Hace un par de semanas se revelaron dos vulnerabilidades de seguridad graves (nombre en código Meltdown y Spectre). Las pruebas iniciales sugirieron que el impacto en el rendimiento de las mitigaciones (agregadas en el kernel) podría ser de hasta ~30 % para algunas cargas de trabajo, según la tasa de llamadas al sistema.
Esas primeras estimaciones tenían que hacerse rápidamente y, por lo tanto, se basaron en cantidades limitadas de pruebas. Además, las correcciones en el kernel evolucionaron y mejoraron con el tiempo, y ahora también tenemos retpoline que debería abordar Spectre v2. Esta publicación presenta datos de pruebas más exhaustivas y, con suerte, brinda estimaciones más confiables para las cargas de trabajo típicas de PostgreSQL.
En comparación con la evaluación inicial de las correcciones de Meltdown que Simon publicó el 10 de enero, los datos presentados en esta publicación son más detallados, pero en general, los resultados de las coincidencias se presentan en esa publicación.
Esta publicación se centra en las cargas de trabajo de PostgreSQL y, si bien puede ser útil para otros sistemas con altas tasas de cambio de contexto/llamadas al sistema, ciertamente no es de alguna manera universalmente aplicable. Si está interesado en una explicación más general de las vulnerabilidades y la evaluación del impacto, Brendan Gregg publicó hace un par de días un excelente artículo de KPTI/KAISER Meltdown Initial Performance Regressions. De hecho, podría ser útil leerlo primero y luego continuar con esta publicación.
¿Qué pruebas haremos?
Veremos dos tipos de carga de trabajo básicos habituales:OLTP (transacciones pequeñas y simples) y OLAP (consultas complejas que procesan grandes cantidades de datos). La mayoría de los sistemas PostgreSQL se pueden modelar como una combinación de estos dos tipos de cargas de trabajo.
Para OLTP usamos pgbench, una conocida herramienta de evaluación comparativa proporcionada con PostgreSQL. Probamos ambos en solo lectura (-S ) y lectura-escritura (-N ), con tres escalas diferentes:encajar en shared_buffers, en RAM y más grande que RAM.
Para el caso de OLAP, usamos el punto de referencia dbt-3, que está bastante cerca de TPC-H, con dos tamaños de datos diferentes:10 GB que cabe en la RAM y 50 GB que es más grande que la RAM (teniendo en cuenta los índices, etc.).
Todos los números presentados provienen de un servidor con 2x Xeon E5-2620v4, 64GB de RAM e Intel SSD 750 (400GB). El sistema estaba ejecutando Gentoo con kernel 4.15.3, compilado con GCC 7.3 (necesario para habilitar el retpoline completo arreglar). Las mismas pruebas también se realizaron en un sistema más antiguo/más pequeño con CPU i5-2500k, 8 GB de RAM y 6 SSD Intel S3700 (en RAID-0). Pero el comportamiento y las conclusiones son más o menos las mismas, por lo que no presentaremos los datos aquí.
Como de costumbre, los scripts/resultados completos para ambos sistemas están disponibles en github.
Esta publicación trata sobre el impacto en el rendimiento de la mitigación, así que no nos centremos en números absolutos y, en su lugar, observemos el rendimiento en relación con el sistema sin parches (sin las mitigaciones del kernel). Todos los gráficos de la sección OLTP muestran
(throughput with patches) / (throughput without patches)
Esperamos números entre 0 % y 100 %, siendo mejores los valores más altos (menor impacto de las mitigaciones), 100 % significa "sin impacto".
OLTP / solo lectura
Primero, veamos los resultados para pgbench de solo lectura, ejecutado por este comando
pgbench -n -c 16 -j 16 -S -T 1800 test
e ilustrado por el siguiente cuadro:
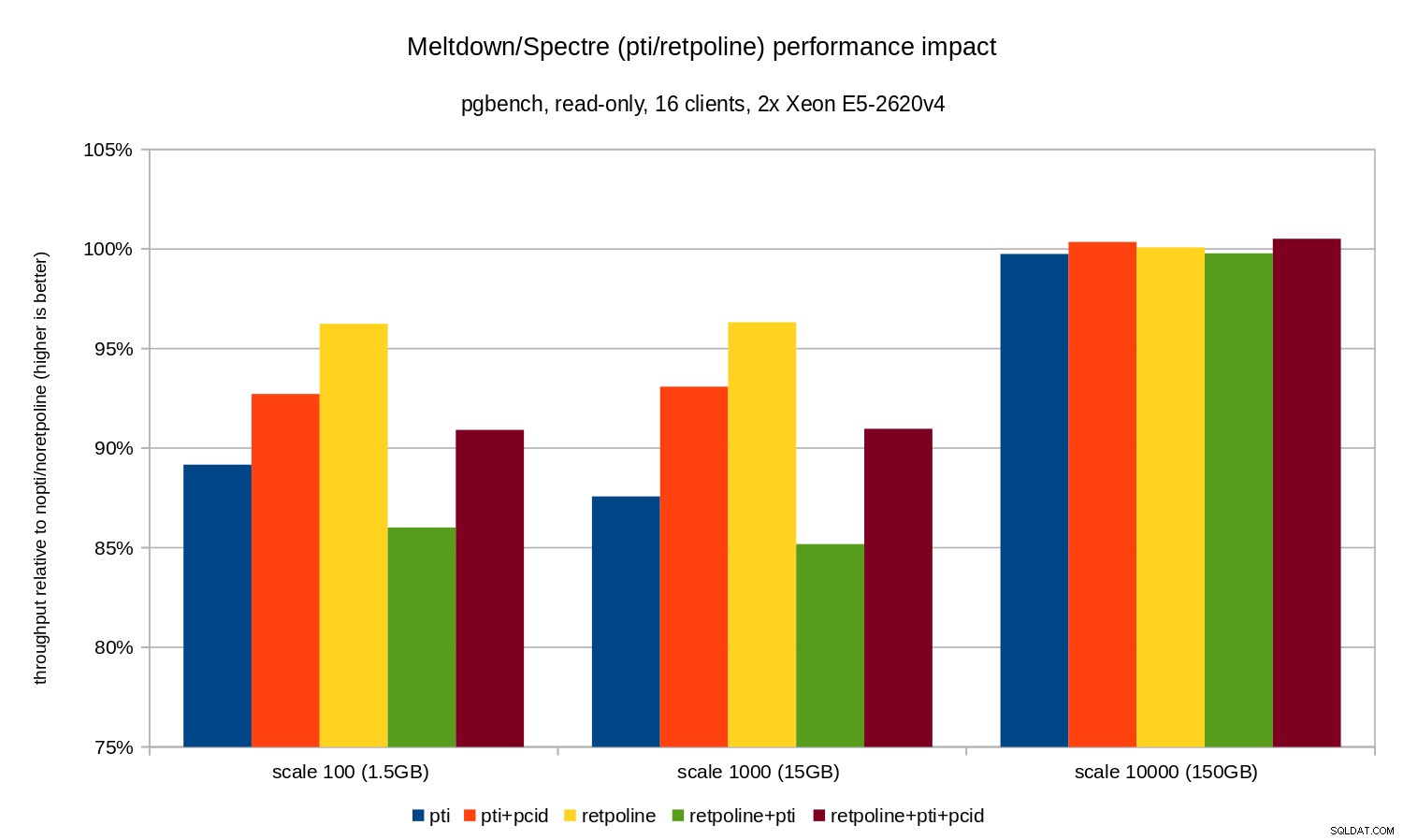
Como puede ver, el impacto en el rendimiento de pti para las escalas que caben en la memoria es aproximadamente del 10 al 12 % y casi no se puede medir cuando la carga de trabajo se limita a E/S. Además, la regresión se reduce significativamente (o desaparece por completo) cuando pcid está habilitado. Esto es consistente con la afirmación de que PCID ahora es una característica crítica de rendimiento/seguridad en x86. El impacto de retpoline es mucho menor:menos del 4 % en el peor de los casos, lo que puede deberse fácilmente al ruido.
OLTP/lectura-escritura
Las pruebas de lectura y escritura fueron realizadas por un pgbench comando similar a este:
pgbench -n -c 16 -j 16 -N -T 3600 test
La duración fue lo suficientemente larga para cubrir varios puntos de control y -N se utilizó para eliminar la contención de bloqueo en las filas de la (pequeña) tabla de ramas. El rendimiento relativo se ilustra en este gráfico:
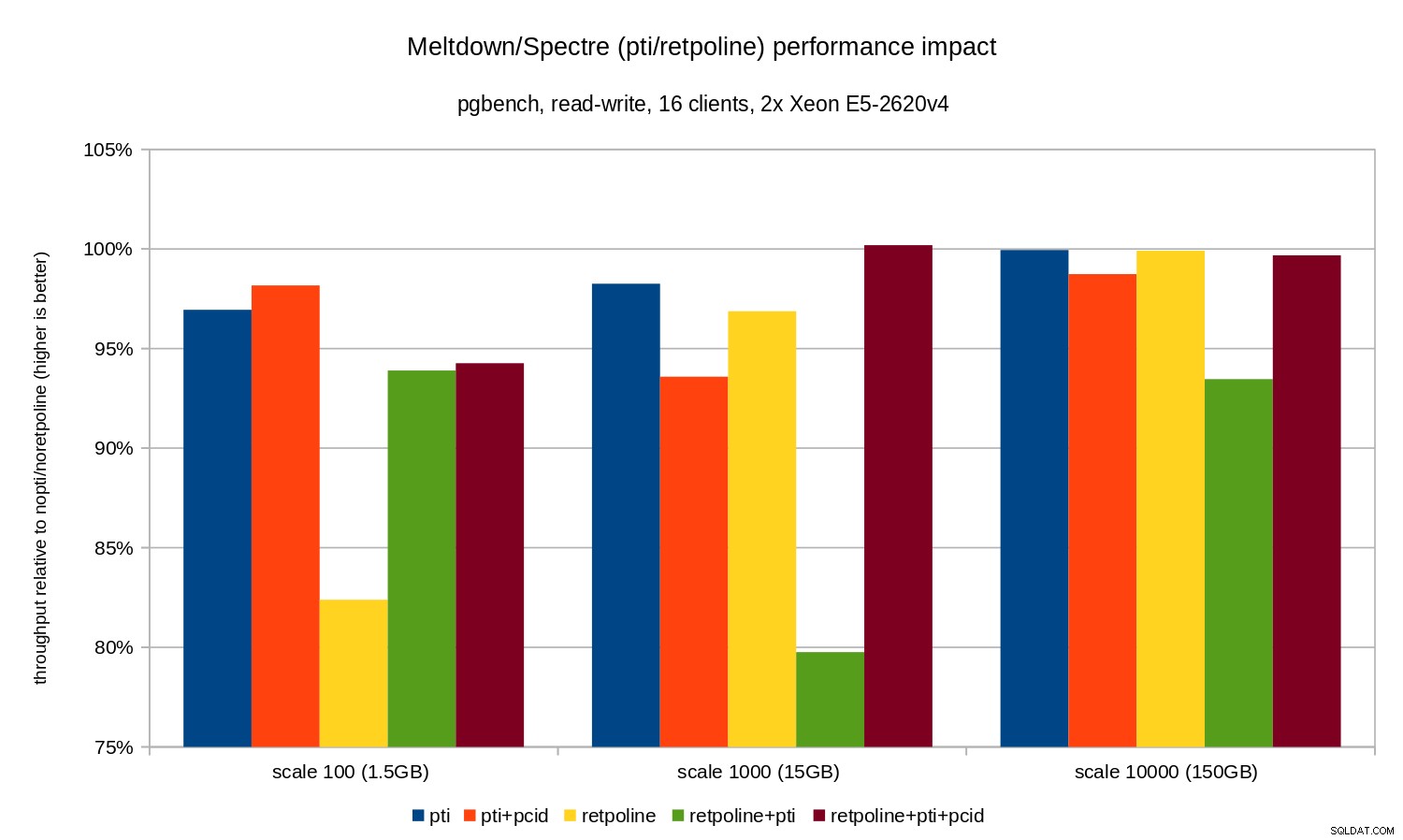
Las regresiones son un poco más pequeñas que en el caso de solo lectura:menos del 8 % sin pcid y menos del 3% con pcid activado. Esta es una consecuencia natural de pasar más tiempo realizando E/S mientras se escriben datos en WAL, se vacían los búferes modificados durante el punto de control, etc.
Sin embargo, hay dos partes extrañas. En primer lugar, el impacto de retpoline es inesperadamente grande (cerca del 20 %) para la escala 100, y lo mismo sucedió para retpoline+pti en la escala 1000. Las razones no están del todo claras y requerirán una investigación adicional.
OLAP
La carga de trabajo de análisis fue modelada por el punto de referencia dbt-3. Primero, veamos los resultados de la escala de 10 GB, que encaja completamente en la RAM (incluidos todos los índices, etc.). De manera similar a OLTP, no estamos realmente interesados en números absolutos, que en este caso serían la duración de las consultas individuales. En su lugar, veremos la desaceleración en comparación con nopti/noretpoline , es decir:
(duration without patches) / (duration with patches)
Suponiendo que las mitigaciones resulten en una desaceleración, obtendremos valores entre 0 % y 100 %, donde 100 % significa “sin impacto”. Los resultados se ven así:
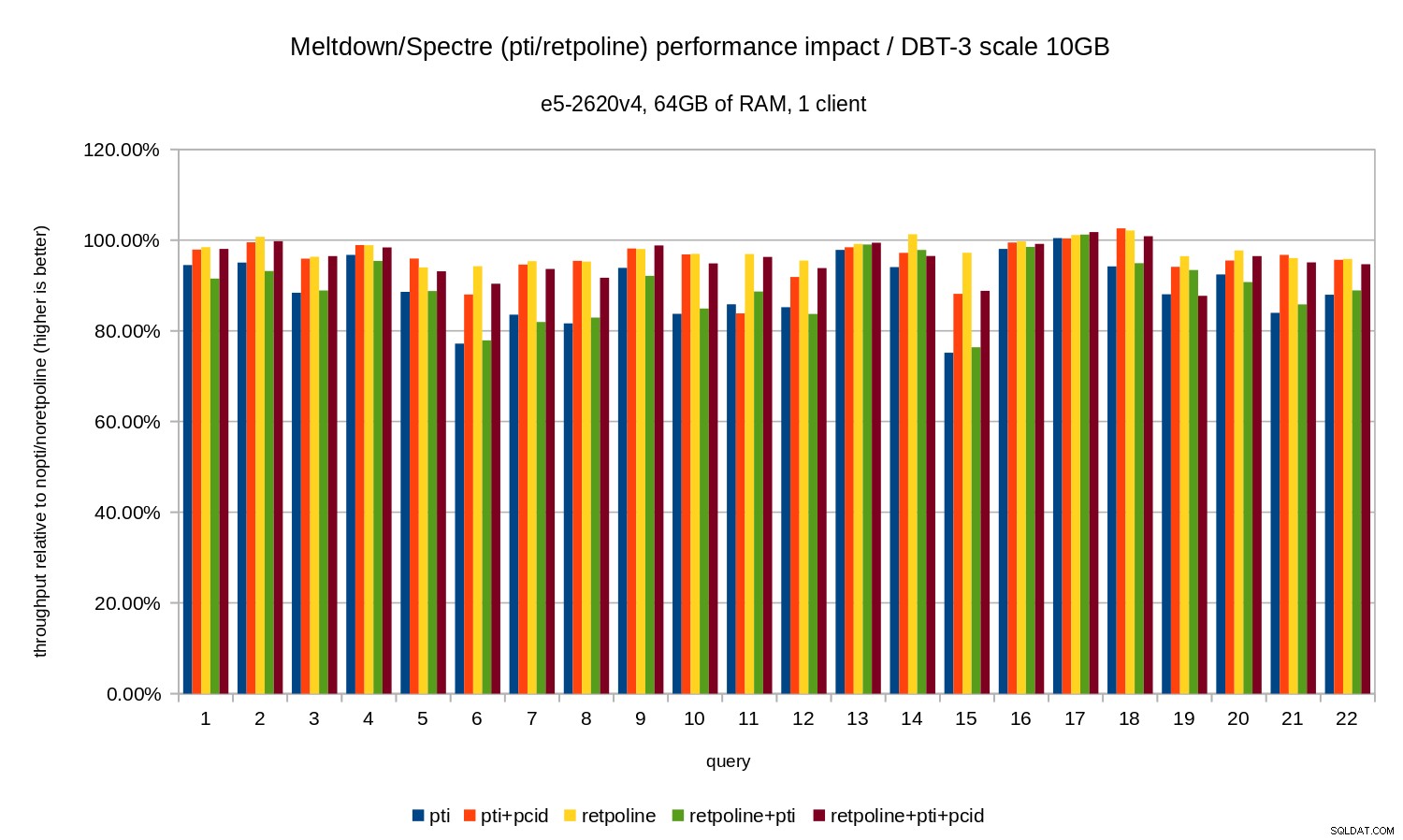
Es decir, sin el pcid la regresión generalmente está en el rango de 10-20%, según la consulta. Y con pcid la regresión cae a menos del 5% (y generalmente cerca del 0%). Una vez más, esto confirma la importancia de pcid función.
Para el conjunto de datos de 50 GB (que es de aproximadamente 120 GB con todos los índices, etc.), el impacto se ve así:
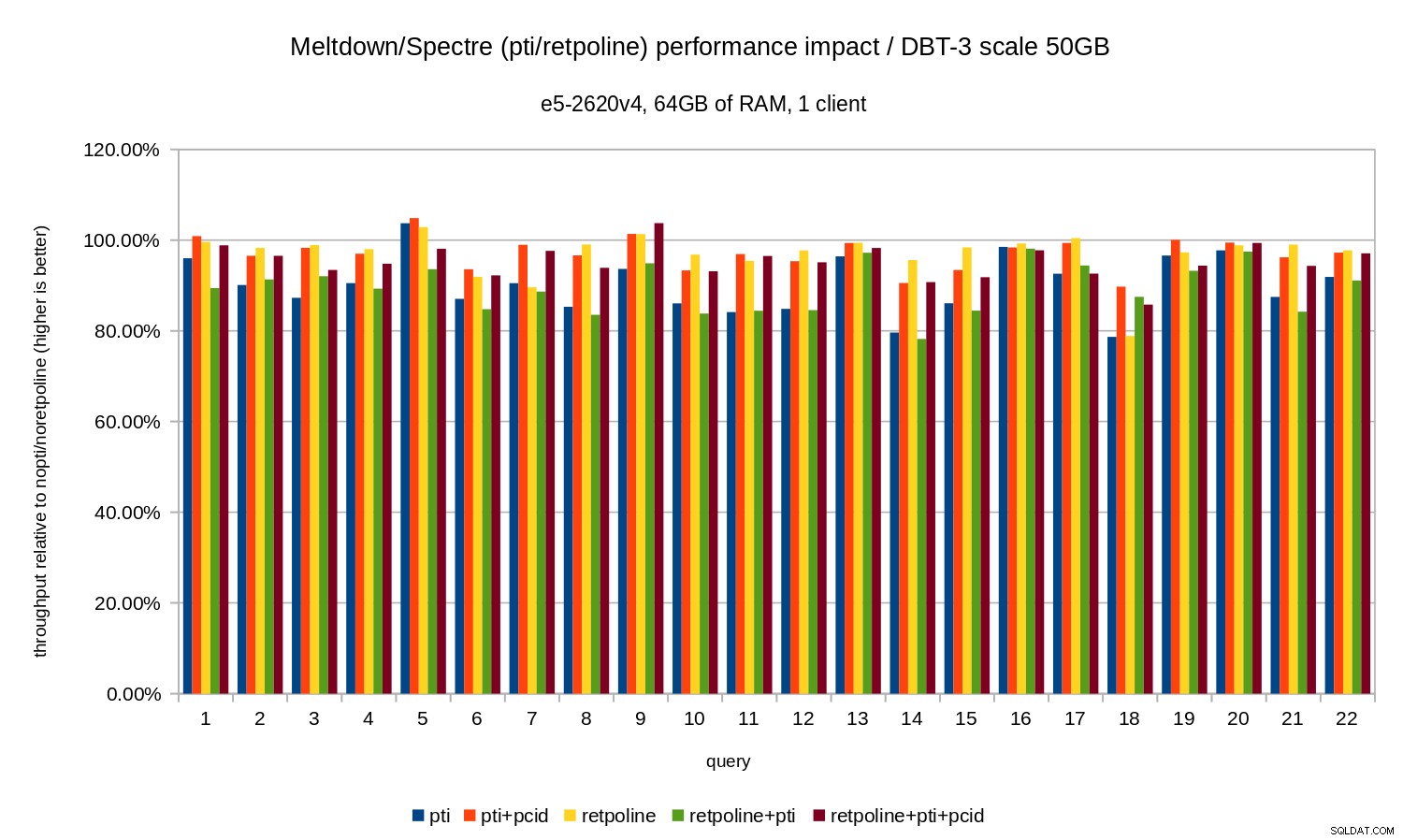
Entonces, al igual que en el caso de 10 GB, las regresiones están por debajo del 20 % y pcid los reduce significativamente, cerca del 0 % en la mayoría de los casos.
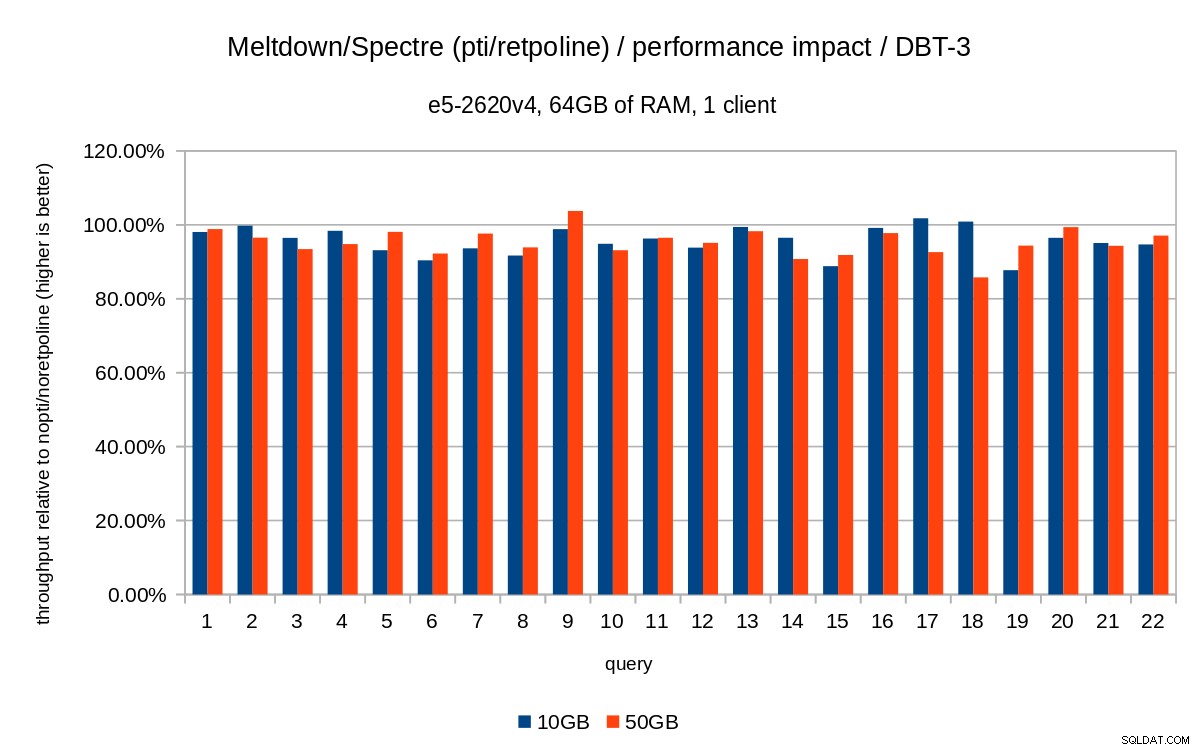
Los gráficos anteriores están un poco desordenados:hay 22 consultas y 5 series de datos, lo que es demasiado para un solo gráfico. Así que aquí hay un gráfico que muestra el impacto solo para las tres funciones (pti , pcid y retpoline ), para ambos tamaños de conjuntos de datos.
Conclusión
Para resumir brevemente los resultados:
retpolinetiene muy poco impacto en el rendimiento- OLTP:la regresión es aproximadamente del 10 al 15 % sin el
pcid, y alrededor del 1-5 % conpcid. - OLAP:la regresión es de hasta un 20 % sin el
pcid, y alrededor del 1-5 % conpcid. - Para cargas de trabajo vinculadas a E/S (por ejemplo, OLTP con el conjunto de datos más grande), Meltdown tiene un impacto insignificante.
El impacto parece ser mucho menor de lo que sugieren las estimaciones iniciales (30 %), al menos para las cargas de trabajo probadas. Muchos sistemas funcionan con un 70-80 % de la CPU en los períodos pico, y el 30 % saturaría por completo la capacidad de la CPU. Pero en la práctica el impacto parece estar por debajo del 5%, al menos cuando el pcid se utiliza la opción.
No me malinterpreten, la caída del 5% sigue siendo una regresión grave. Ciertamente es algo que nos importaría durante el desarrollo de PostgreSQL, p. al evaluar el impacto de los parches propuestos. Pero es algo que los sistemas existentes deberían manejar bien:si un aumento del 5 % en la utilización de la CPU lleva a su sistema al límite, tendrá problemas incluso sin Meltdown/Spectre.
Claramente, este no es el final de las correcciones de Meltdown/Spectre. Los desarrolladores del kernel todavía están trabajando para mejorar las protecciones y agregar otras nuevas, e Intel y otros fabricantes de CPU están trabajando en las actualizaciones de microcódigos. Y no es que conozcamos todas las variantes posibles de las vulnerabilidades, ya que los investigadores lograron encontrar nuevas variantes de los ataques.
Así que hay más por venir y será interesante ver cuál será el impacto en el rendimiento.