5)
...
Por lo general, nada de esto debería ser necesario si su servidor de base de datos está configurado correctamente y las estadísticas de columna están actualizadas. Pero hay casos de esquina con distribución desigual de datos...