¡Feliz cumpleaños Apache HBase! 10 años de resiliencia, estabilidad y rendimiento
Apache Spark llega a Apache HBase con el módulo HBase-Spark
Procedimiento:indexar archivos PDF escaneados a escala con menos de 50 líneas de código
Spark-on-HBase:conector HBase basado en DataFrame
Conector Spark HBase:un año en revisión
Presentamos las políticas de partición de compactación de almacenamiento de objetos medianos (MOB) de Apache HBase
Compare Apache HBase frente a Apache Cassandra en SSD en un entorno de nube
Serialización robusta de mensajes en Apache Kafka con Apache Avro, parte 1
Almacenamiento de datos de última generación en Santander Reino Unido
Motores de procesamiento de Big Data:¿cuál debo usar?:Parte 1
Versión CDH 6.2:Novedades en HBase
Procedimiento:usar la interfaz HBase Thrift, parte 2:insertar/obtener filas
¿Qué son las compactaciones HBase?
HBase BlockCache 101
HBase y Hive:mejor juntos
Ajuste de la recolección de basura de Java para HBase
Dentro de la arquitectura de ingesta de datos casi en tiempo real de Santander (parte 2)
Patrones arquitectónicos para el procesamiento de datos casi en tiempo real con Apache Hadoop
Dentro del nuevo soporte de Apache HBase para MOB
Procedimiento:escanear tablas HBase de Apache saladas con intervalos de claves específicos de la región en MapReduce

Cómo restaurar una colección específica en MongoDB usando la copia de seguridad lógica
MongoDB
¿Cómo probar las actualizaciones de su aplicación MongoDB?
MongoDB
ClusterControl:todas las funciones destacadas y mejoras de 2017
MongoDB
Replicación de bases de datos operativas de Cloudera en pocas palabras
HBase
Convierta la consulta de MongoDB en la sintaxis de Spring MongoDB
MongoDB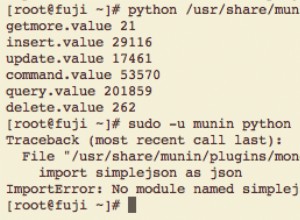
El complemento Munin Mongodb no se muestra. . .?
MongoDB